花 3 小时读了 Google Protocol Buffer 官方文档
作者: | 更新日期:
可以当做小的手册来看看
本文首发于公众号:天空的代码世界,微信号:tiankonguse
一、背景
三年前我曾介绍过《什么是协议》。
后来也在《协议之Google Protocol Buffer》文章中简单的介绍了 protobuf2 协议。
文章中提到,我们使用的 Protobuf 没有 map 这个数据结构,我们通过 repeated message 实现的。
实际上,当时写文章的时候,google 已经发布了 Protobuf3 beta 版了,而且当时已经增加了 map 这个类型。
所以,我今天花了两三个小时把官方的英文文档全部看了一遍,顺便记录一下相关特性,方便以后当做手册来随时翻阅。
官方地址:https://developers.google.com/protocol-buffers/docs/overview
二、为什么选择 Protocol Buffer
首先需要明确使用场景,Protocol Buffer 的使场景是通信协议。
业界常用的通信协议是 HTTP + 文本 或者 HTTP + JSON 通信协议。
不管是 HTTP 还是 文本域JSON,由于他们自身的设计缺陷,都有一个致命问题:性能比较低。
所以对于后台服务,为了高性能,一般会选择 二进制包头 + 二进制协议。
二进制包头不同的公司甚至不同的部门,都会有不同的设计,这里不过多讨论。
而二进制协议,大家一般很少自己独立设计一个新的协议。 毕竟 Google 的 Protocol Buffer 这么成熟了,性能还这么高,直接拿来用就行了。
据说我们这边,去年做了一个较大的重构就是由私有协议切换到 Protocol Buffer 协议。
三、版本
Protocol Buffer 有两个版本,语法有差异。
协议文件需要在指定当前使用的那个版本,不指定则为默认版本proto2。
syntax = "proto3";
四、引入协议文件
对于比较大的项目,协议可能会拆分成很多文件。
如果一个协议文件用到了另外一个协议文件,就可以使用import 将对应的协议文件引入进来。
import "myproject/other_protos.proto";
五、文件作用域
对于 C++ 语言,有 namespace 的概念。
对于 java 语言,有 package 的概念。
规定,使用 package 来为一个文件指定作用域。
package com.example.foo;
六、数据类型
协议中基本单元就是一个类,使用message 来定义。
message SearchRequest {
required string query = 1;
optional int32 page_number = 2 [default = 0];
optional int32 result_per_page = 3;
}
可以看到,类成员大概由 5 部分组成。
第一部分是称为 Field Rules。
可以选择的有 必填 required,可填 optional,重复 repeated。
可以发现, Field Rules 中有一个 repeated,含义是这个成员是一个数组。
不过这个 Field Rules 设计其实有问题,选填必填的含义 与 重复并没啥关系。
所以 proto3 废弃了 required 和 optional,如果不是数组,可以什么都不填写。
