GO map 源码实现分享
作者: | 更新日期:
组内进行了一次分享。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
零、背景
2022 年 1 月 7 日,周五,下午给团队内进行了 Go map 源码实现分享。
这里记录下分享内容。
大家好,我是 tiankonguse。
今天,作为一个没怎么写过 go 代码但 CR 过不少 go 代码的初学者,给各位分享下 Go 的 map 源码实现。

分享大概分为 5 部分:map 语法、HASH 算法、扩容算法、增删改查、迭代器。

一、map 的语法
第一部分,介绍下 map 的语法。
大概分为 6 部分,分别是创建、赋值、删除、取值、查找、遍历。
大家可以看下是否有遗漏。

二、HASH 算法
第二部分,介绍下 HASH 算法理论知识。
对于 cpp 的 map,是通过红黑树实现的。
当然,c++11 也支持 hash map,叫做 unordered_map,是通过 hash 实现的。
对于 go ,则是通过 hash 实现的。
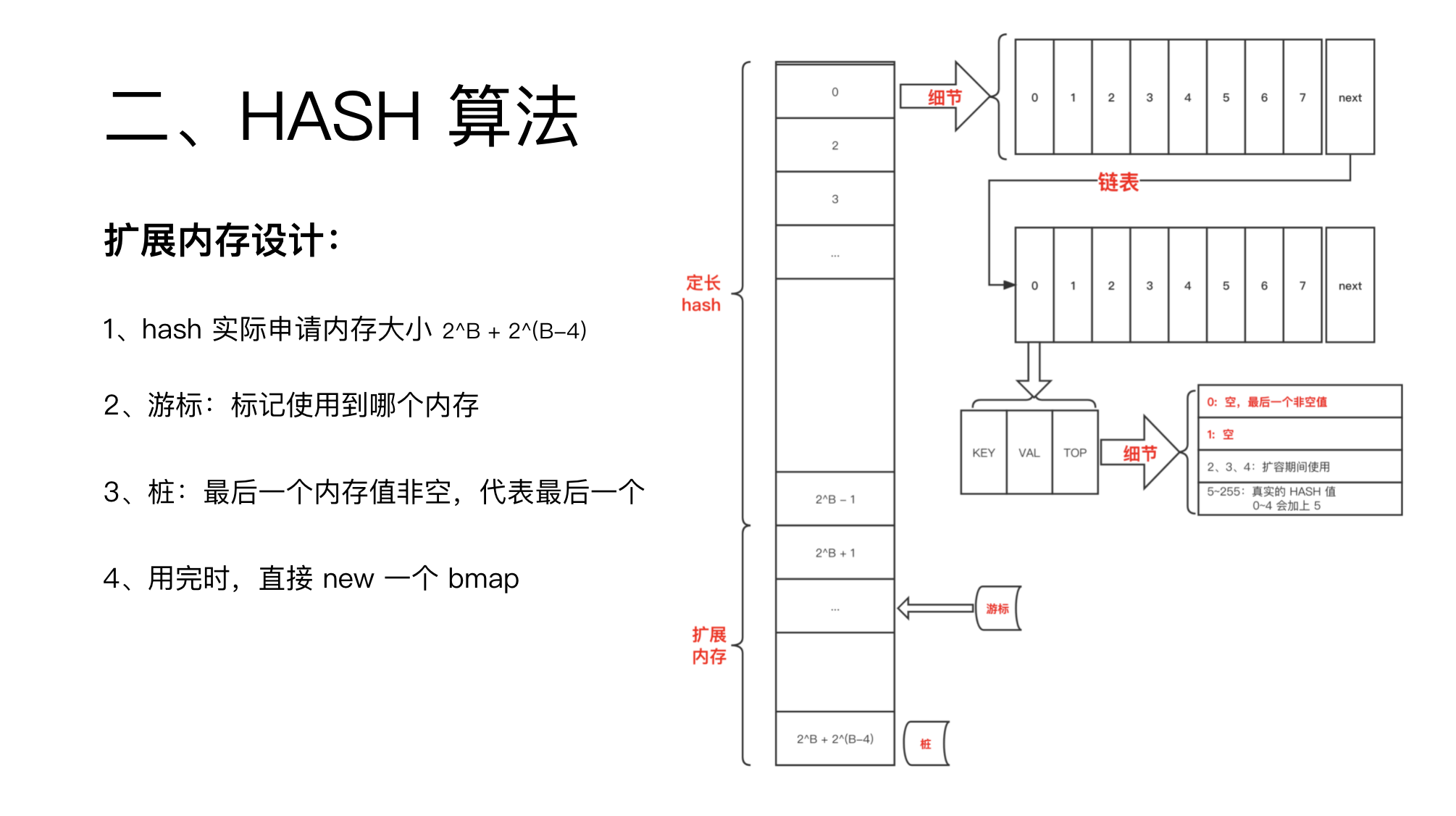
hash 的本质是一个定长数组。
长度一般是 2 的整数幂,这样就可以通过位操作来代替取模操作,提高效率。
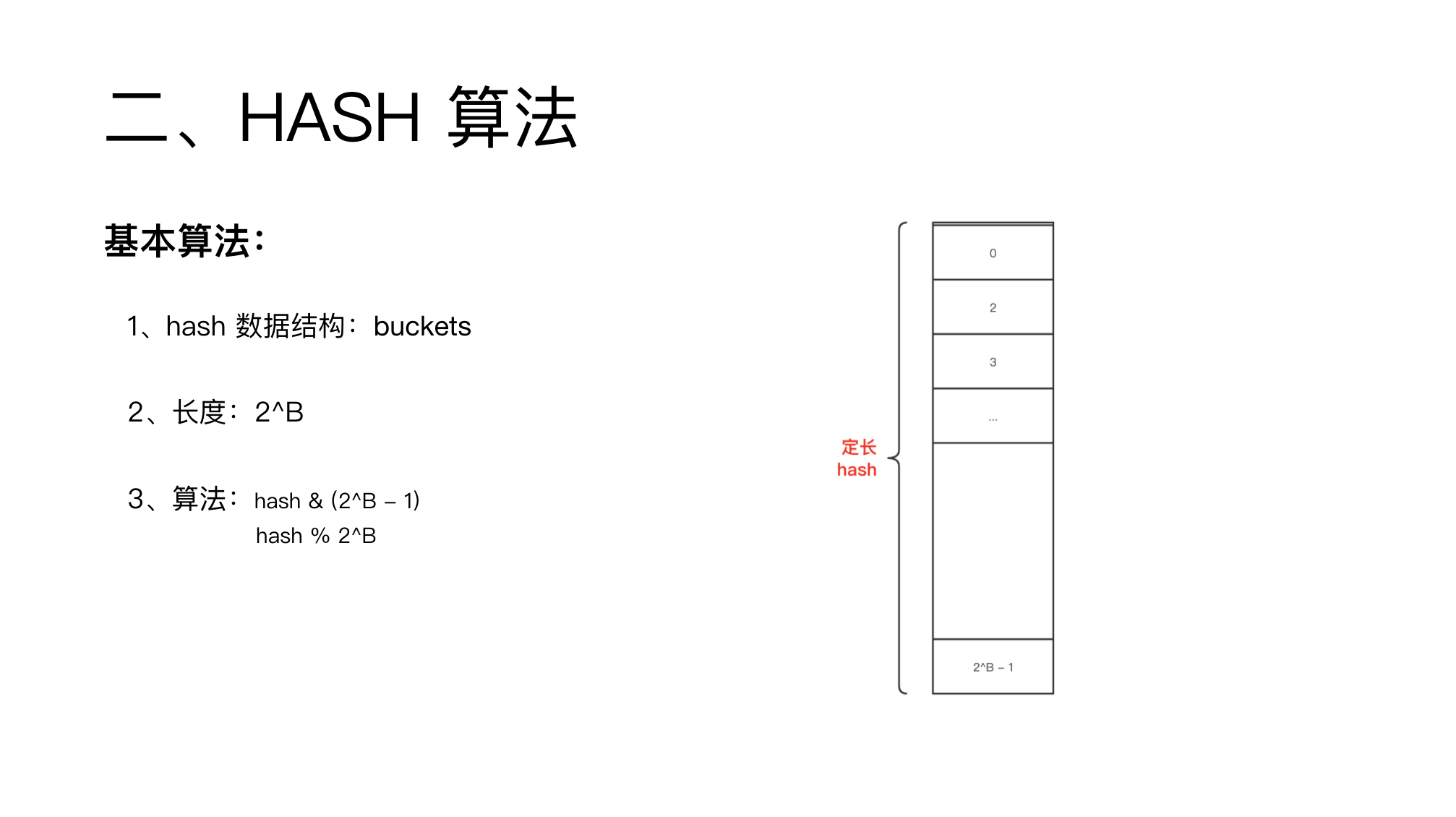
定长数组,hash 冲突了怎么办呢?
