简单聊聊搜索
作者: | 更新日期:
最近准备从sphinx切到ES了,这里梳理一下搜索到底做了什么事情。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
大家好,这里是tiankonguse的公众号(tiankonguse-code)。
tiankonguse曾是一名ACMer,现在是鹅厂视频部门的后台开发。
这里主要记录算法,数学,计算机技术等好玩的东西。这篇文章从公众号tiankonguse-code自动同步过来。
如果转载请加上署名:公众号tiankonguse-code,并附上公众号二维码,谢谢。
零、背景
早在2014年,我就了解过sphinx以及对于的随手技术,当时还写过几篇文章。
这几天搭建了sphinx的实时索引,也搭建了Elasticsearch,都体验了一下,这里简单聊聊这些搜索系统。
一、搜索的基本知识
一般情况下我们有一批数据,比如文章已经保存在DB中了。
如果我们拿着文章ID去查询文章的话,可以快速找到对应的文章。
但是当我们想使用文本来搜索类似的文章时,普通的DB就不能很好的满足我们的要求了。
这个时候我们就需要一个搜索引擎帮我们搜索到对应的文章了。
对于所有的搜索引擎,至少有三个模块:数据收集,分词倒排,搜索查询。
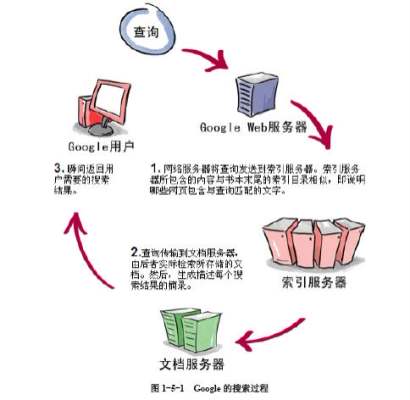
数据收集模块比较好理解,我们需要把待搜索的数据导入搜索引擎才能进行搜索。
比如对于谷歌和百度,每天都在会去各大网站爬去网页内容,然后导入到自己的搜索引擎中。
分词倒排是搜索引擎的关键技术。
比如我们有下面几篇文章。
| DocID | title |
|---|---|
| 0 | hello word |
| 1 | hello sphinx |
| 2 | hello es |
| 3 | sphinx and es |
搜索引擎会进行适当的分词倒排处理, 储存为下面的样子.
| word | DocIDList |
|---|---|
| hello | 0,1,2 |
| word | 0 |
| sphinx | 1,3 |
| es | 2,3 |
| and | 3 |
对于搜索查询模块,就是对搜索条件进行分词,然后去倒排索引中查询每个词的结果然后聚合起来。
比如我们使用”hello es”来查询文章,则第一步将搜索条件分解为”hello”和”es”,然后就可以在倒排索引中分别查到两个文章信息”0,1,2”和”2,3”,最后聚合就精确得到了DocID为2的那篇文章了。
基础知识结语:
上面三步是搜索引擎的基本原理,但是实际应用中还需要考虑还是问题,比如数据怎么更新,怎么支持搜索多种数据,数据量大了怎么分布式,怎么容灾等等。
下个小节分别来详细的看看这些问题是怎么发生的,又该如何解决吧。
二、搜索面临的问题
问题1:数据怎么更新
看了第一小节我们了解到搜集的数据在搜索引擎经过了分词处理,最后使用倒排的方式储存了起来。
这种方式导致一个问题就是没办法在原有的储存上更新数据了,或者非要去更新的话成本是很高的(给大家留个课后作业:原有储存上更新成本为什么很高)。
既然在原有的数据更新成本很高,那我们能不能重新储存一份呢?
