KAFKA 遇到 TCP 之 认识 TCP
作者: | 更新日期:
如何保障数据流高速可靠传输,一直都是一个问题。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
零、背景
最近在做一个kafka相关项目时,遇到一个悖论问题:业务即想要数据有序,又想要高性能,还想要高可靠。
这个初步看显然不可能。
有序就要一个一个发,而且只能上个包正常返回时才能发下一个。
这样算下来,假设数据一次来回是 20ms ,那每秒处理了就是 50个。
在这样的背景下,我初步实现了相关项目代码。
实现代码与测试代码的过程中,我对 kafka 理解越来越深了,对这个问题理解也越来越深了。
静下来想了想,大部分情况下,想要同时满足数据有序、高可靠、高性能也是有可能的,只是实现复杂了点。
在和 vic 讨论相关实现的时候,发现 我的项目的实现其实就是 TCP 发送数据的过程,而且而这个还可能比 TCP 的某些情况复杂一些。
有序的 kafka 消息其实就是 有序的 TCP 数据流,最终目的都是要客户端可靠的快速的收到有序的数据。
在传递过程中,发送的某个数据包都可能失败,此时需要进行重传。
由于网络或者客户端可能处理不过来,发送端还要考虑流量控制。
恩,现在看看,是要在应用层实现一个比 TCP 还复杂的数据传递应用了。
假设我直接说我的项目,由于大家没有真实面临这个问题,既有可能感受不到问题的复杂性。
因为我之前分享过《静态库遇到静态库》系列,结果即使现在 99% 的人也不知道我说的问题是什么。
所以这次先来看看 TCP,看看 TCP 在传递数据的时候面临了什么问题,最终又是怎么解决的。
TCP的问题虽然大家还是没有真正遇到过(TCP底层已经几乎都解决了),但是毕竟大家都听过。所以说TCP的时候大家更有感觉,也知道我在说什么。
一、TCP 概览
TCP 是一个复杂的协议,因为它要解决很多问题,然而引入一个方案来解决这个问题时,又会带来很多子问题。
所以 TCP 发展这么多年后,变得非常庞大、复杂、冗余。
如果沉下心来完整的学习一下 TCP 协议,我们也可以收获很多东西。
在大学的时候(2012年或2013年),我们的课程教材是《TCP/IP 详解 卷1:协议》,我当时感觉这本书很有意思,把 TCP 相关的内容翻了很多遍。
毕业的时候,一个同学说自己没教材,以后做网络相关的,可能会用到这本书的知识,问我能不能送给他。我就随手送给他了。
现在想看的时候才记起这个事情,刚才去京东上看了下,这么多年了,还是没降价,快一百大洋一本。
这个文章主要来表达数据流在传输面临的问题,我就不去讲解 TCP 的状态了。
三、TCP 乱序问题
我们知道服务端给客户端传数据的时候,客户端需要给服务端发送 ACK 确认包。
例如
服务端:给第一个数据包(DATA 1)。
客户端:收到第一个数据包了(ACK 1)。
服务端:给第二个数据包(DATA 2)。
...
服务端:这么久了,还没回ACK呢,再发一次,给第二个数据包(DATA 2)
客户端:给第二个数据包(ACK 2)
客户端:给第二个数据包(ACK2)
可以看到,数据包有可能丢失,此时服务端需要进行重传。
另外由于数据有可能会被拆分成很小的片段,这个 ACK 就变得复杂了。
不能简单的使用第几个数据包了,只能使用第几个字节的数据了。
例如
服务端:给以seq 101开始长度为 10的数据包
客户端:收到seq 110之前的包了(包括110)。
服务端:给以seq 111 开始长度为30的数据包。
...
客户端:奇怪,怎么来了一个 seq 121开始长度为10的数据包?
客户端:奇怪,怎么来了一个 seq 131开始长度为10的数据包?