go 这里第一层防冲突设计是,数组里不再储存一个元素,而是储存的 8 个元素,称为 bmap。
bmap 是顺序插入与查找。
所以为了提高查找性能,每个位置还储存了一个 1 字节的 hash 值,用来快速比较。
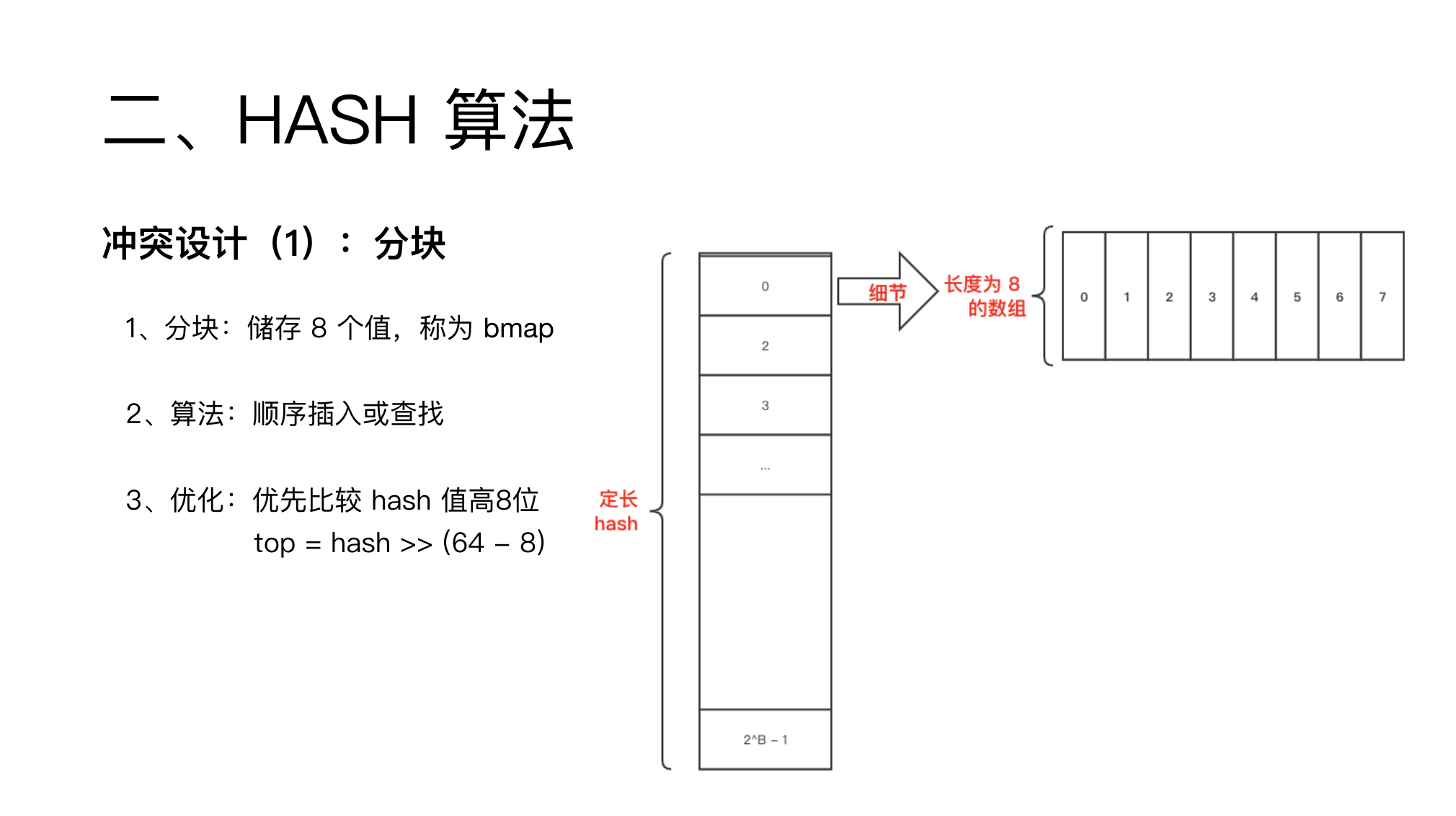
如果 8 个元素都满了怎么办呢?
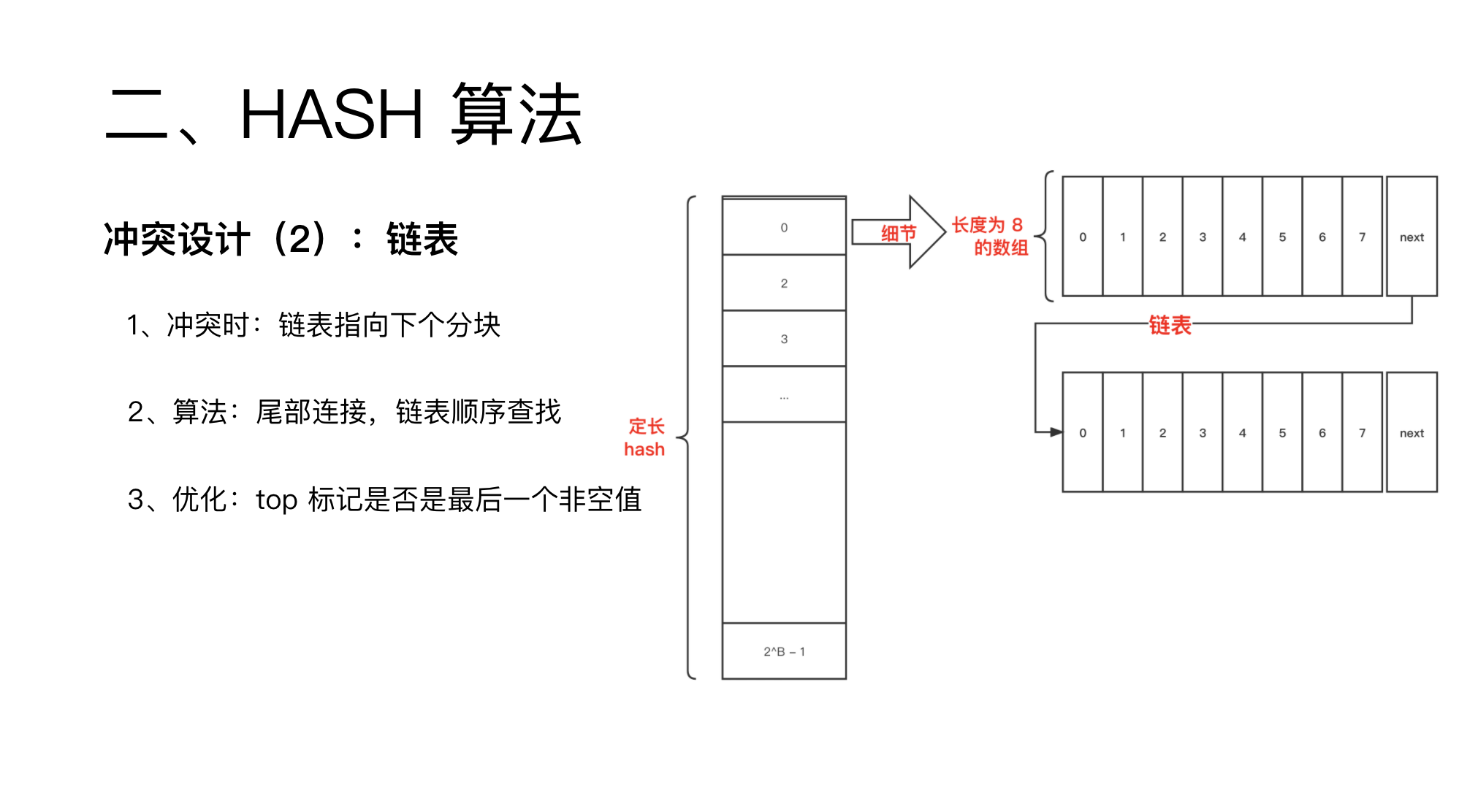
那就是通过链表连接起来。
参加过 ACM 的同学应该比较熟悉这个,就是常见的分块算法。
有链表了,bmap 就需要一个 next 指针来指向下一个 bmap。
由于是链表,查找依旧是串行的,极端情况下性能会退化到 O(n)。
当然,这里还有一个优化,记录最后一个非空值。
这样链表循环到这里就没必要循环了。
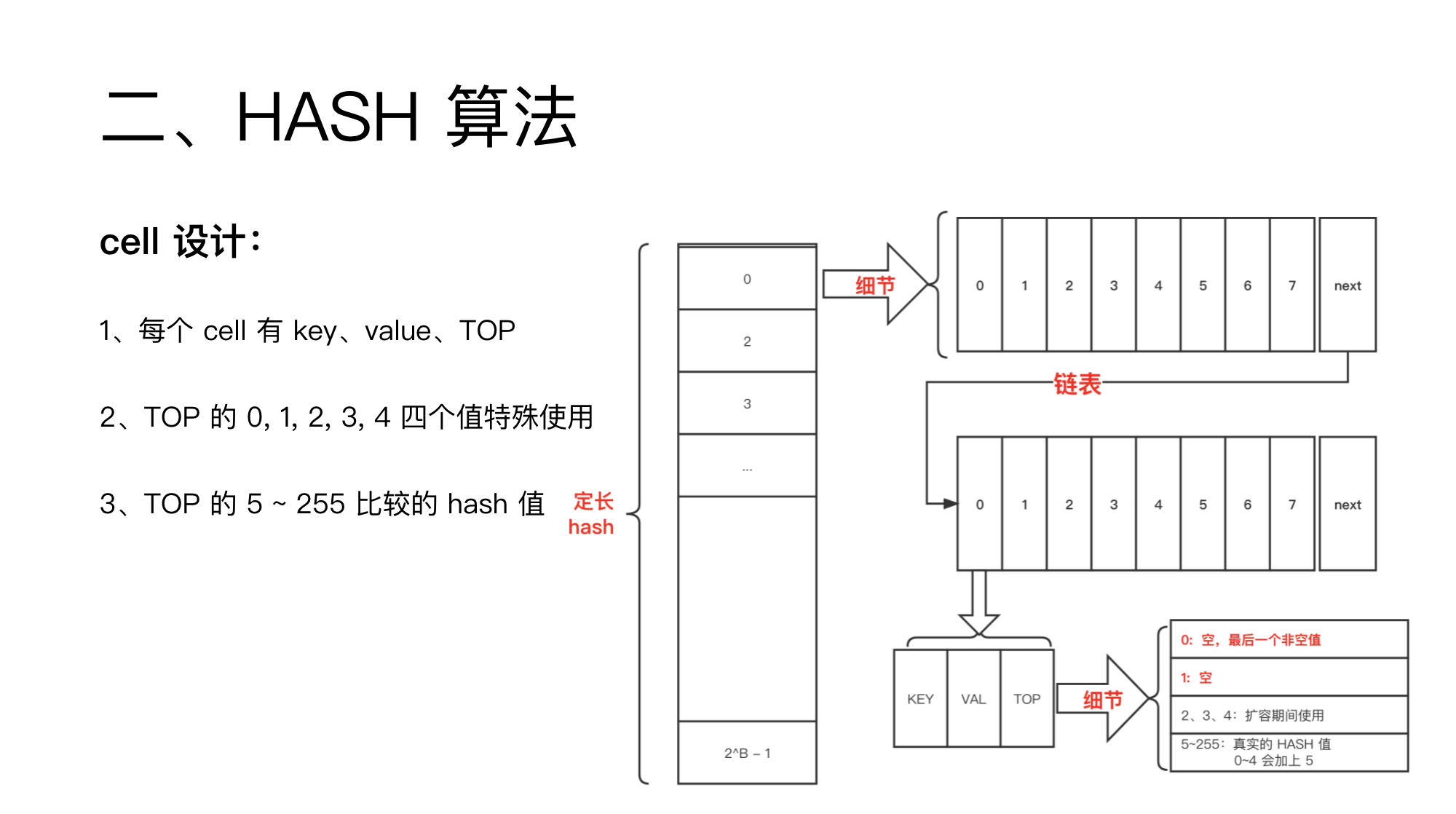
bmap 里储存了 8 个元素,每个元素称为 celle,储存三个值:key、value、TOP。
前面提到 TOP 储存的是 hash 值,还提到 TOP 标记为最后一个非空。
这里,TOP 同一个数据就有两个含义了,这在设计上算是存在二义性。
那这个二义性怎么区分吗?
值 0~4 用来当值标记。
0 代表最后一个非空。
1 代表普通空值。
2~4 扩容的时候使用。
5~255 用于储存 HASH 值。
对于 HASH 出的数字,如果值是 0~4,就会加上 5。
