浅读腾讯贡献给Linux基金会的TSeer
作者: | 更新日期:
几天前腾讯给Linux基金会贡献的开源项目刷屏了,这里简单看下源码。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
零、背景
6 月 25 日,Linux 基金会集结世界顶级开发者的非营利开源组织,宣布腾讯正式成为 Linux 基金会白金会员。
腾讯表示将向Linux基金会提供其名为TARS的开源微服务项目和一个开源服务项目Tseer。
这里我们先来看看这个Tseer项目吧。
一、由来
Tseer的项目代码地址是https://github.com/Tencent/TSeer
官方介绍为”A high available service discovery & registration & fault-tolerance framework”。
为什么需要Tseer这一类组件呢?
设想你在使用微信和女朋友聊天,发了一句”在吗”。
这条信息是怎么到达你女朋友的手机上呢?
一种想当然的做法是:你的手机把信息发到微信的后台服务器,微信的后台服务器把数据发给你女朋友的手机。
那这里就有个问题:后台服务器挂了怎么办?
自然可以想到后台服务器有很多台,挂一台使用其他的就可以了。
我们怎么知道后台有哪些服务器,以及哪些服务器是可用的呢?
这个就是Tseer这类组件做的事情,这类组件的核心功能就是服务注册与发现功能。
这类组件的实现方式大多类似,都需要下面几个模块。
- api,比如我们的微信客户端,需要调用api发现可用的后台服务器。
- agent,这个大家可能比较陌生,而且有时候不是必须的。agent的功能是提前把后台服务器拉倒本地,这样api可以更快的获得服务器信息。
- 中心服务,api或者agent向这个中心服务发起请求,获得服务器信息。
- 管理台,用于管理一个接口与对应服务器的关系。
- 储存DB,管理台维护的数据需要有地方储存,一般使用数据库储存,数据库检查为DB。
当然,看到这个新闻之前,我从来没听过这个组件,我们这边使用的其他类似的组件,并且不是开源的。
既然这里开源了一个,就快速搭建一个环境体验一下。
二、安装
我去腾讯云买了一台服务器,尝试从0搭建Tseer。
搭建过程中,却发现Tseer这个项目对于初学者成本太高,说是自动化却有没有自动化。
等有时间了我会fork一个分支来,修改成完全自动化的。

按照TSeer的文档, 我操作了一番。
发现这个文档有一个很大的问题。
文档上说已经有自动化脚本了,什么都不需要关系,执行脚本即可。
备注上说如果想要了解详细用法,可以看下一小节。
可是下一小节只有各个模块的配置文件信息,并没有各个模块的安装使用信息。
对于WEB管理台,文档上说没有实现一键安装脚本,于是介绍了详细的安装WEB管理台的文档。
照在管理台的文档,我管理台很快就跑起来了。
而对于自动化安装的其他模块,我执行完后并不可用,看输出的日志全是”Please submit a full bug report”。
于是我只好去研究一下自动化安装工具的代码,看看具体怎么做了什么事情,然后自动动手安装每个模块。
自动化脚本做了这样几件事情。
- 抱团取暖,安装一个广告tars。
- 安装储存etcd
- 安装自家json库rapidjson,这里没有写rapidjson,而是命名为depedency。
- 使用cmake对服务和api编译安装
- 对配置文件的ip和端口进行替换,并尝试启动服务和agent。
cmake编译确实是一个好东西。
14年我在媒资的时候,内部刚好需要进行32位服务迁移64位服务,我和hades一起搭建了一套cmake编译环境。
当时我算是内部第一个吃螃蟹的人了,当时还写了几篇cmake使用文章,当时内部cgi也不支持返回json,也是我提出使用jsonp=0这个参数的。
当然,后来组织架构调整,我们还是转回makefile了。
毕竟我们的项目还没有那么复杂,也不需要跨平台,使用makefile就足够了。
三、api
看一个项目的源码,首先需要知道这个项目是干什么的。
而项目对外提供的api就可以展示自己是做什么的。
