一致性HASH数据更新的困境
作者: | 更新日期:
之前聊过《一致性HASH技术的困境》,今天来看看另一个问题:数据更新问题。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
一、背景
之前曾写过一篇《一致性HASH技术的困境》,主要讨论请求量过大与请求量不均衡带来的问题。
实际上,一致性HASH用在缓存系统还有另外一个必然面临的问题:数据更新问题。
这里来和大家一起讨论下一致性HASH数据更新时面临的困境。
二、MYSQL 到 NOSQL
对于比较小的项目,访问量比较小,可以直接读写一个 MYSQL DB 。
访问量大了的时候,就进行拆分DB、读写分离、硬件升级等等短期优化。
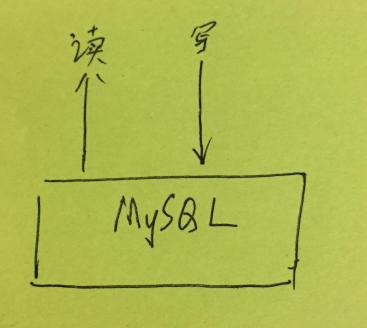
此时数据的一致性由 MYSQL 内部保障(主从之间的一致性),我们不需要关心数据一致性问题。
但是这些优化提高的性能非常有限。
如果要支撑更大的访问量,就需要调整架构,引入 NOSQL 了。
引入了 NOSQL 后,储存的数据就有两份,从而面临数据一致性问题。
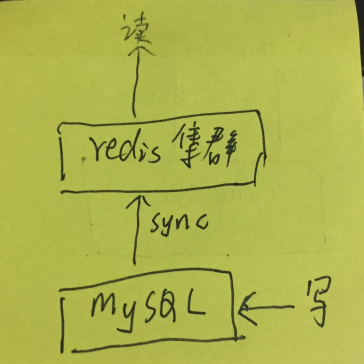
如果 NOSQL 是 REDIS 集群这样的成熟组件,写操作只写 MYSQL。然后有专门的组件将数据同步到 REDIS ,REDIS 储存全量的数据,则业务也不会涉及数据一致性问题。
RDIES 集群内的数据一致性由 REDIS 集群自己保障(多copy实例之间的一致性)。
三、为什么需要缓存
有时候,业务比较复杂,需要有一个服务对数据加工处理。
服务为了抗量,计算服务之上也需要加一层缓存。此时就再次遇到数据一致性问题了。
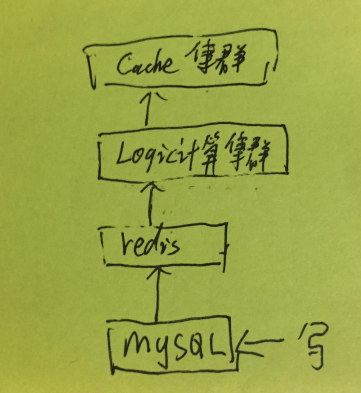
此时,可能会有人问:难道就不能讲所有数据计算好写入 REDIS 吗?
这个问题问得好。
对于互联网这种复杂多变的业务来说,经常会遇到各种计算逻辑的变化。
使用全量写的方式成本太高。
上面说的比较抽象,这里举一个例子来辅助大家理解这句话。
比如有一个字典表,关键字段是 ID 和对应的名字。
假设有几亿的内容,每个内容会关联这个字典表的某个ID,代表这个内容和这个 ID 有关。
外部想要根据内容 ID 拉去这个 ID 和 对应的名字,该如何操作呢?