所以,对于 5~9 这几个数字,冲突的概率是 10~255 这些数字的二倍。
对于 bmap 的设计,理论上应该按右图的方式来设计,但实际是左图那样。
思考题:请问 go 为什么这样设计,有什么好处?

元素的内容结构了解了,接下来思考另外一个问题。
思考题:冲突需要申请新的 bmap 时,是如何申请的?
答案是,与 hash 数组一起,预先申请了 2^(B-4) 个 bmap。
这样,就可以优先使用预先申请的内容,用完了在去 new 。
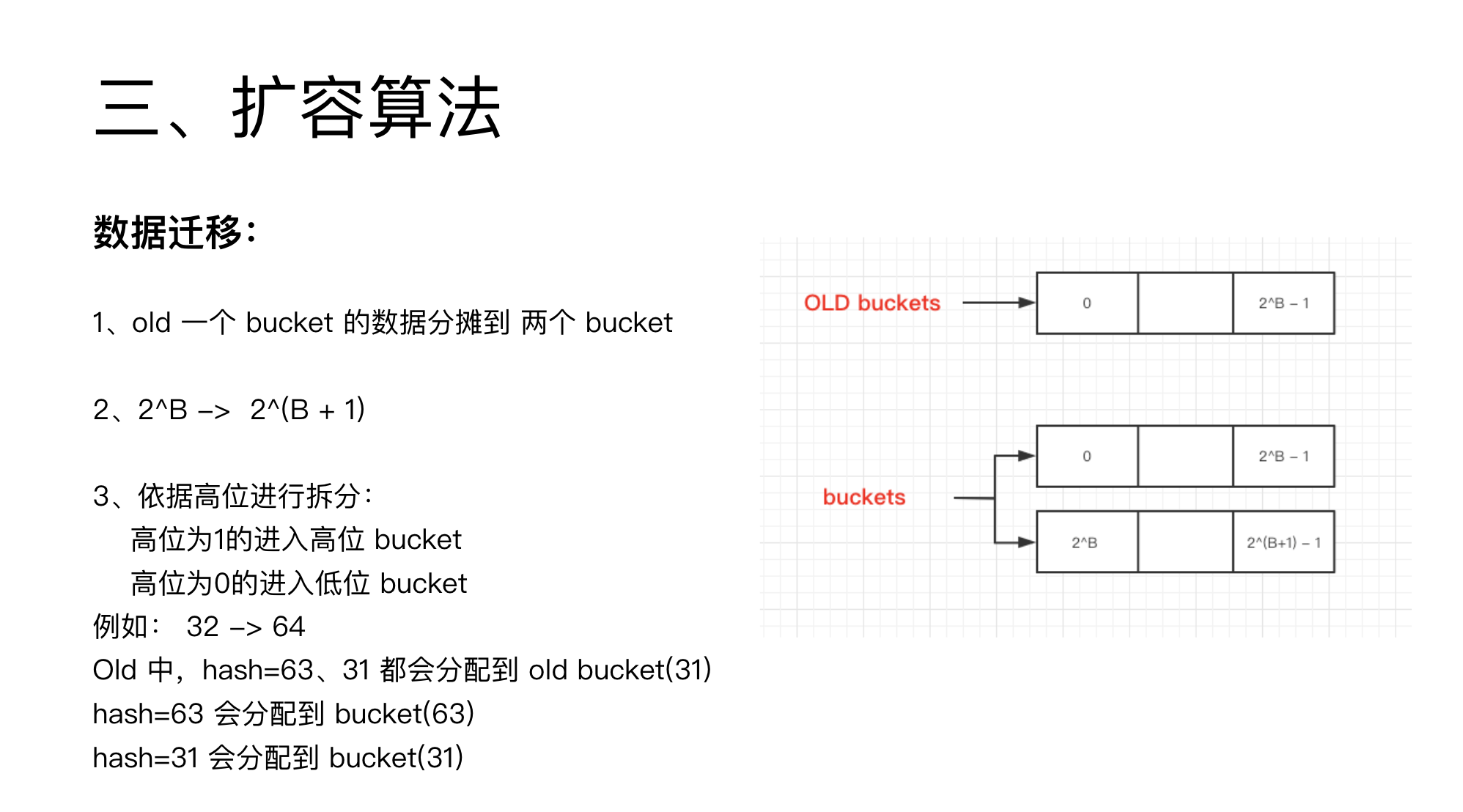
三、扩容算法
上面了解了 HASH 算法的设计,接下来了解下扩容算法。
提起扩容算法,那就需要有一个扩容策略,即什么时机来扩容。
这里有两个策略。
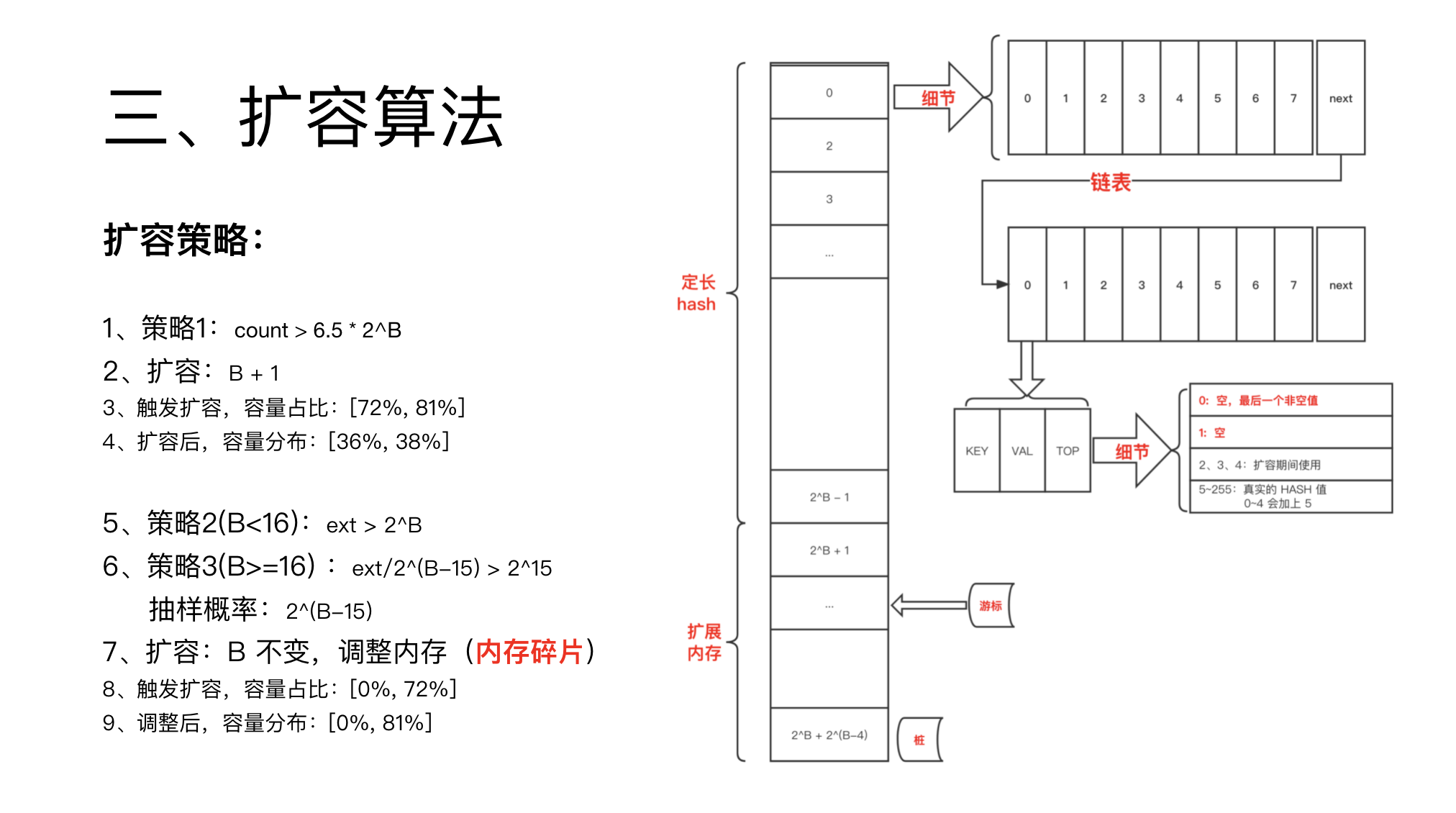
第一个是容量使用率策略,满足 count > 6.5 * 2^B 时扩容。
触发这个策略时,HASH 中的元素比较多了,冲突的概率很高了,扩容比较合理。
此时, B 会加一,即内存翻倍。
第二个是额外申请的 bmap 个数大于 2^B 时触发扩容。
触发这个策略时,说明 HASH 先申请了大量 bmap,之后又都删除了,存在大量空洞与内存碎片。
此时 B 不变,只进行内存整理。
前面了解了 HASH 算法与扩容策略,现在就可以了解下 GO 里面 map 的数据结构了。
