符号的那些问题
作者: | 更新日期:
遇到一个编译器符号的问题,啰嗦几句。
本文首发于公众号:天空的代码世界,微信号:tiankonguse

一、背景
这是一个计算机相关的技术文章。
非程序员可以走了。
好久没有写技术文章了。
之前我手上负责的有一个很老的系统,大概是微博年代的,后来视频复用了这套系统。
这个系统有三四年没更新过了,最近由于业务需求,需要增加一个功能。
我大概梳理了系统的架构,编写出了新的服务,搭建了测试环境并测试通过,发布时却遇到了服务起不来的问题。
本能告诉我是系统版本太低,编译服务器版本太高,不兼容导致的。
说起编译器,不管是在网上还是内部,大家经常会说到一句话:腾讯的技术不行了,至少支持一下c11也行呀,永远都是c98。
看到这句话我笑了。
这个不是一个编译器的问题,这个是背后千千万万服务器的问题。
编译器升级了,编译出的程序在千千万万的古老服务器上跑不起来不是白搭,或者想让跑起来也可以,需要付出很高的成本。
所以那些人想法还是太简单,很多事情并不是我们看到的表面现象:不就是XX吗?多简单。
当然,如果你已经看透了一切,然后再说出这些,那你就不简单了。
二、基本信息
这里有三个信息,一个是系统信息,一个是glic信息,一个是gcc信息。
当然gcc信息可以忽略,那个编译时才需要,所以非编译机这个信息可能不准。
编译机系统版本是3.10, 服务器系统版本是2.6。
编译机glic版本是2.12,服务器系统版本是2.4。
编译机gcc版本是4.4,服务器系统版本是2.95。
说到版本号,其实这里有个潜规则的。
版本号一般是三个数字,即x.y.z的格式。
x代表主版本号,用于重大升级,一般不向下兼容。
y代表次版本号,用于功能升级,向下兼容,但是会增加一些新功能。
z代表发布版本号,用于优化升级,向下兼容,代表优化了性能,修复了BUG等等。
这里我把最后的发布版本号隐藏了。
说起版本号,那自然有人问系统是怎么找到自己需要的版本呢?
这个在编译出的程序中,有个叫做.dynamic的段,用来指定需要的库和版本。

三、glibc符号的hash问题
一般服务在低版本系统运行时遇到的第一个问题就是Floating point exception。
不过作为老司机,这个问题在N年前就遇到过了。
我们知道实际上程序里面一切都是符号。
而符号是个字符串,这在查找符号时就会是一个大的性能问题了。
为了解决这个问题,glibc自然使用了hash技术,先将符号hash为一个整数,然后进行链表查找。
以前使用的HASH符号,现在使用了GNU_HASH。
新版本编译不特殊说明,只有GNU_HASH。
所以这种情况的解决方案就是指定使用两种hash技术。
编译参数就是-Wl,--hash-style=both。
四、找不到符号
另一个问题不好描述,因为触发这个问题的条件比较多。
首先需要有一个静态库,然后有一个inline函数,里面有个static变量。
满足这三个条件时,静态库inline函数里面的静态变量的符号就有问题了,旧系统会找不到符号。
要解释这个问题,需要知道ELF的背景知识。
五、ELF格式基础知识
现在linux下和windows下的可执行文件都是使用COFF格式实现的。
不过由于都是COFF的子集,还是互相不兼容的。
windows的格式称为PE格式,linux的称为ELF格式。
平常遇到的.o目标文件、.a静态库、.so动态库都是ELF格式。
ELF格式的文件是以段的形式储存的。
我们的源代码编译后的指令一般储存在代码段,名字一般是.text或.code。
全局变量和局部静态变量储存在数据段,名字一般是.data。
未初始化的全局变量和局部静态变量,会储存在.bss段,值全是0,不占储存空间。
另外,还有一个.rodata只读段,字符串以及const常量都在这个段里面,从而可以做到运行时不可修改。
其他的段我们不常见,比如.comment编译器信息段,.dynamic动态链接信息,.hash符号哈希表,.symtab符号表,.shstrtab段名表等等。
还有很多其他段,这里就不一一罗列了。
另外就是,我们可以通过objcopy,将图片、音乐、视频等文件信息制作为一个自定义段。
这里有一个小问题。
指令和数据为什么要分开储存呢?
