记一次神秘的内存泄露问题
作者: | 更新日期:
使用所有方法之后,发现还是删代码最好用。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
一、背景
一个月半前,在《自愈:问题自动发现与修复》文章提到过,我做了一个自愈服务。
核心逻辑是自动监控数据是否正确,不正确了进行自动修复。
自愈功能确实完美的运行着,只是后来发现了一个瑕疵:服务存在内存泄露。
由于历史监控数据只有最近一段时间,更早的无法回溯,所以什么时候引入的内存泄露也就没法查找了。
当时在忙着上云、搞中台、接EPC,简单看代码没找到问题,看内存一天上升的也不多,就没排期处理。
跑了两周,就收到内存使用率 90% 的告警,当时我随手重启一下服务来规避这个问题。
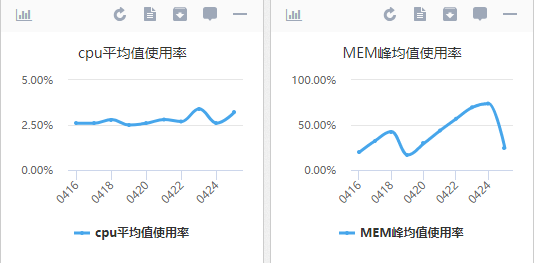
不过上周又收到内存告警,我便把这个问题交给一位同事,让他周一来定位一下。
昨天在文章《算法:小于当前数字之和》中也提到, 我的 leetcode 中文账号登录不上了,没参加比赛。
作为时间管理大师,本来时间都是排的满满的,这突然多出了一个下午的时间(打比赛)和一个晚上的时间(写解题报告)。
我便来公司定位这个问题了。
二、review 代码
定位问题前肯定先看下代码的大概流程了。
我大概一看,流程非常简单。
1、A进程拉kafka转发给B进程组。
2、B进程组通过一致性HASH将数据转发给B进程组。
3、B进程组将数据放入队列。
4、B进程组定时器定时检查队列,满足时间的进行数据校验。
这里是 B 进程组存在内存泄露。
而且可以看到,B进程组存在三个操作:转发、入队、检查。
转发是纯 CPU 计算,入队会把数据扔到队列中,检查会消费队列的数据。
这里很容易怀疑检查操作存在BUG,导致队列内存爆炸了。
我初步看代码流程没发现问题,于是拿出了神器 GDB。
三、GDB 检查内存
使用 GDB 之前想想一下要干啥。
我们是想看看队列的大小有大多,有没有爆内存。
为了不影响线上服务,我们可以先生成一份程序的镜像文件,即core文件。
然后挂到 core 文件上,找到队列的服务,获得队列的大小。
于是我一顿操作:
1、gcore 生成镜像
2、gdb bin core 挂上去
3、info thread 找到主线程
4、thread 切换到主线程
5、info variables 搜索队列的符号信息
6、p 打印队列信息
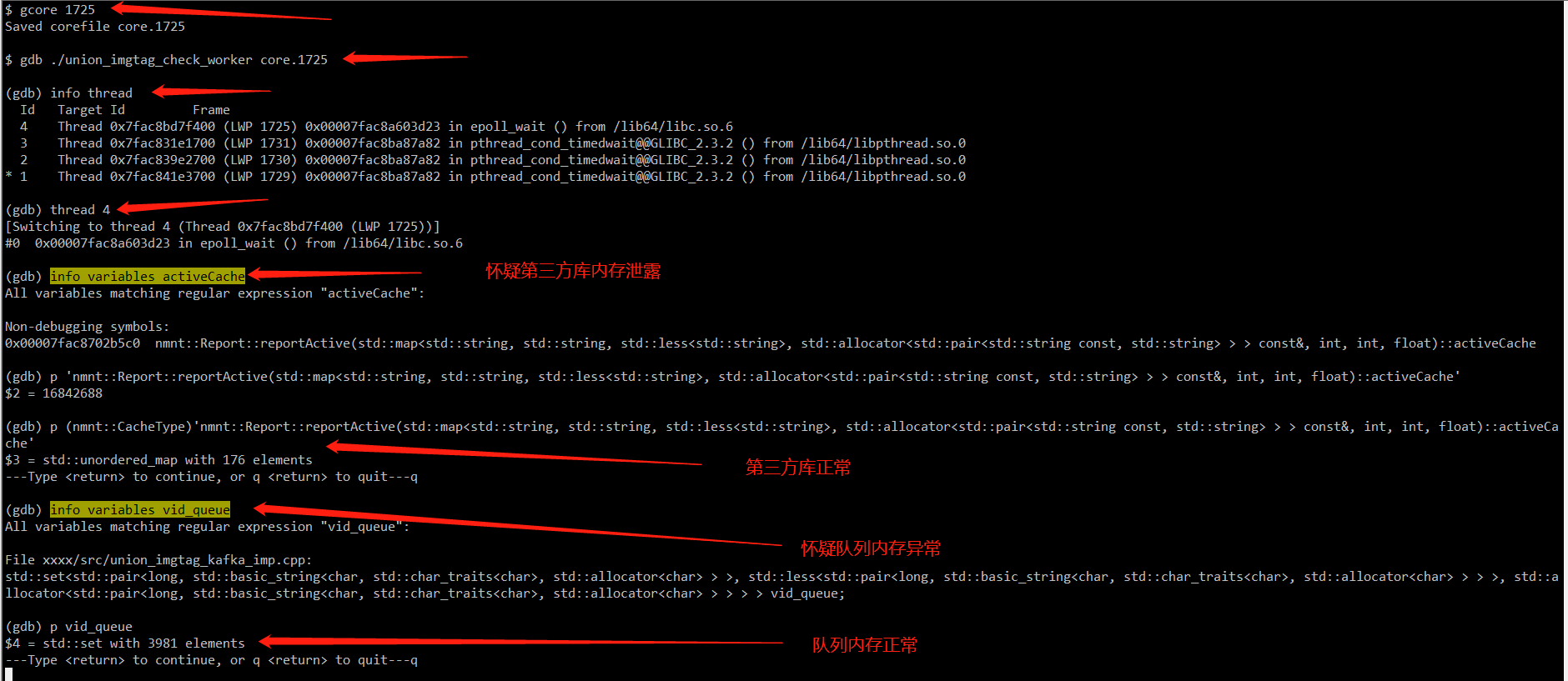
当时,我除了怀疑自己的队列内存有问题外,还怀疑某个第三方库有问题。
顺带都看了,发现都正常。
啥叫做正常,就是现在看队列有几千个,20分钟后内存涨了很多,队列里面还是那么多个。
所以排除了第三方库和自己代码的问题。
四、valgrind 检查
在内存泄露的工具里,最出名的是 valgrind 了。
我去官网下载后在开发机上编译,发现在测试机上跑不起来。
提示下面的错误