想要重新储存一份需要看看这样做会带来什么样的问题。
我们搜索的时候,会在旧的数据上搜索一份数据,在新的储存上也搜索一份数据,这样结果集就重复了。
重新一份数据会导致结果集重复,所以我们还需要一个机制来避免重复。
这个机制的效果是我们可以对结果集进行判断,判断是否有重复,如果有还需要找到最新的那个。
具体实现方案很多,这里也不提了,算是再次给大家提一个课后作业吧。
数据更新的结论:
结论就是更新的数据当做新数据重新储存起来,然后使用其他直接保证避免搜索出旧数据。
问题2:多机更新数据
第二个问题还是谈谈更新数据的问题,不过这里的重点在于多机,而不在更新。
假设我们的搜索引擎部署了三套,每套的数据完全相同。
我们要向引擎写入数据了,如何写入呢?
简单思考一下,无非三种情况:
- 分别写入三个引擎。
- 写入到同一个中间储存,引擎自动加载中间储存。
- 写入任意一个,引擎会自动同步到其他两个引擎。
对于第三个算是最理想的方法,引擎之间会进行通信,数据自动同步。
而对于前两个其实本质是一样的,引擎之间互相独立,只不过一个是主动写一个是被动写。
对于数据自动同步其实又是一个很大的话题了,这里不做介绍,后面有时间了再另起一篇文章来聊聊数据同步。
问题3:多索引
多索引的概念是:搜索引擎可以支持搜索多种不同的数据。
比如可以搜索文章,还可以搜索博客,还可以搜索明星资料。
由于不同的资料,储存的数据格式完全不同,我们不是做一个类似于谷歌那样通用型搜索引擎,我们只需要做一个垂直搜索引擎,每次能够搜索一种资料即可。
但是新增一种资料需要快速方便。
对于能够支持的搜索资料,分两种。
- 完全写死,新增需要手动修改,引擎会间断服务。
- 配置化,平滑新增搜索资料。
有人可能会想第一种方案怎么可能存在,做一个搜索引擎必须有第二个功能吧。
实际情况时用第一种的人还真不少,我14年来视频后就搭建了一套第一种方案的搜索引擎,一致用到今天。
是的,现在你体验的很多服务后面都是第一个方案,不过下半年计划切换到第二种方案了。
问题4:分布式
分布式涉及到数据拆分的问题。
那自然有牵涉出怎么拆分的问题。
这里假设有3台机器。
第一种方案是写死:分别手动配置三台机器需要为哪些数据创建索引。
第二种方案是自动化:预先为数据分别N个节点,这些节点引擎自动分配到三台机器上。
好吧,我承认第一种方案还是我们在使用的方案,不过还不是真正的分布式,我们是按数据类型进行伪分布式。
比如电影的数据全部在机器1,电视剧的机器全部在机器2,其他的数据全部在机器3。
而对于真正的分布式应该是数据均等的,请求来的时候拆分为多个请求分别去多台机器,最后把结果聚合排序然后返回给请求方。
这种分布式的好处在于成本分摊。
本来每个条件对于3W个数据,现在均摊到三台机器,由于机器均等,所以每台机器只计算1W个数据,显然加快了计算速度。
当然这种方式也带来了其他成本:聚合成本。
尤其是返回的结果集比较大时,聚合成本也变得无比巨大。
问题4: 页数
上一个问题最后提到聚合成本。
其实在聚合之前的单机搜索数据模块,数据量大了也存在聚合成本的。
这也就是为什么搜索引擎一般只支持返回1000条数据,或者越往后翻页速度越慢。
下面是我对google的测试, 搜索条件是”hello”.