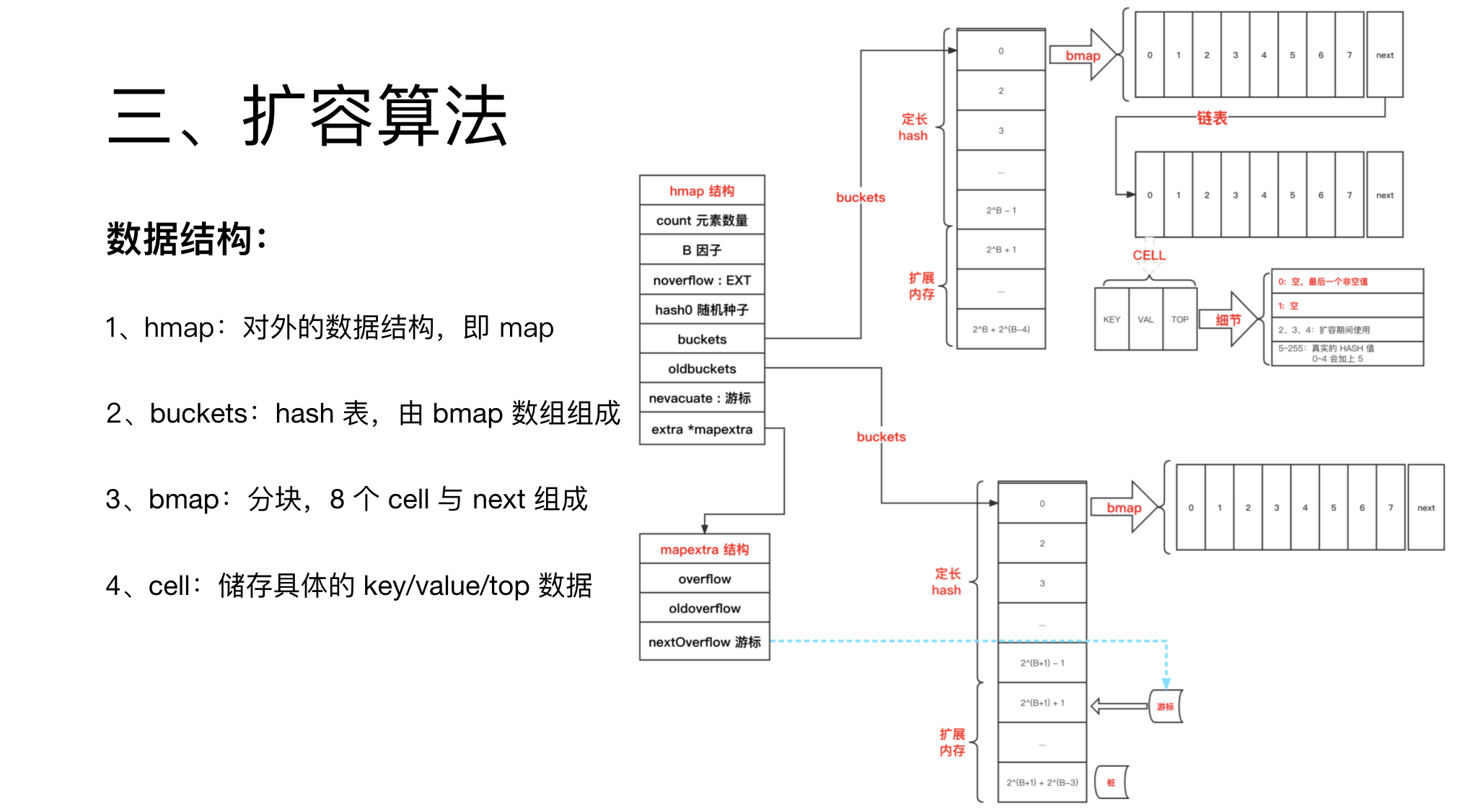
map 主要是 hmap 这个数据结构。
hash 表称为 buckets,由 bmap 数组组成。
扩容时,就存在两个 buckets,数据会慢慢迁移,后面会讲解如何迁移。
bmap 就是一个分块,由 8 个 cell 组成,当然还有一个 next 指针指向下一个 bmap。
cell 储存具体的 key、value、top信息。
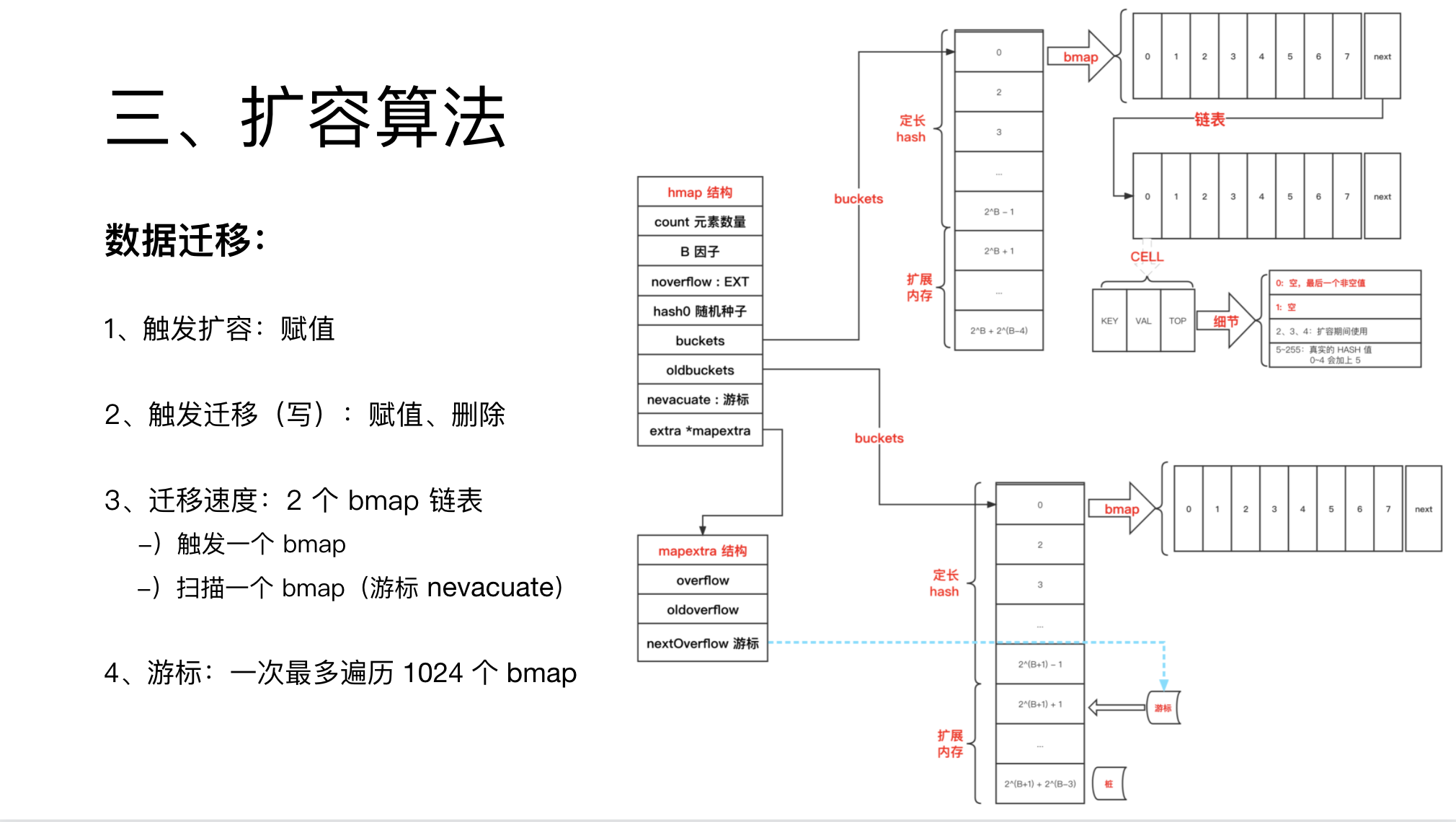
首先,只有插入元素时,才会触发扩容。
数据迁移与 redis 类似,采用分摊算法,分摊到各个操作上。
具体来说,只有赋值与删除的时候,会触发迁移,读不会触发迁移。
既然是分摊迁移,就存在一个迁移速度的问题。
一次迁移就会迁移一个 完整的 bmap 链表。
每触发一次,会迁移两个链表,一个是当前命中的 bucket,另一个是扫描的游标。
另外,如果 buckets 数组有大量空值时,游标会尝试寻找下个值,最多寻找 1024 次。
数据迁移的时候,要么是相同大小的 hash 进行内存整理,要么是内存翻倍。
内存整理比较简单,实现上也是内存翻倍的子集。
所以这里主要介绍内存翻倍是如何实现的。
由于 hash 大小是 2 的整数幂,内存翻倍后,就可以得到一个奇妙的性质。
即旧 buckets 的元素,偏移量不妨假设是 k,只可能到到达新 buckets 的两个位置。