常规的做法是第一步一个网络操作根据内容 ID 拉取到这个 ID,第二个网络操作根据这个 ID 拉去到对应的名字。
可是,来拉取数据的人有很多,类似的小字典表也有很多,每个人都做这样的操作就不利于业务的发展(内部逻辑需要对外不可见)。
如果对外输出数据的时候,直接将ID以及ID的含义都输出,使用方就会特别方便。
如果没有 LOGIC 计算集群,为了解决上面的问题就需要把这个数据写扩散的方式写到 REDIS 中。
然而一旦涉及到字典表更新,比如某个ID的名字需要变化,就需要写扩散到所有与这个ID 相关的内容上,这个扩散量可能是成千上万倍的。
这就是为什么需要 LOGIC 计算集群的原因,而且还有很多其他原因,这里就不再展开讲了。
随着业务的发展,LOGIC 计算集群 会加入各种计算逻辑,而且有很多计算逻辑还很重。
上层加一层 CACHE 也是必不可少的了。
四、缓存如何更新
缓存系统也是有自己的发展历史的。
初期,一般都是单机缓存,每台机器互相独立。
而且为了简单实现,缓存也是靠过期时间定时回源的,比如每一分钟回源一次。
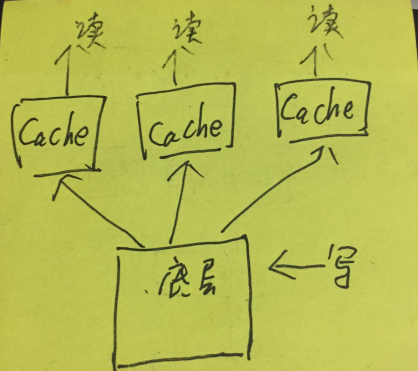
这时,就有数据一致性问题了。
由于每分钟才回源一次,这导致数据写入后一分钟才能生效。
另外由于每台机器独立,这就导致不同机器间的数据,在一分钟内可能会不一致。
而对应的解决方案也很明确:写时进行更新通知,然后进行一些缓存操作。
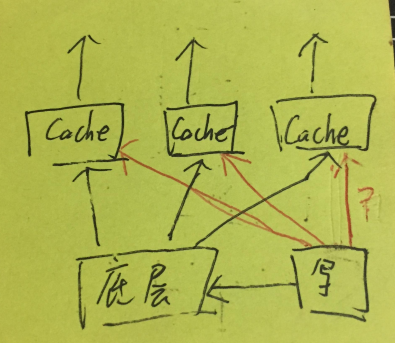
关于数据更新时对缓存的操作,业界已经有很多讨论了。
大概有下面这些操作(没有对错,只有是否合适)。
- 先更新数据库再更新缓存。
这个是最常见的使用方式,但是会有并发问题导致缓存依旧是脏数据。
这里的并发指的是多个更新缓存操作之间的竞争。
而对应的解决方案是更新串行化。
不过上面我们讨论的系统不存在这个问题。
因为缓存服务不是和数据库直接对应的,而是计算服务相连,因此我们没办法主动写缓存数据。
-
先更新数据库再删除缓存
这个操作正常情况下没有问题,但是对于一个非常热的数据,突然因为更新而缓存被删除的话,可能会瞬间对底层造成很大的压力。
所以一般都是尽量不删数据,这样底层回源失败了也可以使用缓存里的数据来兜底。 -