客户端:终于收到 seq 111开始的数据包了,长度为10,需要回ACK 120。
客户端:不对。seq 121开始的数据包我好像收到过,需要回ACK 130才对。
客户端:还不对。seq 131开始的数据包我也收到过,需要回ACK 140才对。
这里可以发现,每次会的ACK回的是最大连续数据的偏移量。
由于各种原因,TCP的实际情况回的ACK是最大连续数据偏移量加一。
从上面的例子上还可以看出来,TCP的客户端需要维护哪些数据包已经收到了。
这个维护就需要成本了,比如需要使用链表维护有序数据。
链表的复杂度是O(n)的,不可接收,所以 TCP 内部使用红黑树来维护这个有序数据。
上面是站在客户端接收数据的角度来看乱序问题的。
站在服务端发送数据的角度,会发现问题很简单:只需要从最小的ACK 开始发送数据即可。
但是,从最小的ACK发数据很容易发现,之后可能某个包丢了,之后的包客户端即使收到了,也会被重传。
这就造成了网络上传了大量的无效包,浪费流量带宽。
于是 TCP 增加了 SACK的功能,即回复一个ACK区间,代表这个区间的数据收到了,不需要再发送了。
这样,服务端也需要维护一个链表,来标示哪些数据已经发送了,哪些还没有发送。
是的,这些也是使用红黑树来维护的,直接使用链表复杂度是不能接受的。
四、TCP 丢包问题
前面讨论的是乱序问题,接下来就是发送端的速度问题了。
发送端该以怎么样的速度来发送数据呢?
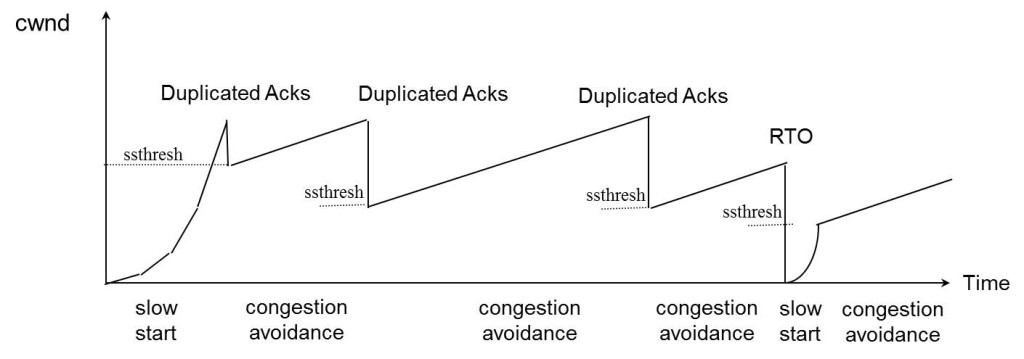
了解 TCP 的人会马上说,慢启动、拥塞避免、快速恢复什么的。
是的,这些都是TCP根据自己已有的信息,来实现的算法。
先来看看服务端能收集到哪些信息吧。
假设正常通行的话,服务端可以知道通信的来回延时,称为RTT。
是的,服务端只能收集这样一个信息。
异常通信时,服务端可以知道客户端迟迟没有会ACK,此时根据正常情况的RTT是不好判断异常情况该如何发送数据的。
所以,这个只能依靠算法来探测。
经典的探测策略是慢启动算法。
刚开始传的数据小点,为1(还记得上面举例时有个数据长度吗),正常收到数据了,数据长度就加1。
由于数据的长度是从1开始的,这样就长的太慢了,于是就加了第二个策略:过一个RTT,数据长度就翻倍。
翻倍是一个很恐怖的策略,所以这里还设置了一个上线,到达上限是就不再翻倍了。
翻倍的上限一般是 65536,当到达这个值后,就使用一些较慢的策略来增。
当发生超时未收到ACK时,我们就认为丢包了。
此时就需要紧急控制,也就是长度马上变为1,然后进入慢启动算法。
当然,现在的算法优化的更高级了。
丢包时不会马上把长度置为1,而是长度减半的,然后进入快速恢复算法。
为什么要进入快速恢复算法呢?
因为之前已经传了那么多包了,已经收集了很多信息了,比如正常传输数据的长度上限。
通过之前收集的信息,TCP也就恢复的更快了。
五、最后
TCP 的乱序与丢包问题已经看完了,算是复习了一下大学的知识。 下篇文章就好理解我描述的问题了。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