- 找到约 1,510,000,000 条结果 (用时 0.96 秒)
- 获得约 1,510,000,000 条结果,以下是第 2 页 (用时 0.74 秒)
- 获得约 1,510,000,000 条结果,以下是第 3 页 (用时 2.39 秒)
- 获得约 1,510,000,000 条结果,以下是第 4 页 (用时 1.24 秒)
- 获得约 1,510,000,000 条结果,以下是第 5 页 (用时 1.01 秒)
- 获得约 1,510,000,000 条结果,以下是第 10 页 (用时 1.23 秒)
- 获得约 1,510,000,000 条结果,以下是第 14 页 (用时 1.27 秒)
- 获得约 1,510,000,000 条结果,以下是第 19 页 (用时 1.82 秒)
- 获得约 1,510,000,000 条结果,以下是第 31 页 (用时 1.83 秒)
- 获得约 1,510,000,000 条结果,以下是第 35 页 (用时 1.95 秒)
可以看到前几页的时候不到一秒就返回了,翻到后面的时候大概是2秒.
而我翻到36页的时候,就没有结果了,也就是google只支持不到四百个结果。
而对于那些不懂搜索原理的人,往外会提出这样的需求:我们需要页数可以无限翻下去。
是的,有些业务真的会拉好多数据,给大家上一张图,搜索引擎面对这些请求返回错误其实也是完全符合预期的,毕竟请求的参数太过分了。
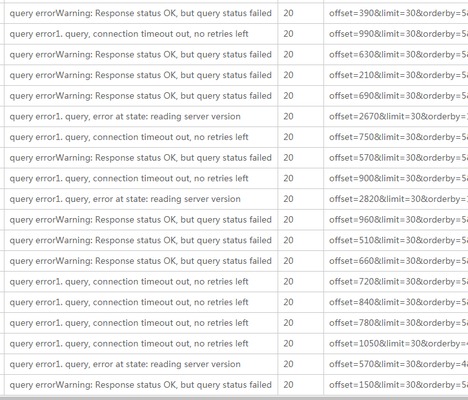
这里其实有一个很大的问题的,我再稍微说明点。
假设我们搜索的是”hello word”, “hello”找到10万个主键, “word”找到15万个主键,搜索引擎需要将这个25万个主键进行去重聚合运算。
假设运算后有9万个数据,还需要进行排序。 最后用户可能只需要前10条数据,但是我们的计算量确实试试在在的那么多次。
当然,实际实现的时候可以进行适当的优化,比如排序和最终要的数据条数结合起来,找到需要的数据后,后面的就不需要排序了。
但是由于每个词对于的数据量太大,搜索的性能必然存在问题的。
这里假设我们是分布式的,有10台机器,这时候搜索就不一样了。
请求分散到10台机器,每个机器只有十分之一的数据,我们可以在每台机器上计算出前10条数据,最后将100条数据聚合再次排序,就可以得到最终的结果了。
这里可以看到我们将原先的上万条数据分摊到10台机器上,每台机器的压力就对应比例的降低,这样就可以更快的查询到结果了。
看完了分布式的好处,接下来看看一个反分布式查询语句吧。
我们需要查询第一万条满足条件以后的10条结果。
这个对应与常用的limit 10000,10。
这个时候,每个机器都需要计算上万条记录,然后汇总机器就是10万条记录,然后我们才能计算出想要的那10条记录。
当然,这种情况很少,但是对于媒体业务,经常会遇到这样的需求,美言之为了SEO优化,美言之真有那么几个优化会翻上千页。
对于这种情况,实在没有好的办法,不过搜索引擎都会有一个小缓存的:即对搜索结果列表进行缓存,下次遇到相同条件时直接返回结果即可。
问题5:容灾
当一个功能上线,必然面临着容灾的问题。
比如机器突然挂了,比如服务压力大需要上新机器。
我们做搜索引擎的时候需要考虑这些情况。
这里重点说的是机器上的容灾,即增加机器了会怎么样,减少机器了会怎么样?
根据上面几个问题的描述,手动配置的在容灾方面都是不足的,甚至是致命的。
先来看看导入数据,每台机器是单独导入数据的,那新增一台机器是不是需要全量导入数据?