第二部分是成员的类型。
可以是整型、浮点、bool、字符串四种基本类型。
也可以是 嵌套其他message 类型。
第三部分是成员的唯一编号。
协议序列化为二进制的时候,不会储存成员的名字,会储存这个编号。
第四部分是可选的默认值。
proto3 也废弃了默认值,一切类型都走语言的默认值,这样打包的时候,默认值就不打进去,性能更高。
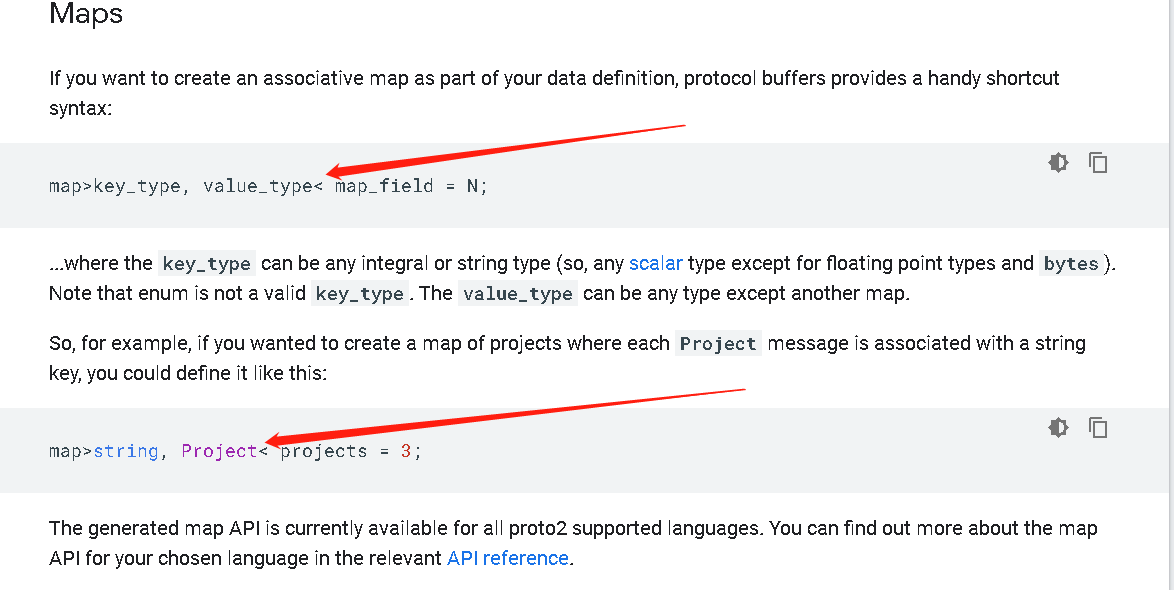
七、Maps
第一部分提到过,新的版本支持了 map。
map<key_type, value_type> map_field = N;
使用和编程语言自带的 map 差不多,唯一的区别是 遍历 map 时,不保证 key 有序,而且是随机的。
我为啥知道呢,之前我在《高端的写 if 与 else》中介绍我实现了一个小的引擎,其中涉及到 map 到 string 的转换,结果每次转换输出的 string 不一致,单元测试没通过。
后来只能将 map 转化为 vector,再进行 sort,最后转化为 string 了。
另外通读整个文档的时候,还发现谷歌的一个错误,应该存在好几年了,一直没改。
八、Oneof
Protocol Buffer 还有一个比较大的功能就是支持了 Oneof,类似于 c++ 中的 Union。
message SampleMessage {
oneof test_oneof {
string name = 4;
SubMessage sub_message = 9;
}
}
意思是几个变量只能有一个有值。
这样的好处是转化为二进制的时候,可以避免无效的打解包与无效的储存,性能更高,包也更小。
九、其他特性
当然,Protocol Buffer 还有很多其他特性。
比如 枚举 enum、Any、reserved 保留字段、extensions 扩展字段等等。
另外还支持一个叫做 Options 的选项。
比如对于文件的作用域,不同语言可以声明不同的名字。
option java_package = "com.example.foo";
另外对于生产的代码文件,也可以通过optimize_for 参数来控制。
SPEED 为默认值,代表高性能模式。
CODE_SIZE为压缩文件模式,功能与默认模式完全一样,只是很多功能有编译器转化为了运行期,所以性能有损耗。
LITE_RUNTIME为精简模式,主要是为了移动端使用的,生成的执行文件会很小,不过功能也被阉割了。
最后,看文档还支持 json 映射功能。
一个 message其实就是一个结构化的数据,Protocol Buffer 自带函数与 json 互转。
MessageToJsonString(pb_data, &json_string, options);
JsonStringToMessage(json_string, &pb_dat2, options2);
十、最后
Protocol Buffer 其实还支持生成 grpc 微服务的相关代码。
不过我们这边还没涉及到,我也没用过,这里就不展开介绍了。
思考题:使用 Protocol Buffer 的时候你又遇到什么问题吗?
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号:tiankonguse
公众号ID:tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
