规避11.27滴滴故障的8个措施
作者: | 更新日期:
线上只允许存在稳定版与灰度版本,其他版本都应该锁定。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
零、背景
之前分享了 2 起业界的故障复盘和分析。
11月15日,分享了《11-02 Cloudflare 机房故障》的复盘。
11月29日,分享了《11-21 阿里云故障复盘》的复盘与分析。
现在过了一周多了,我们来分析下11月27日滴滴的故障,以及该如何规避这个故障吧。
一、故障经过
滴滴不像 Cloudflare 和 阿里云那些,会公布详细的故障细节。
目前从滴滴官方公开资料上查询,只能确定下面几个信息。
2023年11月27日,晚上 23:19, 滴滴出行在微博平台发布公告,由于系统故障,滴滴App服务出现异常,经技术同学紧急修复,目前正陆续恢复中。
2023年11月28日,早上 07:31, 滴滴出行在微博平台发布公告,经技术团队连夜修复,滴滴网约车等服务已恢复,骑车等服务还在陆续修复中。
2023年11月29日,上午 10:52, 滴滴出行在微博平台发布公告,事故的起因是底层系统软件发生故障,并非网传的“遭受攻击”,后续我们将深入开展技术风险隐患排查和升级工作,全面保障服务稳定性,尽最大努力避免类似事故再发生。

滴滴官方没说啥时候故障开始的,也没说啥时候彻底修复的,但看公告,至少持续的有 8 小时,这里不去纠结具体故障多长时间。
二、变更操作与发布流程问题
关于故障原因,滴滴官方只说了一个信息:底层系统软件发生故障。
网上不少在传,是因为 k8s 升级版本不对导致全部故障的。
有人说应该升级到 1.12 版本,升级到了 1.20 版本。
也有人说升错版本,相当于降级了(应该升级到 1.20,升为了 1.12 ?)。
注意用词,不管是哪个说法,都提到升级版本,但升级错了。
这意味着滴滴的 k8s 线上至少存在 3 个可使用版本。
这里面其实暴露出滴滴 k8s 内部版本控制的一个严重发布流程缺陷。
是的,这个是发布流程问题。
对于比较重要的系统,为了防止线上版本误操作,一般同一时间只允许存在两个版本:一个是稳定版本,一个是灰度版本。
此时,只允许继续灰度,即将稳定版本升级为灰度版本;或者进行回滚,即将灰度版本降级为稳定版本。
其他版本都应该处于加锁状态,不能进行安装部署,防止误操作。
三、相关性事件与发布流程问题
10 月 17 日滴滴在“滴滴技术”发布的《滴滴弹性云基于 K8S 的调度实践》文章。
文中提到滴滴把 k8s 的版本从 1.12 升级到 1.20了。
在这个升级方案选项中,滴滴对比了搭建新集群与集群原地升级。
原地升级的其中一个难点就是:集群体量大,最大集群规模已经远远超出了社区推荐的5千个 node 上限,有问题的爆炸半径大;
不过滴滴最终还是选择了集群原地升级这种高风险操作。
10 月 17 日的文章中说:目前已无损升级滴滴所有核心机房万级别的 node 和十万级别 pod ,且升级过程中业务完全无感,未发生一次故障。
故障时间是11月27日,已经过去两个月,按道理已经将所有版本全部升级到 1.20 了。
所以,滴滴的这次故障,与上次升级的故障可能没啥直接关系。
没有直接关系,不代表没有关系。
这就涉及到线上发布流程的另一个问题:可回滚性与有效版本。
滴滴由于在原地升级的,一旦升级完毕,这个操作应该是不可回滚的。
那新版本全部升级完之后,就版本应该标记为不可发布,防止误操作发布上线,产生问题。
四、版本控制
汇总下无效版本、有效版本、稳定版本、可发布版本,可以发现版本之间扭转是一个有向图状态机。
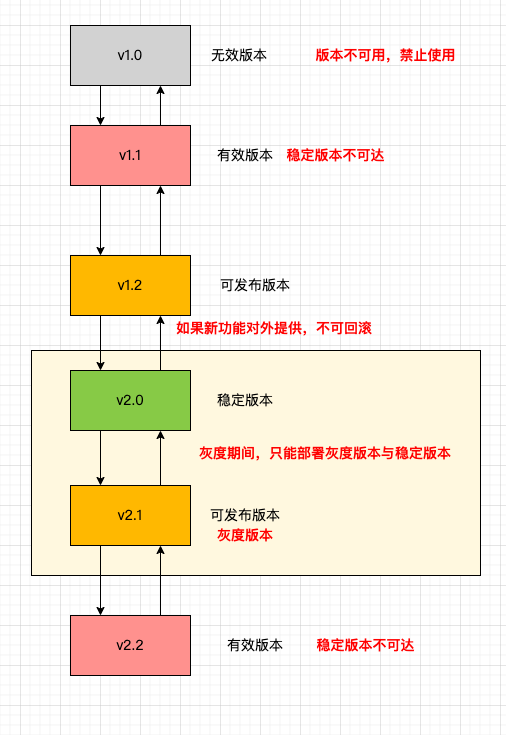
各个版本的含义看上图很清晰了,状态如下。
1)部分版本或者不可回退,称为无效版本,其他的称为有效版本。
2)默认情况下全量部署的有效版本称为稳定版本。
3)稳定版本的容器可以直接发布或回退的版本,称为可发布版本。