即要么还是 k,要么是 k+2^B。
这个也很容易解释,在 k 的数字都是模 2^B 的余数。
现在需要模 2^(B+1)。
余数最低的 B 位结果不变,现在增加了第 B+1 位,要么是 0,要么是 1。
如果是 0,则结果依旧是 k,位置不变。
如果是 1,则结果是 k+2^B,位置就到 k+2^B 了。
有了这个性质,go 迁移的时候还做了一个算法保证:如果没迁移,数据一定在旧 buckets 里,如果迁移了,数据一定在新的 buckets 里。
这样,在增删改查的时候,就可以判断旧的 bucket 是否迁移,来判断读新旧哪个 bucket。
四、增删改查
上面介绍了原理,接下来就简单看下增删改查的代码吧。
先介绍简单的取值操作,即查。
看名字是 mapaccess1, 名字起得一点都不专业。
逻辑还算简单。
1、空值直接返回。
2、根据 B 计算出 hash 偏移量。
3、如果在扩容中,判断是否在旧 hash 中。
4、之后就是循环链表与 bmap 来查找了。

然后是介绍查找操作。
名字是 mapaccess2,可读性一点都不好。
而且看代码与 mapaccess1 有大量的冗余重复部分,这种设计在公司肯定会被骂的。
逻辑与第一个几乎一模一样,空值返回、计算偏移量、判断是否在旧 hash、循环查找。

之后是赋值操作,代码也差不多。
不一样的地方是这里会先判断是否在迁移数据,是了就触发一次迁移数据。