先更新缓存再更新数据库
这里存在很大的问题,因为缓存也会回源数据,可能因为并发问题,把刚更新的数据覆盖掉,从而导致缓存是旧数据。
这里的并发是更新操作与回源操作之间的竞争。
另外,缓存更新成功了,数据库更新失败了问题更严重。 -
先删除缓存再更新数据库
这里的问题更多了。
先删除缓存,会导致热数据的大量透传。
后更新数据库,缓存里可能已经先使用旧数据回源了。
可以看到,上面的四种更新缓存的方法都有一些问题。
于是我们内部想了第五种方法:更新序列号 seq。
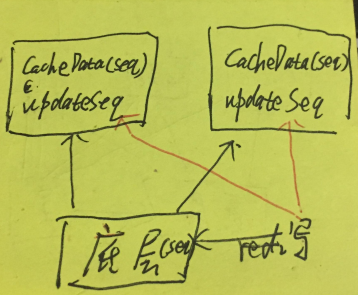
如上图,写数据的时候会写入一个递增的 seq,然后会把这个 seq 通知到各个单机缓存系统。
单机缓存系统缓存的数据里也会储存这个数据的 seq,通知的 seq 会另外单独储存。
这样读请求来的时候,同时读数据和通知储存里seq,然后比较数据里的 seq 和通知储存里 seq,通知储存里 seq 更大则代表数据有更新,进行数据回源。
至此,常见的缓存更新策略已经介绍的差不多了。
接下来就看看数据量越来越多的时候,会怎么样吧。
五、一致性HASH
前面提到,我们可以通过各种策略来更新单机缓存。
但是热点数据量越来越大的时候,缓存的命中率也会越来越低,此时就需要多台机器一起储存一份全量的热点数据了。
为了防止热 KEY,我曾在《一致性HASH技术的困境》里面详细讨论了两种方法。
第一种是小 set 的方式,即多个独立的一致性HASH环。
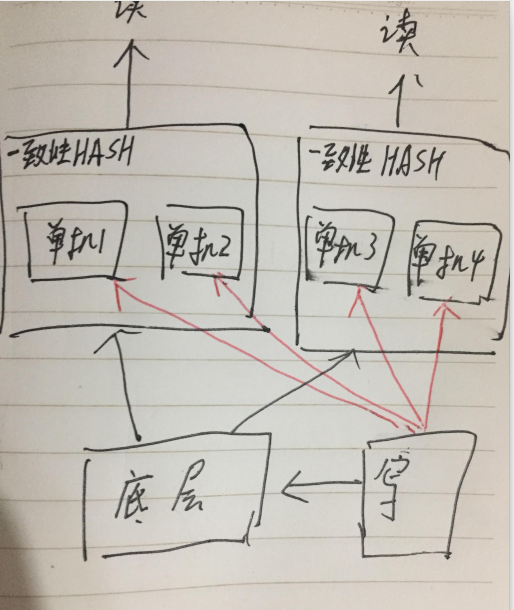
这样做的好处是容量容易评估,一个小set 目前支持了多少量,未来要涨多少量,一换算需要扩容几个小 set 就很清楚了。
说起一致性 HASH,其实有一个隐形的架构没有说出来。
所有的一致性HASH 都需要有两层,第一层相当于接入机,然后对请求进行一致性HASH拆包路由,请求到第二次缓存层。
那么对应的缺点也就很明显,每台接入机的机器需要知道自己应该将请求路由到哪个一致性HASH环。
这个目前的运营系统只能手动配置,因此导致无法自动化扩容。
第二种是一个一致性HASH环,环下是路由节点。
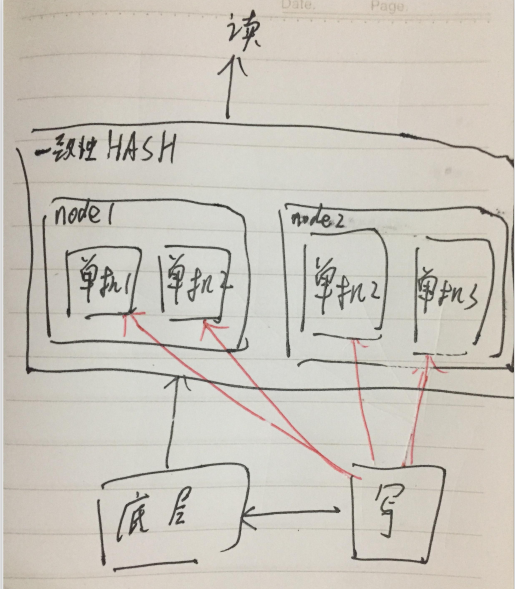