valgrind: failed to start tool 'memcheck' for platform 'amd64-linux': No such file or directory
有人说编译之前需要执行./autogen.sh,我试了没解决问题。
于是我只好在测试机上进行编译,然后成功把 valgrind 跑起来。
跑了好久,只看到一个Uninitialised value was created by a stack allocation错误。
报这个错误的具体位置是公司的一个公共组件,找到源代码看后发现没问题。
于是使用 valgrind 算是没啥收获,没找到内存泄露的地方。
四、万能的删代码
自己的代码没问题,内存又存在泄露,那还是需要找到原因的。
所以我拿出了终极绝招:删代码。
第一步是把第三方库屏蔽掉,毕竟第三方库不是关键路径。
结果和预期一样,依旧内存泄露。
然后回头看看自愈服务的逻辑,有四个操作。
1、A进程拉kafka转发给B进程组。
2、B进程组通过一致性HASH将数据转发给B进程组。
3、B进程组将数据放入队列。
4、B进程组定时器定时检查队列,满足时间的进行数据校验。
第二步是B进程组不进行一致性转发,即B进程组收到kafka的转发包后什么都不做,结果内存不泄露了。
这说明之后的步骤存在内存泄露。
第三步是B进程组进行一致性HASH转发,但是不放入队列中,内存还是不泄露。
说明是定时器步骤处理逻辑存在内存泄露。
第四步是B进程组把数据放入队列,定时器检查队列时不做校验逻辑,直接按校验通过处理,内存也不泄露。
于是可以确定,是定时器校验逻辑某个地方存在问题。
就这样一步步拆分步骤,发现在调用一个公共库的时候存在内存泄露。
五、兼容问题
看到公共库问题后,我马上猜测是库的版本不一致导致的了。
于是去看看 RPC 微服务框架的代码,发现还真是 RPC 框架的问题。
之前我已经研究的很熟悉了,并写过四篇文章。
1、《静态库遇到静态库》
2、《静态库遇到静态库2 ABI》
3、《静态库遇到静态库3 举两个例子》
4、《静态库遇到静态库4 两个解决方案》
简单说就是,我用到的 A 库被 RPC 框架封装了一层,RPC 框架也算是一个库。
然后RPC 框架使用的是很多年前的 A 库编译的,链接的时候 RPC 指向的是 A 库的最新版本。
版本的差异触发了不兼容问题。
于是我写了一个测试程序验证自己的猜想,果然 RPC 框架会某些时候会导致内存泄露。
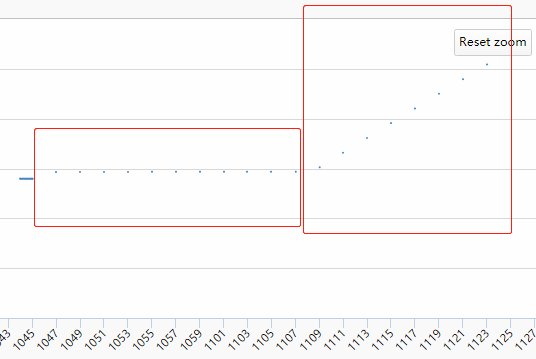
六、最后
就如《举两个例子》文章中说的,库不兼容问题会导致不可预知行为,比如逻辑发生错误,内存泄露,cordump等,这个根据不同的内存错误可能发生不同的事情。
这次的内存泄露往深处讲也可以解释的通,但是这里就不展开讲了,毕竟涉及到内存布局会汇编的知识了。
思考题:你遇到过库冲突问题吗?
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号:tiankonguse
公众号ID:tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