之后就是查找元素,如果没找到,就判断是否可以触发扩容策略。
另外,由于没找到,需要申请一个新的 bmap,把链表串起来,之后就按找到处理了。
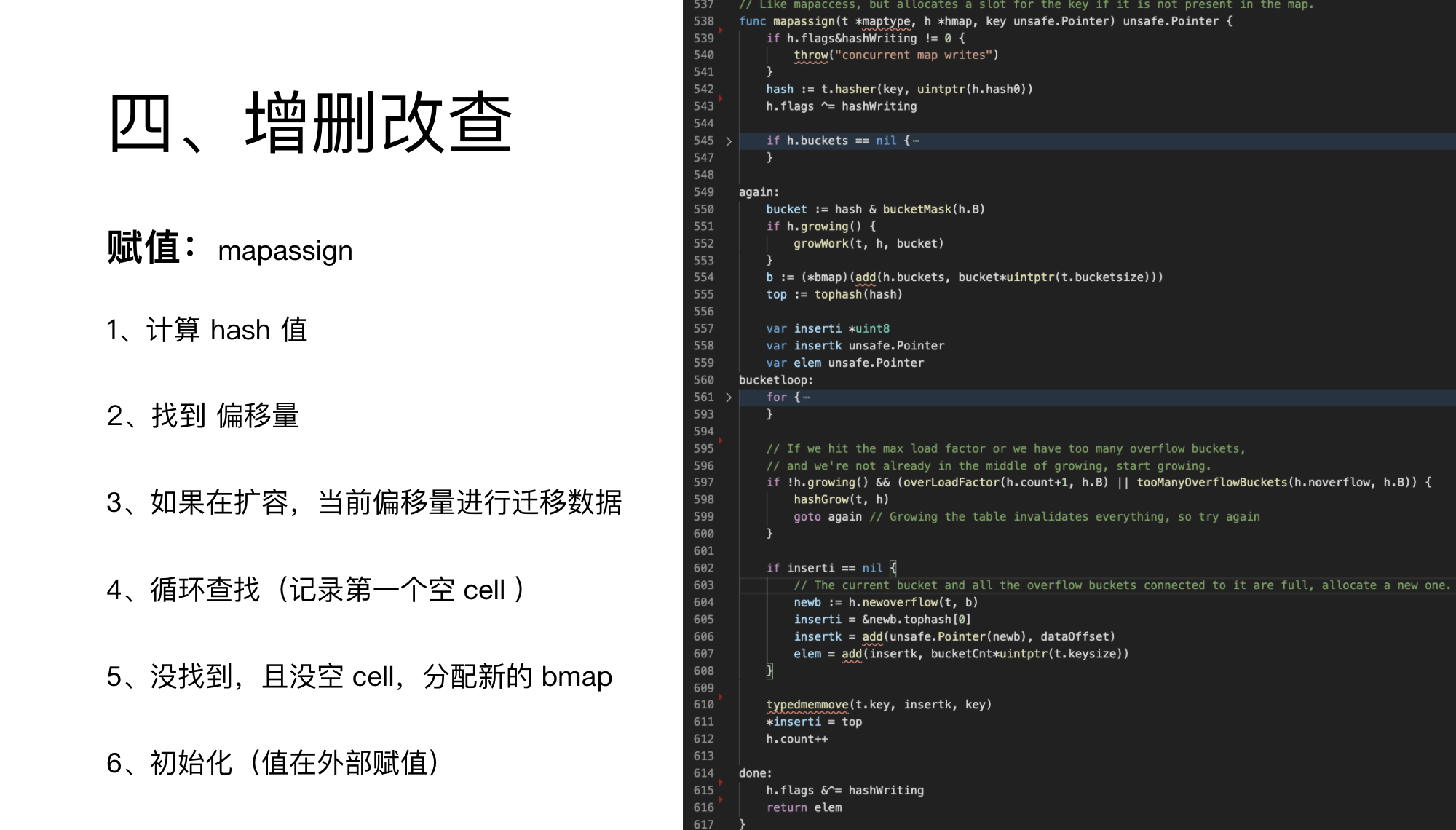
赋值的查找逻辑稍微复杂点,单独介绍下。
这里循环与上面的取值、查找不一样了。
第一次写的是死循环,第二次是循环 bmap 的 8 个元素。
由于是赋值,可能不存在。
所以需要记录下第一个空节点,当没有找到时,用于插入数据。
除了这两处不一样外,其他的都不变,不需要展开介绍了。

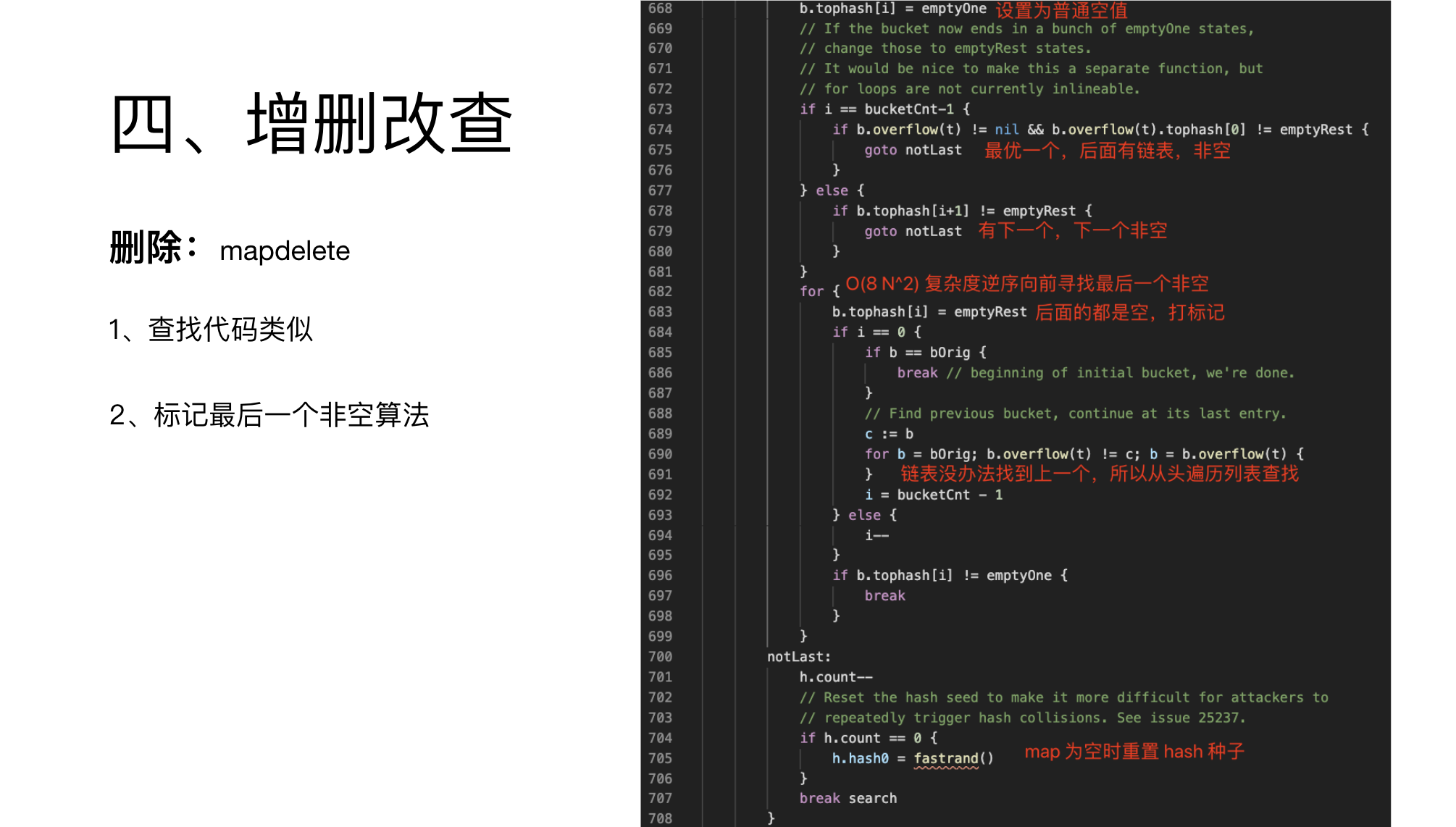
对于删除,逻辑与前面的差不多。
这里只有一个地方比较有意思,单独介绍下。
前面提到,链表在 top 里储存了一个标记,即是否后面的都是空值,使用 0 标示。
初始化的时候,所有值都是 0,所以从前到后,第一个值就可以判断出来后面的都是空。
随着插入,后面的自动变为第一个空。
而删除的时候,如果处于中间,仅标记为普通空值,用 1 来标示。
如果是最后一个删除了,前面可能有空洞。
此时就需要向判断,前面的是否也需要标记为 0 。
这个向前判断的算法很有意思。
如果在 bmap 内,就可以使用下标偏移计算。
如果处于 bmap 第一个,就需要找到链表的上个 bmap。
大家都知道,链表只有一个 next 指针,那怎么找到上一个 bmap 呢?