所以看一个项目代码时,第一个要开的就是api。
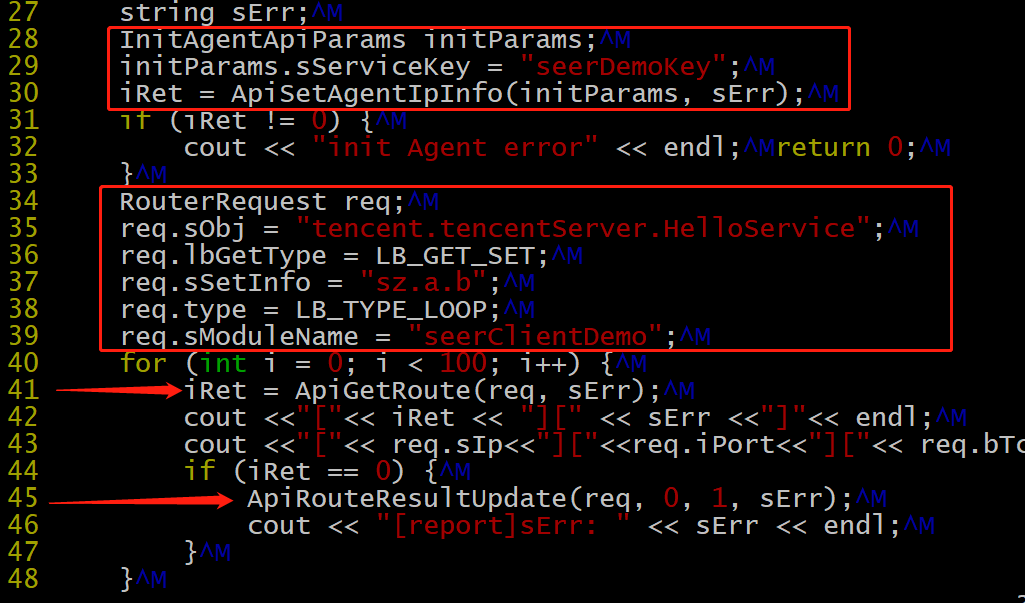
根据截图,可以看到我们api使用很简单(其实那么多参数还是不简单的)。
大概分三步:初始化,拉取服务器信息,上报服务器信息。
不过这里有几个不好的地方。
第一点是初始化和拉取服务器信息,竟然需要传两个参数。其实那个参数完全可以对用户隐藏起来。
第二点是拉取服务器信息时,穿的参数太多,这个可以简单化点,多了对使用者的理解成本就好了,错误使用的概率就高了。
第三点是进行服务信息上报时,那几个数字没人知道什么意思了,如果能定义成变量就好了。哪两个数字的含义其实是错误码和耗时。
最后一点就是api的代码了,以c语言的形式,重复代码太多了,一点都不优雅。
api是支持本地agent和远程server的。
所以这里封装了一下,agent走轻量级的UDP,远程走可靠的TCP,剩下拿到数据的逻辑就完全一样了。
当然为了高性能,api肯定会在进程缓存者数据,每秒回源一次,这个时间间隔代码是写死的。
另外为了防止本地agent挂了或者远程server挂了,api会独立做一个磁盘缓存。
对于磁盘操作,这里其实有个问题,不是进程安全的,也不是线程安全的。
api还支持多种负载均衡策略的。
- 轮循:权重相同,循环选择使用。
- 随机:随机函数选择使用。
- 静态权重:这个是目前我工作中常使用的,每个ip可以配置一个权重,按权重分配。
- 一致性哈希:这个我也使用过,按权重建一个hash环,从而做到指定KEY的固定路由。
- 获取所有节点:这个就不存在负载均衡了,直接返回所有ip列表。
四、agent
想要知道agent存在的目的,就需要看看直接从远程服务拉数据有啥弊端。
在api小节中可以看到路由信息是每秒回源一次的,那假设远程服务器通信一次需要20ms, 那每秒就会有一次抖动,被这个api消耗20ms。
这个20ms对很多服务是不可接受的,所以需要降低这个时间。
怎么降低呢,直接从本地agent读数据,单机内通信,网络延时就可以忽略,这样即使回源也可以在2ms内完成了。
知道了agent存在的目的,那agent做了哪些事情就一目了然了。
至少有从远程server定时回源数据,给本地服务提供服务两个功能。
agent服务是使用tars网络框架实现的,怪不得安装的时候需要下载tars的源码呢。
这里我们暂时不去看tars的源码,只需要知道tars是一个网络框架就行了。
网络框架一般把网络操作都封装好了,我们只需要实现具体的业务逻辑就行了。
比如对于这个agent,第一件事是给使用本地api的项目提供服务。
如果agent的数据过期了,还需要去远程中心回源新数据。
除了api被动回源数据,还可以开一个线程定时回源全部数据。
另外,一般agent需要和中心进行心跳保持,这样中心就可以实时监控agent机器的信息。
最后一个功能是最牛逼的地方,需要自动更新。
当然,这个agent代码有很多冗余的地方,比如把api实现的调度算法全部实现了,实际上并用不到。
五、server与管理台
server中心做的事情根据使用也可以推断出来。
面向服务是回源数据、心跳、自动更新。
而面向管理台,是更新维护业务与机器的路由列表、更新agent脚本以及查看各agent的状态。
这里数据默认使用etcd储存的,etcd可以理解为是一个支持http协议的kv数据库。
而管理台是使用java实现的,实现方式是典型的MVP模式。
由于各种业务操作都在服务上实现,所以管理台的java代码只是承担协议转换的角色。
由于这个组件的核心就是路由发现,所以对于的核心自然就在api上实现了,其他模块相对来说都简单多了,代码都很短,感兴趣的可以看一看。
六、最后
快速看完TSeer的代码,我的感受是这明显是抄袭内部的XXX组件。
后来一想,可能对外开源换了一个名字,其实就是一个东西。
于是我赶紧找来XXX组件源码翻一下,发现确实差不多,函数名,实现方法完全一样。
原来之前一直没来得及看的XXX组件这次趁着开源给看了,尴尬。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
