从列表搜索到自动化测试监控的碎碎念
作者: | 更新日期:
聊聊列表搜索的话题。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
大家好,这里是tiankonguse的公众号(tiankonguse-code)。
tiankonguse曾是一名ACMer,现在是鹅厂视频部门的后台开发。
这里主要记录算法,数学,计算机技术等好玩的东西。这篇文章从公众号tiankonguse-code自动同步过来。
如果转载请加上署名:公众号tiankonguse-code,并附上公众号二维码,谢谢。
零、背景
最近一个月都没有动笔,第一是周末在看LOL比赛,第二是零碎的时间用于看书了,第三是最近在重构列表项目,繁琐的事情比较多。于是就迟迟没有写文章。
转眼已经11月了,这周自己需要写点什么,想了想,就写写最近做的项目相关的东西吧。
于是就有了这篇列表搜索与自动化测试的文字了。
PS1: 这篇文章的数据不涉及机密数据,使用爬虫都可以爬的到的,当年产品说要提供几百页的数据我强烈反对,产品回答的是这些主要是给搜索爬虫的,为列表的数据提供一个入口,当时我也是惊呆了。
PS2: 我们组还有一些HC名额,主要面向C++程序员,有意向的可以联系我。
一、场景与实现
对于列表系统的使用场景,可以直接看下面的这张图,和淘宝搜索东西一样,有很多条件选择,最后出来一个结果列表。

各大公司都有这样类似的场景,所以想要简单的搭建这样一个列表产品不是一件很难的事情。
对于这样的系统,有两种实现方案:预先计算 和 实时计算。
预先计算的含义是提前遍历所有条件,计算出每个条件下的结果列表,对外使用的时候直接key-value查询结果即可。
实时计算指的是我们先把数据导入到一个列表搜索系统,每次查询时,使用查询条件去实时计算结果列表。
当然这两种方案都有自己的优缺点。
| 预先计算 | 实时计算 | |
|---|---|---|
| 优点 | 查询高效 | 节省储存,实时更新 |
| 缺点 | 浪费储存,更新是个问题 | 长尾,性能低下 |
当然每种方案的缺点都有对应的解决方案,这里只是指出有这样的问题,为下文打个基础。
二、第一代列表系统
第一代列表系统什么时候搭建的不是很清楚,使用的是预先计算的方案。
由于当时视频还没有统一数据输出系统,所以列表系统自己还储存了每个ID结果的资料。
大概15年的时候,由于结果资料越来越多,计算量越来越大,第一代列表系统的缺点爆发出来了:数据完全没法更新了。
当时面临的状况是知道问题是什么,但是开发也做不了什么,跑个数据,几小时跑不完。
于是计划做一个数据更新可控的列表系统。
三、第二代列表系统
在准备做第二代列表系统之前的半年里,部门中心的人员进行了大换血。
我由原先的视频资料维护业务线调到了对外服务数据输出业务线。
这个调整实际上相当于换了一个技术栈。
之前主要是资料维护系统,所以主要是做内部网站和数据维护,涉及复杂的前端技术(HTML,JS,CSS,CGI,MYSQL),后端技术 - PYTHON脚本,C++脚本。网站访问量峰值每分钟几个。
现在主要是对外业务逻辑,所以主要做网站和数据输出,涉及简单的前端技术(HTML,JS,CSS,CGI,MYSQL),后端技术 - c++网络服务,网络编程。程序访问量峰值每分钟几十万上百万。