答案是从链表头部循环查找。
这样最坏情况下,复杂度是O(8 n^2)
五、迭代器
前面了解了 map 的增删改查,最后来了解下 map 的迭代器。
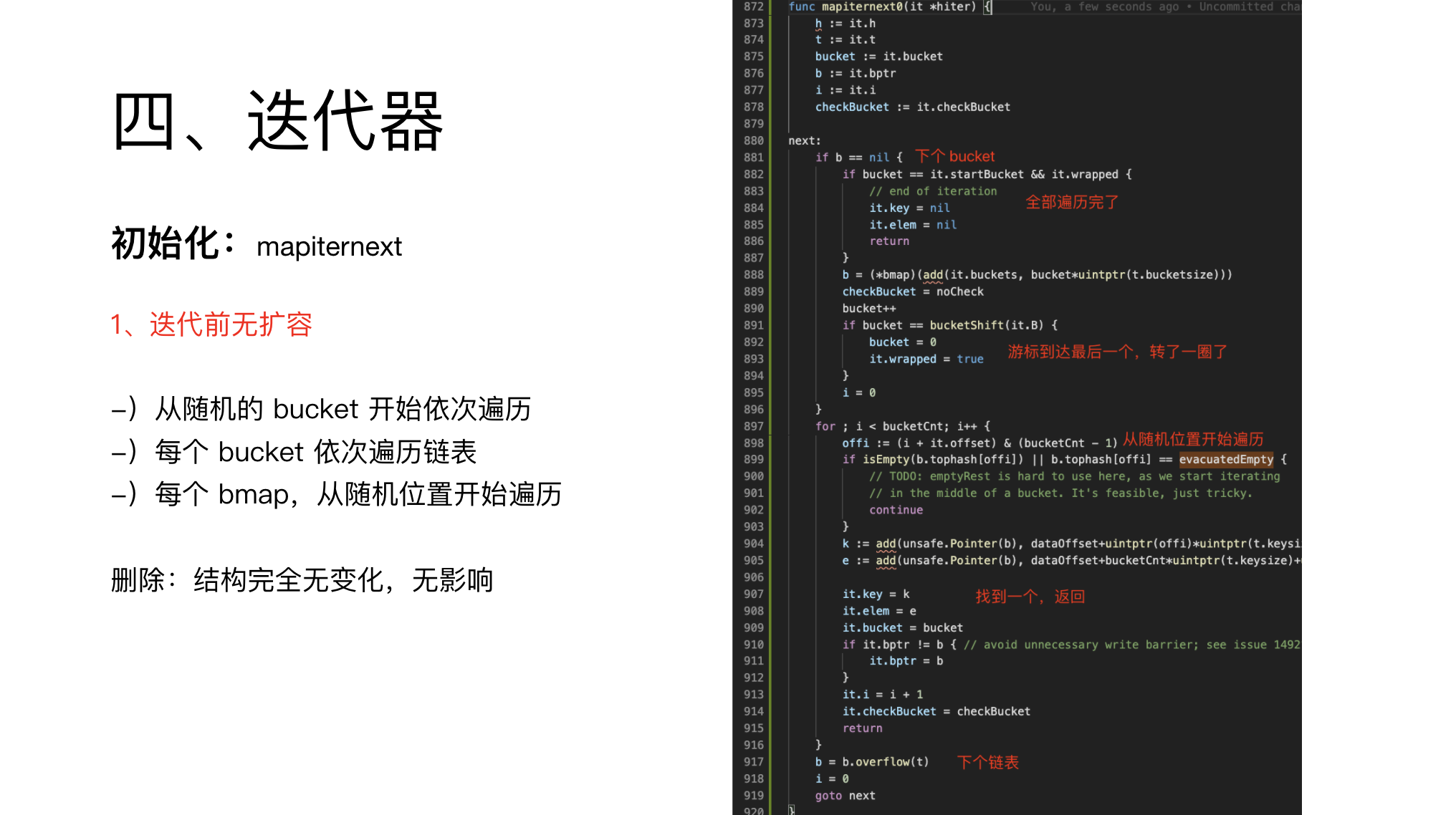
首先是迭代器的初始化,比较简单,就是一些赋值操作。
需要留意的是,迭代的位置是随机的,即 hash 的偏移量与 bmap 的偏移量都是随机的。
这在语言层面,就让用户知道,迭代器的输出是随机的,不要利用 map 的算法以及结果特征来做什么事情。

对于迭代器,这里重点介绍四种情况下迭代会怎么样。
1、无扩容
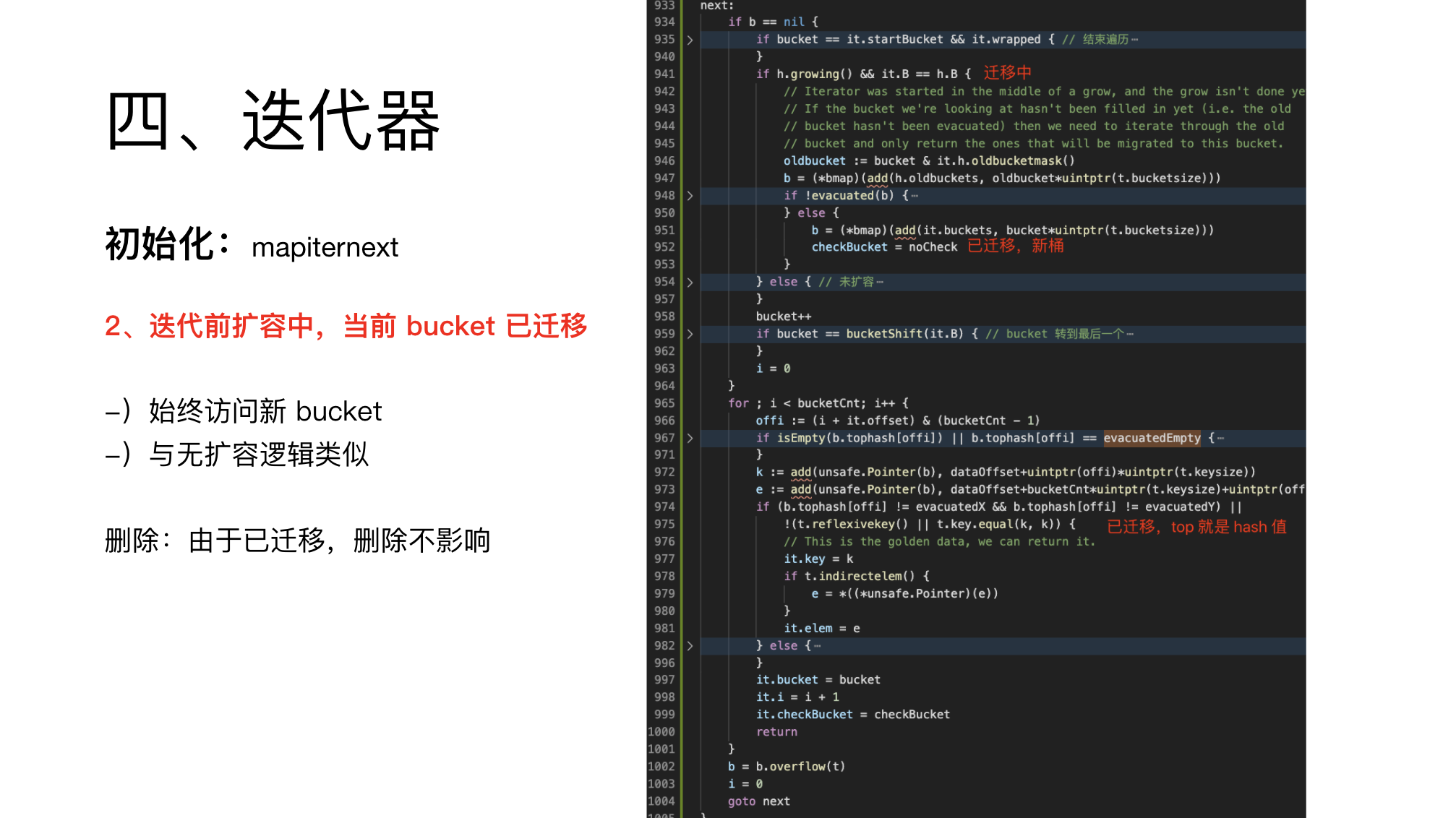
2、扩容,此 bucket 已迁移
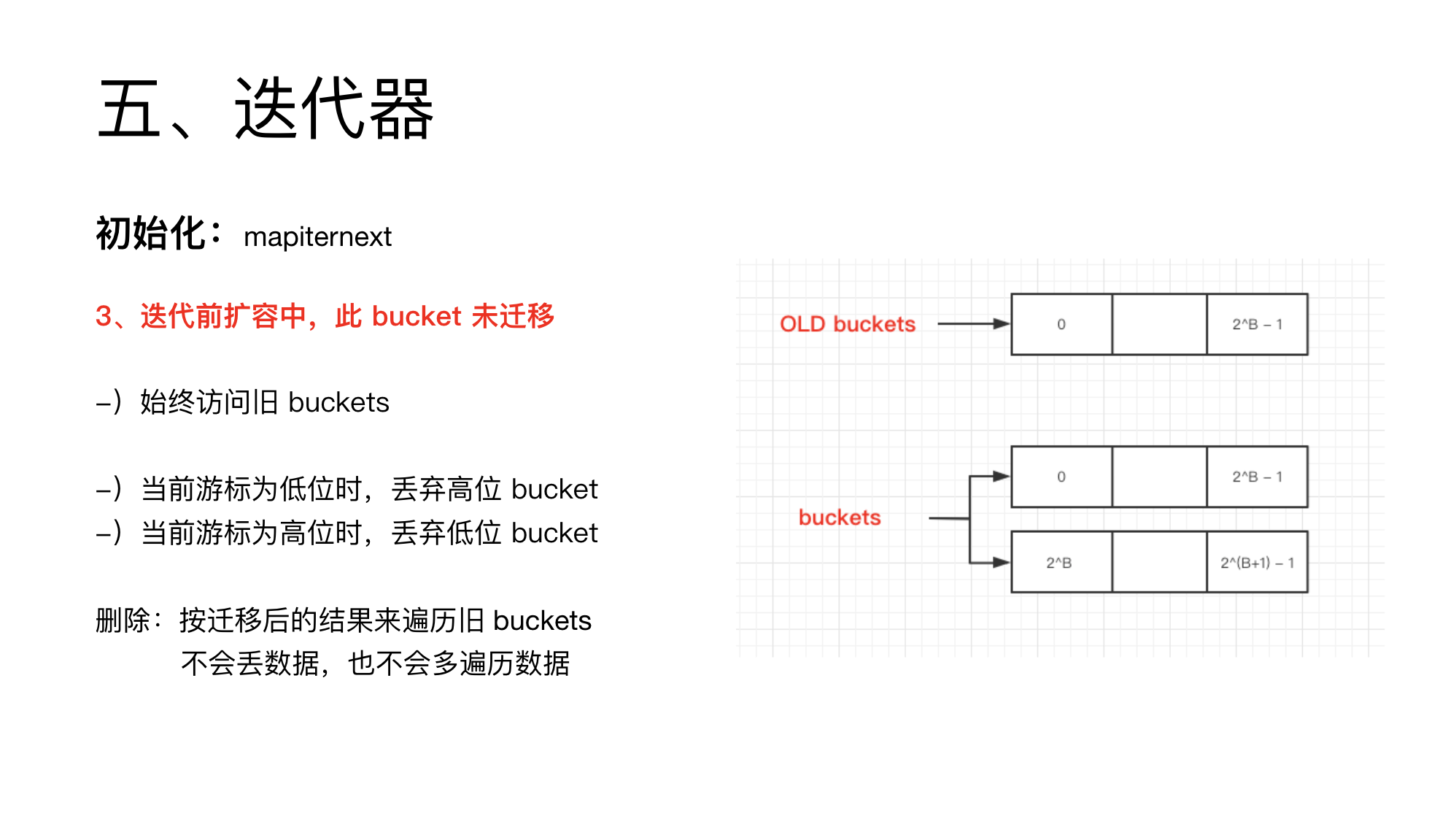
3、扩容,此 bucket 未迁移
4、扩容,此 bucket 迭代中迁移

第一种情况是无扩容。
由于 hash 的位置是随机的,所以使用 wrapped 变量来判断是否转了一圈,再结合 startBucket 来判断是否迭代完成。
其他的就就和之前的都一样,正常循环即可。
第二种情况是扩容中,但是当前 Bucket 已扩容。
这时只能访问新的 Bucket,所以和无扩容逻辑完全一样。
另外,由于已完成迁移,删除也不影响迭代结果。
第三种情况是扩容中,当前 Bucket 未迁移。
由于未开始迁移,所以只能访问旧的 Bucket。

这里面有一个很有意思的性质:迭代的顺序是按迁移后的结果迭代的。
什么意思呢?
如下图,还是之前介绍的 二进制完整幂的性质,迁移只会到达当前位置或者加 2^B位置。
假设当前旧位置是 k,在新的 Bucket 中,k 与 k+2^B 位置的元素,都是从旧 bucket 的位置 k 拆分出来的。