这个大概分三个原因:权限隔离、CPU缓存优化、共享段节省内存。
下面我们分别来看一下这个ELF文件的内容吧。
ELF文件有一个ELF头部,用来描述文件的信息的。
主要有魔数,字长(32位/64位),字节序(大端/小端),文件版本。
还有type,用于区分文件类型,有可重定位、可执行、共享目标文件三类。
除了ELF头部,看到的第一个段就是段表了,它描述了ELF的各个段的信息。
如每个段的段名、段的长度、在文件中的偏移、读写权限以及段的其他属性。
第二个是重定位表了。
多个文件分别编译出了自己的.o文件,这些文件实际上和目标文件已经很接近了。
除了那些依赖的外部符号,其他的都已经正确了,不需要修改了。
而这些外部符号由于还不知道地址,所以只能使用占位符占着,等后面链接了再填充进去。
我们怎么知道哪些符号需要重新填充呢?就是这个重定位表。
第三个是字符串表。
由于段名、变量名的长度都不定,自然就需要一种映射方法,使用定长来标识这些字符串。
最简单的方法就是使用字符串在表中的偏移量来表示。
常见的名字有.strtab和.shstrtab,分别是字符串表和段表字符串表。
sh的 section head的缩写。
第四个表就是符号表.symtab了。
这个表最重要了,因为所有的符号都在这里描述其基本信息。
符号类型比较简单,有NOTYPE未知符号,OBJECT数据对象符号,一般是变量或数据。
还有FUN符号代表函数,SECTION符号代表段,FILE符号代表文件名。
符号绑定信息也很简单,比如LOCAL代表局部符号,GLOBAL代表全局符号,WEAK代表弱引用。
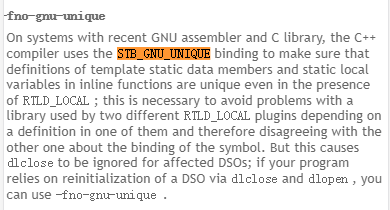
而我那个静态库inline函数是STB_WEAK的,然后里面的静态变量竟然是UNIQUE的,从来没见过。
没见过代表啥呢?代表新版本编译器的功能了。
还是回到符号绑定信息这里。
大家编译代码的时候是不是经常遇到符号重定义的编译问题?
就是这里决定的。
默认函数和初始化的变量都是强符号,未初始化的全局变量为弱符号。
连接器对强符号有一定的规则。
1.不允许强符号多次定义。如果多次定义,链接时报重复定义错误。
2.如果一个符号在某个.o文件是强符号,其他地方时弱符号,链接时选择强符号。
3.如果所有.o文件都是弱符号,选择占用空间最大的那个符号。
有了上面的规则,静态库头文件里实现的函数就尴尬了。
由于很多cpp文件都包含了这个头文件,里面实现的函数就会被编译到多个.o文件去。
从而链接的时候报函数重定位错误。
面对这个问题我们的解决方法是加一个inline关键字。
加了这个关键字后,这个函数就会变成弱引用了。
弱引用后,就允许符号多次定义了,而且即使不定义,也不会报错的。
当然,弱引用后,也可以避免这个函数在目标文件有多份造成代码膨胀。
而对于inline函数的static变量问题,自然就是禁止使用这个特殊的UNIQUE符号。
不幸的是,我的编译器不支持这个禁用功能,可悲,怎么办呢?
三个条件只要有一个不满足,就没这个问题了。
于是我只好重新实现这个函数了就行了。
六、完
关于符号,如果了解了编译链接的细节的话,其实很多问题都可以得到简单的解释。
而如果不了解这些细节,有时候去google都不知道使用什么关键词搜索,真是矛盾呀。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