不过这些都还好,当时我的信念是:不管要做任何东西,给我一个demo,就可以照葫芦画瓢做出想要的东西。当时可能不知道具体原理,但是东西可以正常跑起来。
扯远了,继续回到第二代列表系统。
在设计第二个列表系统时,有一个目标:快速上线。
搜索工具选型上使用了sphinx索引工具,这个在前面的《简单聊聊搜索》聊过了。
sphinx仅仅是一个索引工具,使用搜索的基本原理实现了最基本的功能,不具备企业级应用的条件。
但是sphinx的缺点在我们的目标面前,就显得可以忽略了,毕竟我们需要快速上线。
由于sphinx的简单,恰恰可以快速投入到生产环境中。
现在回想一下最开始看的列表使用场景,每个列表都有很多筛选条件,这样的列表有几十个,那筛选条件组合多达几十万个。
sphinx有个缺点就是不能灵活的加字段,因为sphinx的字段是和Mysql的字段一一对应的。
面对这个难题我想了一个方法把所有筛选字段放在一个mysql字段中,然后使用一种巧妙的方法规避掉了加字段问题又可以正确的搜索出数据来,当然自己明白,这样有很大的性能问题。
面对性能低的问题,我们采用上层加缓存的方法。
sphinx另一个缺点是自身的问题,它仅仅是个工具,原理是一个索引程序人工的生成索引,然后人工的把索引加载到一个搜索服务中。
这些生成索引操作和加载索引操作都需要自己进行控制。考虑到生成索引很耗时,为了容灾,我们对生成索引与加载索引进行了解耦。
具体是:有一批单独的同构的机器进行定时生成索引,搜索服务在另外的机器上,通过脚本定时下载加载索引。
架构设计还在讨论阶段,老板问了我几次是否可以上线了后,我对目标更明确了:先上线。
于是上层的缓存部分交给其他同事实现,下层的四个模块全部由我来实现,每晚彻夜编程,不到一周就实现了全部功能可以联调了。
这个印象比较深刻,因为那周末我要请假回家办理档案的事情(那时候档案还需要交管理费),周六早上的高铁,周五晚上走的很晚,最后还写了接口的联调文档。
回来后又完善了一下监控就投入到另外一个系统的优化改造去了(统一数据输出系统)。
这个系统的定位很明确:1. 快速上线 2.数据能够在小时级别 3.底层性能不需要很高,上层加缓存。
就这样这个系统用了差不多快两年。
在这两年里,由于列表配置较多,经常出现配置错误各终端列表不能出现白屏的情况。
但是由于列表的入口比较深,大家都不知道列表的存在,往往是白屏几天了,才有人意外发现问题找过来。
所以第二代列表在产品定位上是没有那么重要的,数据小时级别更新可以接受,偶尔白屏也可以接受的。
四、第三代列表系统
前面介绍了第二代列表系统有一个缺点:小时级别更新。
在15年16年的时候,不要说小时几倍的更新,即使几天白屏都没人care。
但是17年不一样了,列表被曝光出来的机会不同于往日,不仅仅白屏不能接受,数据更新慢也不能接受了。
虽然sphinx也支持实时更新的功能,但是容灾上不能被接受,最后选择使用ES实时搜索引擎重构列表系统。
这次ES底层为了做到实时更新,花费了不少时间进行架构设计与代码实现,现在进入测试阶段。然后遇到了列表数据测试的问题。
继续看这张图,筛选条件有五行,每行有很多列,这个条件组合多大几十万个,人工测试是不可能的。