这种设计的好处上篇文章也提到了,天然优势,按需扩容。
某个节点的负载较高了,对应的节点下加机器就行了。
而命中率不足要增加节点时,则可以手动灰度的方式慢慢导量。
而这个方式的缺点也不是没有的。
一致性HASH的每个 NODE 不再是一个机器,而是一个路由表(使用不同的负载均衡组件,可能不同)。
这个在进行业务隔离部署时就会面临一个很大的问题。
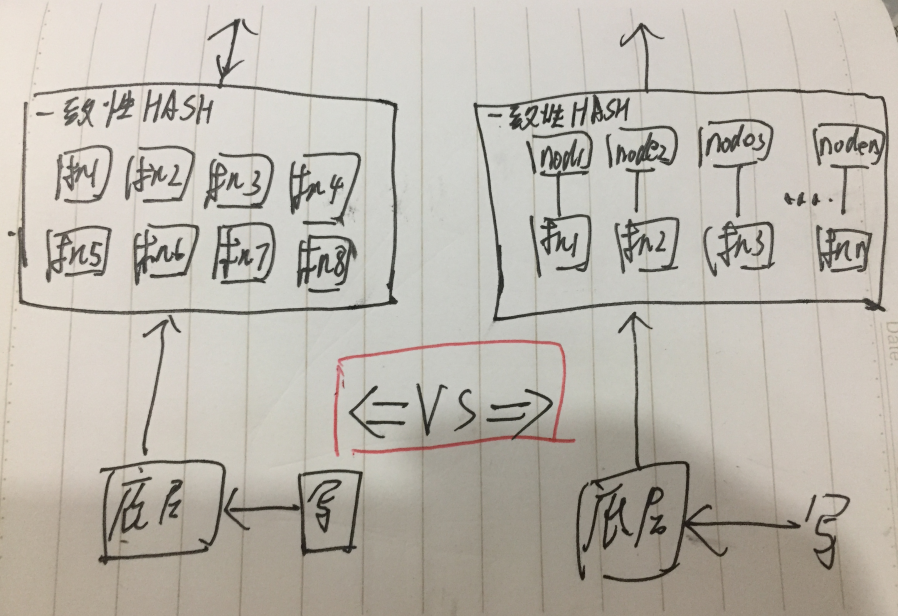
对于小业务,本来需要 N 台机器组成一个一致性 HASH 环,现在需要申请 N 个路由表,维护成本很大。
比如上图,本来8个节点只需要一个路由表,现在就需要8个路由表。
面对这两种设计,各有优缺点。
但都存在一个很大的问题:需要维护大量的配置,由于存在状态,这些配置还不好自动化,需要人工介入。
于是我思考了很长时间,结合和上面的优缺点,构思出了第三种一致性HASH。
第三种一致性 HASH,一个环多个备份。
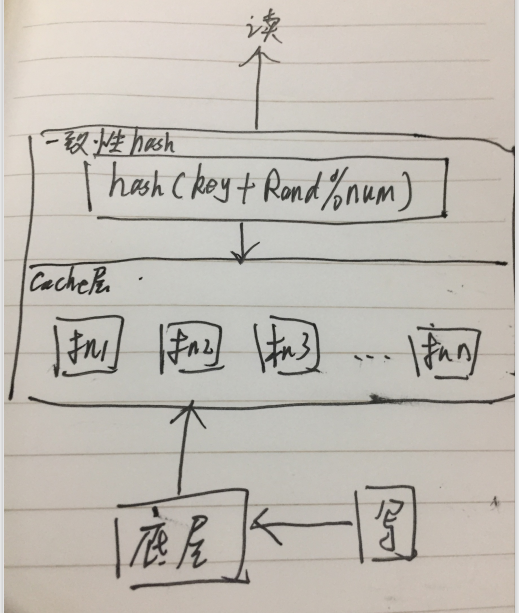
所有的 cache 机依旧在在一个路由表下,路由层对每个请求 Key 进行一致性 hash 的时候,追加一个后缀编号。
这个编号的含义是数据储存的 copy 数,由于 key 追加了编号,同一个 Key 将随机的路由到不同的 cache 机去。
这样就完美的解决了热 KEY 的问题,还解决了扩容时需要维护大量配置的问题。
扩容时,只需要将机器以灰度的方式挂在路由表下面即可。
而因热Key问题使得机器间的负载差异大了,则可以增加 copy 数来均摊流量(缺点是非热 KEY 数据也增加了 copy)。
这种架构设计,对于单 KEY 缓存系统堪称完美,可惜对于多 KEY 系统依旧存在一些问题。
如果你阅读了《一致性HASH技术的困境》这篇文章的话,里面的第五小节重点讨论了 批量请求 KEY 扩散问题。
由于小 SET 的存在,一致性HASH的节点不会很多,此时可以通过一致性HASH后再次聚合KEY缓解扩散问题。
而此时所有节点挂在一个路由表上,那么可以理解为一致性HASH的节点有非常多,那么对 KEY 的聚合就起不到很好的作用了。
此时,cache 层的请求量就会扩散的非常严重。
比如业务的请求量是 10万/秒 ,批量请求带了 100 个 KEY.
