自己解析 Protocol Buffer,性能翻倍
作者: | 更新日期:
这些优化之所以有效,还是因为当初做了很多事情,实际做的那些事情并不需要的,那些其实就是无用功。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
一、背景
大概在两年前,我分享过我负责一个支持两级批量的缓存系统《每秒千万级别的量是重生还是炼狱》,后来介绍了 Protocol Buffer 《协议之Google Protocol Buffer》。
当时,我研究了一番 Protocol Buffer 其实有目的的。
那就是想看看自己的一些性能优化的想法在理论上是否可行。
当然结论肯定是可行的。
最近看着请求量越来越多,每秒已经好几亿了。
而且各种业务为了达到自己的 KPI,原先拉去 10 个数据的场景现在都是拉去 500 个数据。
暑假来了需要砸不少机器才能支撑住。
如果提前优化一番,那肯定可以节省不少机器。
所以这周末花费了 半个小时实现了自己解析 Protocol Buffer 的功能,并用来四个小时全方面压测。
从压测数据看效果明显,上线后效果确实非常明显。
这里将做的事情记录一下,应该很多系统都可以参考借鉴。
二、使用场景
世上没有银弹。
任何优化都是有前提的,即一个场景有瓶颈了,我们在这个瓶颈的前提下来做对应的优化。
而我这一次的优化使用的场景可以覆盖到两大类。
第一类是接入层、转发层类的服务。
第二类是通用的缓存层、一致性HASH路由层。
PS:定义:序列化即打包,含义是将结构化数据转化为一个字符串。
反序列化即解包,含义是将字符串转化为具体的数据结构。
对于第一类接入层和转发层,一般协议的固定包头上就可以得到想要的信息,然后不需要对请求包反序列化了,也不需要对回报反序列化了。
这个一般大家都直接就选择了性能最高的不解包直接转发的方案,优化空间不大。
而第二类,由于需要对请求包和回包进行反序列化才能取到协议里的数据。
此时,大多数流程是对请求包反序列化获取数据参数,然后进行缓存操作或者路由操作,最后将得到的数据组装到回包结构,序列化进行回包。
表面上看这个流程没有什么问题,但是深究下去,就会发现这里面就有很大的优化空间了。
三、优化细节
比如对于我这个服务,是一个批量拉去数据服务。
请求协议和回报协议如下:
struct StReq{
int iDataType;
vector<string> vecKeyList;
vector<string> vecFieldList;
};
struct StField{
string strField;
StInfo stInfo;
};
struct StKey{
string strKey;
vector<StField> vecFieldInfo;
};
struct StRsp{
int iErrNo;
string strErrMsg;
vector<StKey> vecKeyInfo;
};
请求包一般比较小,而且需要参数检查,收到包后解包是不可避免的,但是这个也不怎么消耗性能,所以暂时可以忽略。
对于返回包,可以发现比较复杂,数组里面还有数组,最终的值还是一个结构,里面有什么也是未知的。
如果我们对返回包全部进行反序列化,如果数据非常多的话,对性能影响是非常大的。
而作为通用的缓存层或者一致性HASH路由层,其实只关心部分数据,至于其他数据,其实我们只需要能够原封不动的储存与返回就行了。
具体来说,对于一致性 HASH 路由层,是对 KEY 进行固定路由了。
所以对于KEY的具体资料,这一层是不关心的,只需要原封不动的转发即可。
所以如果协议能够改成下面的样子,性能就会非常高。
struct StKey{
string strKey;
string strFieldListInfo;
};
struct StRsp{
int iErrNo;
string strErrMsg;
vector<StKey> vecKeyInfo;
};
但是这时候就需要修改协议,变更成本蛮高的。
于是我就想着自己实现手动来解析这个 Protocal Buffer 协议了,就可以做到对回包数据进行特殊处理。
对于不关心的数据,不进行解包,只解析自己关心的数据。
对于通用的缓存层,其实有类似的情况,不过是stInfo这一层不再关心。
同样可以自己手动解析协议,不解析stInfo,直接当做字符串处理即可。
四、优化效果
对于一个优化,还是需要看实际效果。
因为有可能这个地方虽然是可以优化,但是不是关键瓶颈,优化了就会和没优化一样。
这次优化的效果相当明显,大部分请求是30个key和30和field,这种场景下CPU直接降了一半。
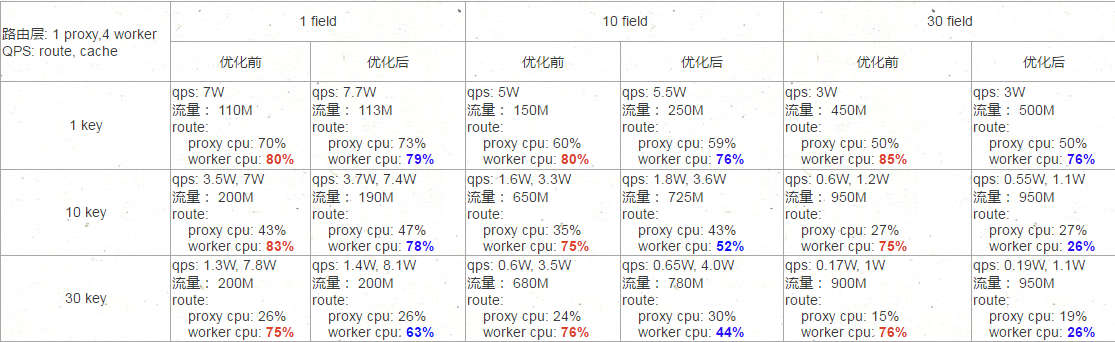
PS:流量满了?可以换万兆网卡的。
关键是相同的CPU算力,现在可以处理更多的请求量了。
五、最后
当然,这里优化的主要是一致性HASH路由层。
对于通用缓存层后面也会进行优化,不过那个比这个复杂的多,效果应该也没有这个明显。
以后有时间再进行吧,也不知道以后是多久了。
我现在之所以要做这个优化,是因为前段时间做了另外一个优化,效果非常的好。
现在很多人拉取资料,拉了很多数据,实际大部分用不到,这里用不到的就是无用功,CPU算力被白白浪费掉了。
基于这样的逻辑,前段时间我做了一个实验,找一个拉数据量很大的业务,抛出这个问题,让他们进行优化,把不需要的字段改掉。
那个业务当时是反对的,说拉的字段都在用呀,或者我也不知道哪些字段需要用呀,到最后很痛苦的去梳理,把不需要的字段一个个去掉。
最后一看效果,当时的痛苦优化种下了种子,后来开花结果,CPU的负载也是直接减半了。
这些优化之所以有效,还是因为当初做了很多事情,实际做的那些事情并不需要的,那些其实就是无用功。
这些无用功在白白浪费CPU算力,在白白浪费网卡的流量。
当我们把这个无用功优化掉,性能就会得到极大的提升。
-EOF-
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