于是我写了一个自动化测试对比程序,拉取筛选条件数据,然后枚举所有条件得到一个查询接口去拉取正式环境与测试环境的数据,进行对比。
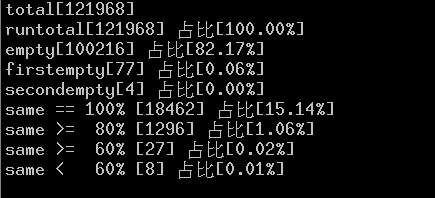
测试结果如下:
五、模糊的统计分布问题
看了上面的自动化测试结果,可以发现一个现象:大部分组合条件都是空数据,有0.07%的数据的相同度低于60%。
于是我对这些异常数据的分布比较感兴趣了。
后来我在我的圈子里和朋友圈里出了一道题:
好久没说话了,看到一道开放题,分析给大家,代表我还在吧。
淘宝买东西得时候,我们经常会使用条件过滤功能。比如买手机时,我们会选择品牌,颜色,内存等等。
在数学的角度来看,这个过滤变成了代数问题。
比如有4行,分别代表品牌,颜色,内存,像素。每行的列数可能不同,比如品牌有10个,颜色有四个,内存规格有五种,像素有六种。
这样这些规格得组合个数共有10*4*5*6=1200种。
但是实际情况是只有几十或几百种才能真正筛选出手机来,其他的都没有对应手机。
现在需要统计出大部分筛选出的手机得共同规格是什么,即规格条件分布。
比如有一百种组合条件可以筛选出手机,其中90个对应的条件都是颜色白色和内存64,其他10中比较分散。
则答案分两类:1.是90%的条件是白色和内存64,2.是 10%比较分散。
注:这个答案至少分布两类,至多分布五类。
输入:规格最多有6种,每种可能有2到20个选择。组合的结果已给出,枚举总数不超过100亿。
输出:上文提到的统计分布(这个是开放题,没有固定答案)。
后来也和同事聊聊了这个问题,最终我采用了最原始的方法:暴力枚举。
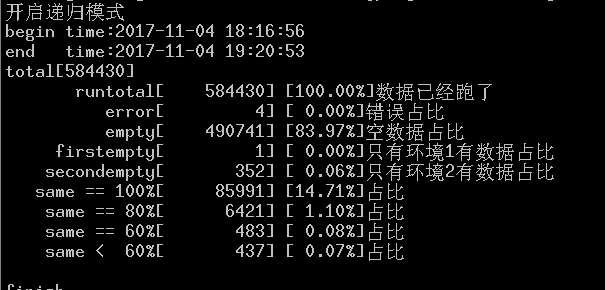
第一步:枚举递归算出所有的条件,保存条件路径,结果有一个值:是否为空。
根据上图可以看出,共有58万个条件路径,其中49万个条件路径的结果为空(每个条件路径有7个条件节点)。
这个操作最耗时,需要进行58万次网络操作拉取数据。这里我裸写了一个线程池库,开10个线程去跑数据。
后台接口后面是测试环境,所以线程数还不能开的太高,大概需要一个小时多才能跑完数据。
第二步:遍历所有结果为空的条件路径,然后遍历每个条件路径的节点,分别统计数据。
对于每个条件路径,需要分别统计一个节点为空的次数,两个节点为空的次数,三个节点为空的次数,四个节点为空的次数。
是的,计算量很大的,而且具体复杂度还不好计算,这里暂时使用时间成本来慢慢算吧。
具体统计结果如下:
先来看看数据不一致的统计结果吧。
可以发现93.7%的分布都是独播导致的,64.977%的奖项全部为空,我们根据容斥原理,最坏情况下也有58%的分布是独播加奖项全部条件下数据。
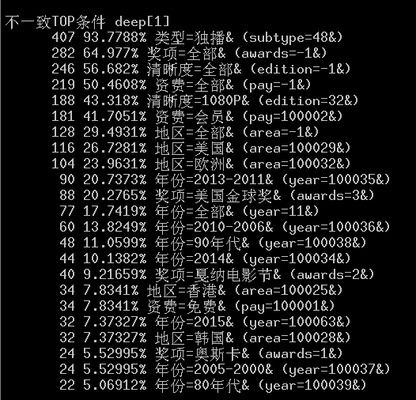
然后看一下两个条件组合的数据,和我们分析的完全一样,大头是独播和奖项全部,清晰度全部和资费全部也很可疑。
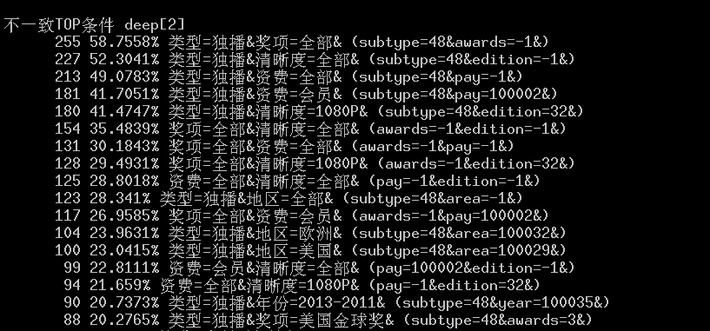
继续看三个条件的,可以针对自己的疑问进行解答。
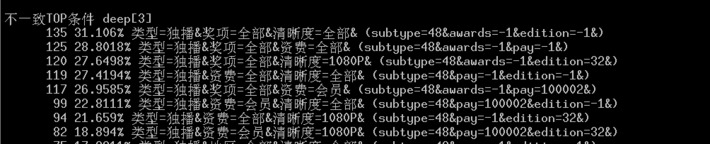
看到这里,就会有一个疑问:什么原因导致数据不一致度低于60%呢?