正常情况下是 20 个小 set,每个小 set 有 10 个节点,这样 cache 层的请求量扩散到了 100万/秒。
而在一个一致性 HASH 环下,cache 节点就是 200 个,则 cache 层的请求里会扩散到 1千万/秒。
这个扩散量是不敢想象的。
虽然自己想出了一个可以自动化扩容的架构,但是这种架构对冲了之前缓解的KEY扩散问题,在KEY较多的场景是不适合的。
因此,我对比了这三种架构,发现各有优缺点,为何不都实现了,然后在不同场景使用不同的的架构呢。
对于小业务,则使用我创造的那种架构,而对于大业务,则可以使用HASH环下是路由表的架构。
由于大业务一般固定,一次性创建好所有节点的路由表,后面只需要往路由表上扩容即可。
六、一致性HASH 更新问题
如果你细心的话,会发现介绍前两种架构的时候,写操作都会对单机进行更新通知seq。
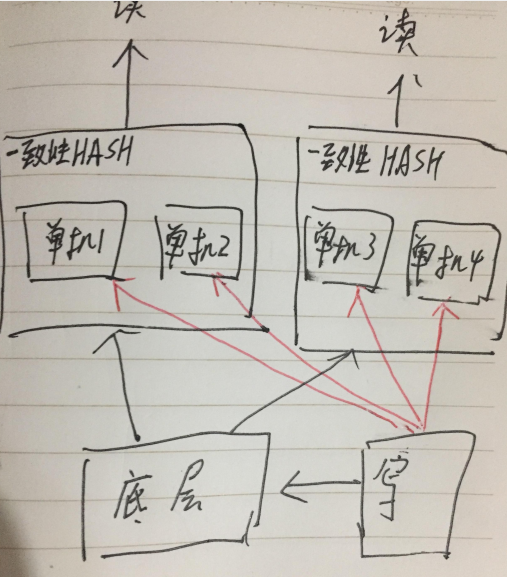
这个更新通知seq是单机全量更新的。
这个更新量大的时候,就会导致另外一个问题:单机存不下更新的seq。
所以在设计第三个架构的时候,我就规划着单机不再储存全量的通知seq。
通知的seq也通过一致性 HASH 写进来。
扩缩容的时候,由于新机器没有业务数据,所以不存在数据更新数据不更新问题。
但是当一致性 HASH 发生抖动的时候,则会发生数据一致性问题。
原先一个 KEY 路由到 A 机器,数据缓存起来。
由于抖动, KEY 路由到 B 机器,此时数据发生更新,通知 SEQ 储存在了 B 机器。
抖动恢复,KEY 重新路由到 A 机器,缓存里还有之前的旧数据,问题发生。
对于一致性HASH,一般有防抖动的,所以抖动的几率比较小。
但是某个节点临时停服的可能到时存在的。
一个节点临时停服时,会自动从一致性HASH环上剔除。此时本应该属于这个节点的数据和通知都会写到其他节点。
等这个节点恢复服务,由于某些通知没有写进来,就可能导致缓存里的旧数据迟迟不能更新问题。
不过还好,现在一般都支持 热重启了,即不停服的方式升级服务。
七、最后
这篇文章啰里啰嗦的介绍了CMS数据系统的为何从 MYSQL 到 NOSQL、为何 NOSQL 之上还需要缓存系统、缓存如何更新、一致性 HASH 的几种架构以及一致性 HASH 面临的缓存问题。
我们要知道,每种架构与设计否有对应的优缺点。
架构是随着业务发展而逐渐优化调整,访问量翻倍了如何优化,再次翻倍了可能就会面对新的问题,之前的优化可能就不能解决这个问题了。
不止是访问量,数据量、更新量不断翻倍时,架构都会面临这样的困境,而数据更新只是其中的一个问题。
至于其他问题,以后有时间了再来聊一聊吧。
-EOF-
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
