两个小优化性能翻三倍
作者: | 更新日期:
谁痛谁优化。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
一、背景
之前提到,我负责一个通用的数据输出系统。
其中一个功能是聚合各种数据,对外通过一个接口就可以全部输出想要的数据。
而最近遇到一个问题,底层有个数据源总是超时,从而触发了告警。
这个数据源的数据是通过服务动态计算的,可能计算量比较大,需要分析下什么原因,来解决超时问题。
我找到对应的两个负责人,他们在忙着做中台。
问这个数据能否下线,回答不能下线。
问这个数据源重要不重要,回答很重要。
问这个数据有什么影响,回答是这个数据挂了,那相当于我们的网站就挂了。
问什么时候修复一下,回答是找时间看看。
问一次,回答是找时间看看,一周就过去了。
再问一次,回答还是找时间看看,又一周过去了。
事不过三,于是我便说代码的git发一下,交给我吧。
二、初步分析
初步看了下代码,发现问题很大:各种套娃 copy,各种无效计算,各种低效算法。
在《定位高性能服务耗时抖动》文章中我提到,我实现了一个耗时统计的功能。
这里刚好可以哪来看看时间都消耗在哪里了。
这个服务逻辑其实很简单。
收到请求后,第一个网络操作去拉取基本信息,第二个网络操作去扩展列表的数据。
最后计算出一个列表数据。
第一个网络操作加数据处理我使用ReadUnion计时。
第二个网络操作加数据处理使用SetMtTaskList计时。
剩余的计算列表数据使用end计时。
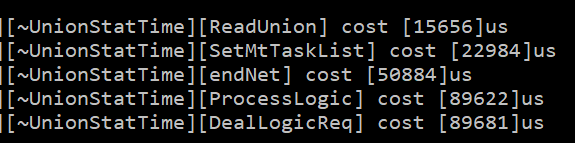
可以发现
第一个步骤使用了 15毫秒。
第二个步骤使用了 23毫秒。
第三个步骤使用了 51毫秒。
其中第二个步骤大部分是不需要计算的,可以提前判断一下。
即使可以提前判断是否需要计算,那就计算一下。
毕竟省下来的就算白赚的。
这个道理大家都懂,这里就不多说了。
而第三个步骤使用了套娃copy,可以进行优化。
三、禁止套娃
啥是套娃copy呢?
看看代码就知道了。
Result rresult;
for(...){
List list;
for(...){
Data data1;
list.push_back(daat1);
}
rresult.push_back(list);
}
而我们做的就是不做复制操作。
比如高级的做法是使用emplace_back强制swap。
一般的做法是先分配内存,直接在内存上写结果。
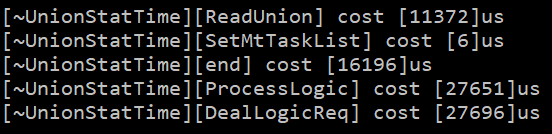
优化效果也很明显,仅看 end的计算部分,时间变为原来的三分之一。
四、最后
好了,先介绍这两个优化。
这里面其实还有很多值得优化的地方,比如大量的json操作,大量的线性查找等等,都可以优化的。
下周有时间了,继续优化。
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号:tiankonguse
公众号ID:tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