按照这个条件我点开看了看,发现这些条件大多搜索的数据很少,只有一两个,而测试环境换了搜索引擎,可以搜索更多的数据,出来了三四个。
以数据更全的新的搜索引擎作为参考,数据不一致度确实会超过了60%。
人工看了数据,发现这种情况算是合法的,不应该计算做不一致。
这其实也说明了我的算法有问题,我应该遍历正式环境里面的数据,检查测试环境是否存在。
回头想想原先正式环境数据在第一个,测试环境数据在第二个,这个程序的算法是正确的。
但是后来由于一些原因,正式环境和测试环境的位置我换了一下,就导致了这种情况的发生。
接下来看看数据为空的分布情况。
看到只有一个条件的结果时,我惊呆了。
这样就没法玩下去了。
清晰度只有两个,全部这个条件占差不多一半说明清晰度是无关的条件。
资费有三个,全部这个条件占三分之一,所以资费也是无关的条件。
我得算法没有过滤无关的筛选条件,这就导致无关的条件由于数量少,百分比就比较高,然后就排在了前面,也分摊了重点条件。
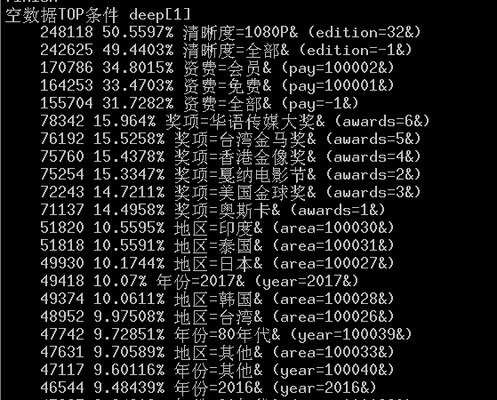
于是我的这个统计程序需要优化,主动过滤这种无关的又会分摊权重的筛选条件。
六、优化后的统计分布
过滤了无关的条件后,数据相关度强多了.
数据不一致的数量大大减少,几乎可以忽略了。
但是对于电影频道的空数据的结果却不是很理想。
分析TOP 20的结果,发现奖项与地区实际上是互斥的,比如只有同时选择了台湾金马奖和地区台湾才会有数据,只选择一个时比如地区美国肯定都是空数据。这其实也间接的说明了这个电影列表的筛选条件自身是有问题的。
看着有很多筛选条件,但是筛选条件自身是互斥的,那选择后结果肯定都是空数据了。
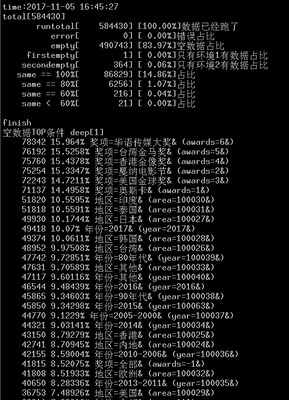
接下来我们看看电视剧的分析结果。
电视剧的枚举接口数量只有1万多个,有62%的数据为空,比电视剧好多了。
但是看了下面的结果发现还是地区选项大部分是空数据,为什么呢?
因为大部分的电视剧都是美剧和内地剧,所以选择台湾,日本,韩国这个条件大部分都是空数据了。
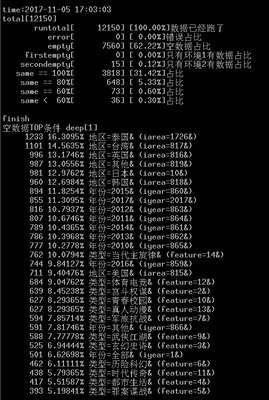
看了上面的统计结果,我心里面就清楚主要是哪些条件的组合导致数据为空的。
人工的检查一下这些条件,发现这样组合确实没数据或者几乎没数据,心里面也就有了底,算是符合预期了。
看来后续有必要分析下这些筛选条件的点击情况,我严重怀疑这个筛选条件根本没人去点击。
有了这个自动化测试程序和统计的数据,其实后面可以做很多事情。
比如上面有缓存,假设缓存可以储存全量数据,就可以使用这个自动化程序对数据进行缓存预热。
针对配置错误终端白屏问题,使用这个自动化程序可以校验数据分布的变化,突然空数据比例变大或空数据分布发生较大的变化,发出告警人工确认是否正常。
七、总结
这次切列表切换到ES搜索引擎,可以做到实时更新了。
但是对于性能问题,比sphinx好点,但是也没有好太多,毕竟长尾问题一直存在,那么多的计算量还是无法避免的。
后续的路应该会逐渐放在上层的缓存上,缓存强大了,缓存可以及时更新了,才能为性能低的底层保驾护航。
其实再看看预先计算和实时计算的缓存,两个之间有着很巧妙的关系,有共同点也有差异点。
好了,一写几个小时又过去了,所以有不对的地方欢迎拍砖。
对了现在开通了博客、公众号、算法小密圈、IT技术交流微信群。
要加微信群的可以加我微信,我拉大家进群。
比较好玩的算法放在小密圈发布。
欢迎大家加入看各种算法的思路。

长按图片关注公众号,阅读不一样的技术文章。

本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