数据有上亿条,累计几十上百G,而且数据也不是现成的,一般需要实时去各个接口拉取,没有几个小时是同步不完的。
我们服务压力大紧急扩容,同步数据需要几个小时, 那时候服务早被压死了。
再来看看分布式,每台机器是单独配置读哪部分数据的,或者单独导入数据的。
那这台机器死了,新来的机器需要重新同步数据或加载数据,数据量那么大,也是需要时间的。
注意,这里强调的是分布式的部分数据,而不是导入数据。
当然容灾上还设计服务是否可靠,即是否是7*24小时提供服务的。
对于那些每种索引是单独配置的搜索引擎,我们新增一种数据类型,都需要手动修改配置,重启搜索引擎。
一般搜索引擎启动时需要很长的时间来加载索引数据的,所以这段时间是不可服务的。
容灾上还有其他的,这里只提这三点吧。
总体来说就是搜索引擎做的事情越少,我们容灾上面临的问题就越多。
三、搜索上的实际应用
实际应用中我接触过sphinx和Elasticsearch。
对于sphinx支持三种模式;增量普通模式、增量分布式模块、实时模式。
而对于Elasticsearch只有一种模式:实时分布式模式。
对于业务来说,服务一旦搭建起来,经常变更的有:增加减少机器,增加其他搜索资料,某个搜索资料加字段。
对于sphinx,不管哪种模式,所有配置都是手动写死的,任何一种变更都需要间断服务。
而对于Elasticsearch,我们都可以通过接口动态调整,而不需间断服务。
下面我们分别来看看是怎么实现的吧.
1. sphinx 增量普通模式
上面在问题1:数据怎么更新里面提到了一般是重新储存一份数据。
对于sphinx 增量普通模式,具体实现方式就是建两个索引:全量与增量。
全量索引每天凌晨都重新加载全部数据。
增量索引每隔几分钟就重新加载当天的数据。
这两个合起来就可以伪实时的提供搜索服务了。
对于重复问题,增量索引还提供指定哪些docId应该在全量索引中忽略.
有了这个,聚合数据时对满足条件的数据进行过滤,就可以得到最终的结果了。
是的,增量普通模式 只提供了上面这些功能,其他你能想到的功能都没有提供。
比如原先支持对文章进行搜索,后来文章这个资料加了一个字段,sphinx就需要手动的修改配置来加字段,并重启服务。
又比如我们要支持人名搜索了,也需要配置新的索引,也需要重启服务。
索引配置大概如下:
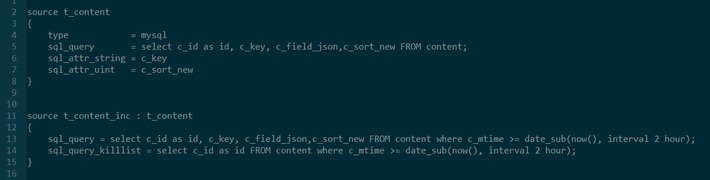
不管新增字段还是新增索引,都需要修改这个配置文件,并重启服务(服务启动需要很长时间的)。
2. sphinx 增量分布式模式
sphinx的分布式模式和普通模式只有一个区别:分布式。
其他的完全一样,直接看配置吧。
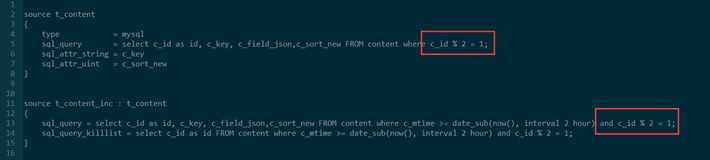
多台机器分别读不同的数据。
是的,你们没有看错,大部分人都是使用mysql的左值运算来进行分布式的。
如果是我,我更倾向于分号段,即下面这种方式:c_id <= 100000,c_id > 100000 and c_id <= 200000,c_id > 200000。
分号段的好处是后续可持续性扩容,而取模的方式是致命的(课后作业又来了,有什么缺点呢?)。
至于sphinx增量分布式模式的其他问题,和增量普通模式完全一样,这里只是新增的功能,然后新增了一些问题而已。
3. sphinx 实时模式
对于sphinx的实时模式,和普通模式相比增加了实时功能,但是放弃了数据源。
什么意思呢?