如果当前的迭代值是 k,这里就只会输出迁移后,新 bucket 中 k 位置的值。
如果当前的迭代至是 k+2^B,则这里只会输出迁移后,新 Bucket 中 k+2^B 位置的值。
为啥要这样做呢?
这就要介绍迭代器内的一个神奇操作:删除不影响迭代。
就是因为有上面的算法保证,迭代器内删除才可以正常。
很妙的设计,但是工程上算很差的设计。
算是算法实现彻底被绑死了。
最后一种情况是,迭代器处于扩容中,当前 Bucket 本来是未迁移,迭代过程中变为已迁移。
这种情况在好的设计上,不应该存在的。
但是由于 go 允许迭代过程中进行删除,这种情况便发生了。
恰好,上一种情况介绍了算法实现的结果:按迁移后的结果迭代。
所以,这里从未迁移变成已迁移也不影响迭代结果。

最后,还有种情况,也介绍下。
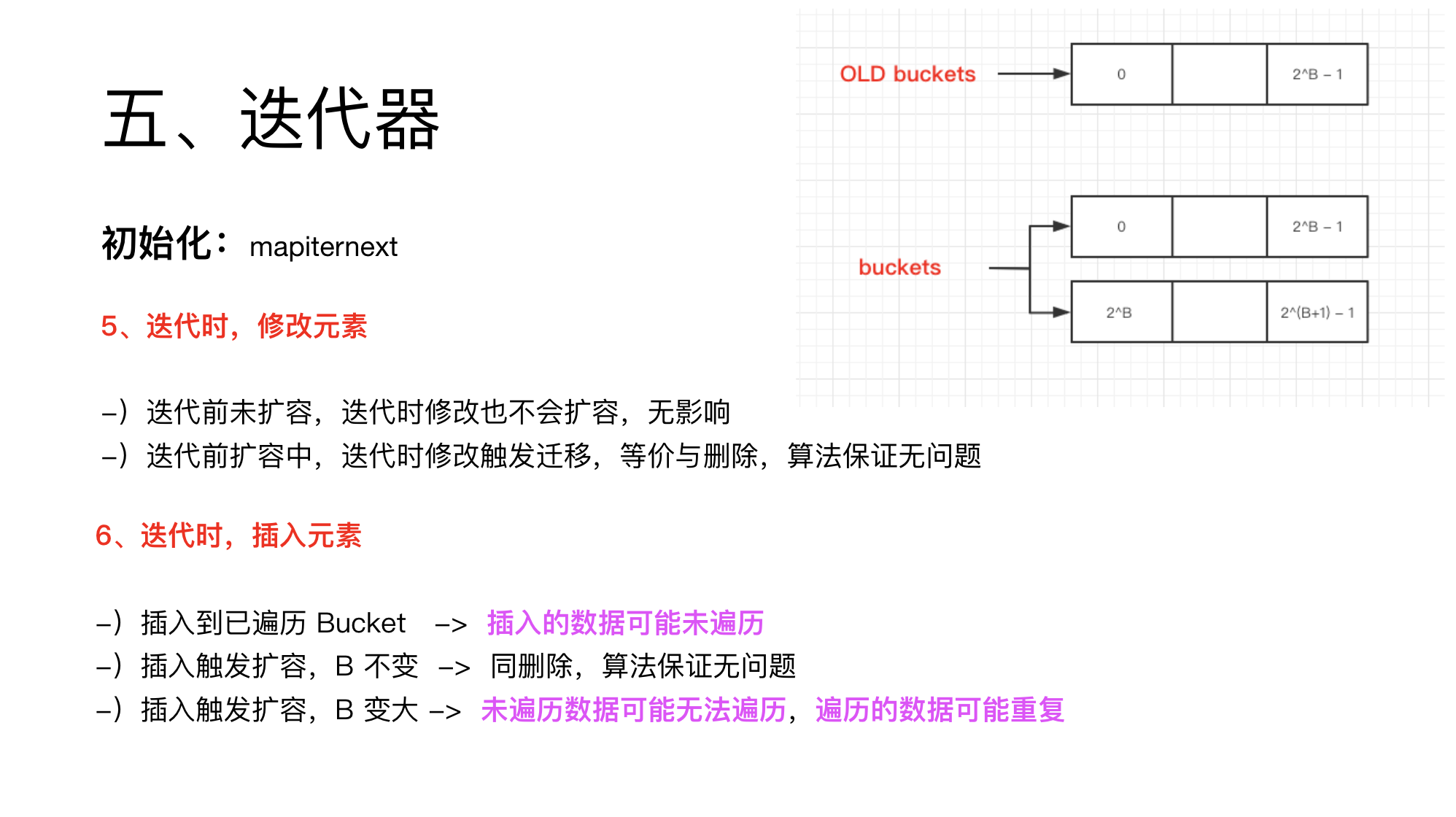
迭代过程中,如果赋值时没有插入值,则修改与删除,不影响迭代。
如果赋值时,进入了插入值逻辑,触发了扩容。
则此时可能导致很多数据无法遍历,也可能导致很多遍历的数据被重复遍历。
思考题:大家感兴趣的话,回去可以分析下什么情况会怎么样。
最后介绍下迭代器的结论:迭代过程中可以删除或者修改内容,但是不能插入。
当然,建议迭代过程中,任何写操作都不要有。
另外,需要强调的是,map 不支持并发读写,会直接 panic 的。

六、最后
到这里就到尾声了,go 的 map 设计我们也都理解了。
ppt 我一会发给大家,感兴趣的,公众号后台回复go-map-ppt 获取。

《完》
-EOF-
本文公众号:天空的代码世界
个人微信号:tiankonguse
公众号ID:tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