4)一旦部署其中一个可发布版本,选择的可发布版本就变为灰度版本。
5)存在两个版本时,只能部署灰度版本或者稳定版本,不能部署其他版本。
附加:不向下兼容的版本一旦变为稳定版本,旧版本应该全部变为无效版本
版本控制的大致理念是这样,具体的可以参考业界的专业书籍。
五、其他规避措施
滴滴的这次故障是变更导致的,所以不得不提怎么规避变更导致灾难性故障。
措施1:可回滚。
变更的第一要义是可回滚,一旦有问题,赶紧回滚即可。
措施2:可灰度。
灰度的概念比较抽象,根据影响范围,粒度应该逐渐变大,例如从单机、单SET、单集群、单机房依次扩大。
另外,应该从优先级较低的机房、集群、SET来灰度验证。
措施3:爆炸半径。
有时候没办法选择单机或单SET灰度变更,选择的是一刀切。
这个时候就需要从集群维度控制爆炸半径了。
不同业务物理隔离为不同的集群,从而在遇到极端故障时,不同集群互不影响。
另外,即使进行了集群划分,后续也需要对集群进行持续优化,即分析集群是否合理,是否需要调整。
文章《重庆飞深圳,50 元体验头等舱》的最后小节提到,我刚好安检的时候,收到反馈服务处故障了。
这次运气比较好,出故障的集群就是最不重要的通用集群,其他核心集群的核心业务都不受影响。
事后,我分析了一下这个通用集群,流量占总流量的 32%。
我们有十几个集群,其他集群流量最高时 15%,这个已经是 32% 了,需要进行拆分。
PS:很多流量很小的集群,也需要进行合并,降低维护成本。
错误4:故障降级。
线上出问题是不可避免的。
所以我们需要有降级措施来降低故障的影响范围。
故障降级应该从全局维度来做,而不是各模块各做各的。
PS:如果各模块之间有 SLA 承诺,那每个模块就需要做各自的降级了。
简单来说,从全局维度分析核心链路,并在最靠近用户的某一层增加柔性降级功能。
底层的某个模块出现故障,自动开启上层的柔性降级,从而可以降低故障的影响。
例如服务加一个兜底缓存就是常见的降级措施。
记得之前我这边有个储存故障,失败率100%,由于有一层缓存,读业务竟然全部都不知道这个故障的存在。
措施5:故障演习。
故障降级有了,还需要确保降级是否可以生效,以及影响范围是否降到足够小。
这时候就需要进行故障演习,模拟各模块故障时,是否可以降级,以及影响范围是否符合预期。
措施6:版本控制
上面提到,发布系统应该做版本控制,不能随意发布任何版本,需要做一些限制,这里不再重复介绍。
措施7:发布checklist
我们团队是有一个 发布checklist 的流程。
简单来说,发布一个版本时,需要写一个简介的文档,介绍做了啥功能,哪些依赖需要变更、变更会影响哪些功能、对应的监控指标有哪些、测试用例集、回滚流程。
当然,我们团队的这个发布checklist 还没有形成一个固定的模版。
我已经把这个事项放到 TODO list 中了,后面会分配给某个同事来制定一个标准模版来供团队内其他人参考。

措施8:其他
关于如何规避故障或者降低故障的影响范围,相关的措施很有很多,这里就不一一介绍了。
比如单元测试覆盖率、接口测试覆盖率、代码静态扫描、代码review、混沌工程、架构方案评审、故障复盘评审与改进等。
当然,也需要注意,这些一定要注意质量。
例如我们团队有个同事,写了很多单侧,但是所有的单侧都是调用业务功能函数,没有判断函数的返回值。
我看到这个行为是非常生气的,公开进行点名批评了。
这样的单侧是没有意义的,需要严格禁止。
六、最后
保障服务质量是一个很大的话题,这里以滴滴故障这个事情为引子,稍微展开介绍了下如何规避故障。
后面有机会了,再对这些措施进行分类与汇总,那时候再展开聊聊吧。
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号:tiankonguse
公众号ID:tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