在普通模式下,sphinx是通过db来加载数据的,这样扩容什么的耗时浪费在重新加载DB数据并创建索引上.
而对于实时模式,丢弃数据源意味着我们需要通过接口一条条来写数据,如果扩容了,就需要写全量数据。
虽然和加载DB一样是导入全量数据,但是这个是通过api一条条写入的,最终影响是很严重的。
加载DB的话我们可以在十几分钟完成,但是通过API的话,没有几个小时是加载不完的。
另外就是加字段,扩容等面临着一堆问题等待我们去解决。
sphinx仅仅是一个索引工具,只负责分词查出结果来,对于实际使用中的问题就需要自己去面对了。
4. Elasticsearch实时分布式搜索
我们看到sphinx可谓是搜索引擎中最简单的引擎,只实现了分词与查询,对于小公司小项目使用还是可以接受的。
但是项目重要程度提上来时,我们只能放弃sphinx了,使用更完善的搜索引擎才是最可行的方案。
这里我选择了Elasticsearch,Elasticsearch简称ES。
我们先来看看面对之前提到的问题,ES是怎么解决的。
- 数据更新:ES内部自己管理,不需要我们关心增量以及旧数据的问题。
- 多机更新:ES只需要写入一次数据,内部可以自动同步。
- 索引与字段:ES可以动态的增加索引或者增加字段。
- 分布式:ES自身就是分布式的,内部会自动把部分数据同步到新机器。
- 页数:这个是任何搜索引擎都会面临的问题,需要产品形态上解决。
- 容灾:增加或减少机器后,我们不需要做任何操作,ES自己会管理这些,而且不会间断服务。
好了,看完上面的对比,有人会反问难道ES就没缺点吗?
当然不是,所有分词倒排的搜索引擎都会面临两个问题:倒排数量与页数。
这两个问题实际在上面的页数问题里面都提到了,现在再回顾一下。
还是搜索”hello word”,这里说的夸张点。”hello”可以匹配100W个数据,”word”可以匹配150W个数据。
不知道大家看到数据后有什么第一感觉。
我的第一认知是至少需要把100W数据和150W数据加载出来,才能进行聚合。
这里的100W和200W就是我说的倒排数量问题。
页数的问题是假设聚合后得到80W数据,我的请求数据是第70万开始,要10个。
对我来说我只是要10个数据,对于后来来说至少需要先拉出70万多点数据才行。
而对于分布式,每个节点都需要拉出70W多点数据,最后还需要聚合,不多说了。
这就像大象放进冰箱里需要几步,不管怎么优化,都需要打开冰箱,放进去,关闭冰箱。
搜索引擎的倒排数量和页数也是一个道理。
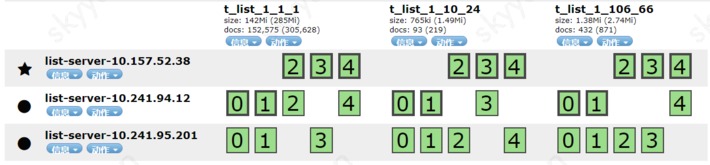
最后看看ES的可视化管理图吧。
二、总结
sphinx虽然很多问题,但是提供了最基本的搜索功能。
所以大部分小公司和小项目还是可以使用这个软件的。
但是项目大了重要了,面对可扩展性与容灾问题时,最终必然需要放弃这个软件。
对了现在开通了公众号和小密圈。
博客记录所有内容。
技术含量最高的文章放在公众号发布。
比较好玩的算法放在小密圈发布。
欢迎大家加入看各种算法的思路。

长按图片关注公众号,阅读不一样的技术文章。

本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
