协议该为批量模式,性能提升 3 倍
作者: | 更新日期:
压测不同批次,到后面就无法提升性能了。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
零、背景
前文《减少磁盘IO与数据COPY,性能提升5倍》提到,团队的一个服务遇到一个读文件的 coredump 问题,但是 review 代码没发现 coredump 的原因,但是发现对应模块设计存在很大的性能问题。
我把代码提取出来,做了简单的优化,耗时从 23.5秒降低到了 4.6 毫秒,性能提升了 5 倍。
当时提到,其实还有两个设计可以优化。
现在来看看其中一个设计问题吧。
一、协议设计
前文提到,我们的数据储存在 COS 里。
对于 COS,大家可以理解为一个远程文件储存系统,即远程的磁盘。
与本地次磁盘区别是,远程磁盘只能通过一次 IO 操作来读取或写入完整的文件数据。
回到文件的协议,如下:
文件分为 N 个 Block。
每个 Block 分为两部分:
第一部分固定 20 字节,内容是数据的长度 len。
第二部分是 len 个字符,代表多个item 通过 protobuf 数组编码后的内容。
二、问题
先来 Block 的第二部分,即储存一个二进制内容,内容是多个 item 编码而成。
大家可以思考一个问题:
整体数据很大,拆分为多个文件,文件大小多大合适?。
每个文件拆分为多个 Block, 每个 Block 储存多个 item。
那一个 Block 储存多少个 item 才合理呢?
实际上,需要进行压测,得到性能数据才能得到最合理的阈值。
即压测确定一个文件多大时性能最高,一个 Block 多大时性能最高。
然后根据文件性能确定单个文件大小,根据 Block 性能确定单个 Block 大小,进而计算出 Block 个数与 item 个数。
当然,这里我不记得当时设计时是否有压测。
看配置,最终设计的文件大小上限是 200M。
但是看线上数据,实际一个文件只有20~50M,核心集群一个文件在 30M 左右。
Block 大小,设计的是 10000 个 item 一个 Block,后来临时加了一个 1M大小的限制。
但是由于临时加的总大小逻辑有BUG,导致实际是 一个 Item 对应一个 Block。
换句话说,前文提到的有几千万次 fread io,队列也会有几千万次转发,都是因为这个 BUG 被二次放大了。
三、优化
优化其实很简单,一个 Block 的 item 个数调大。
具体调多大合适呢?
由于清理编译环境,上次的文件不在了,我只好从线上COS重新下载一个文件,所以这次的数据和上次会有细微变化。
这里我先使用转换程序,将原始文件处理为指定 item 个数的目标文件,并使用倍增算法确定大致 item 的范围。
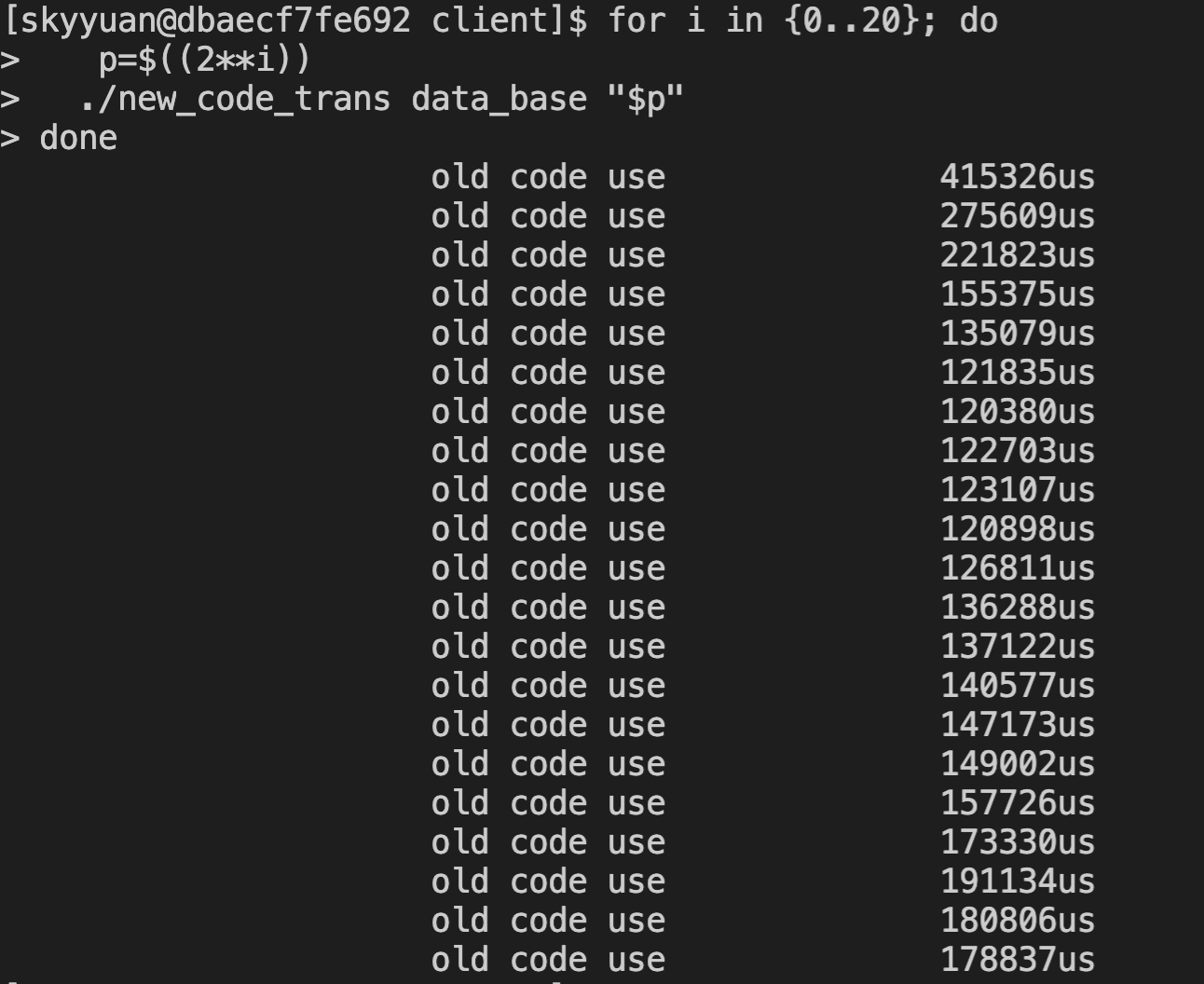
分别压测 item 拆分为 2 的 1~20 次方个,可以发现,最低的是 2048个一组,降到了 11.1秒。
原始个数是 1个,耗时 34秒,最优可以降低到 11秒,性能提升 3 倍。

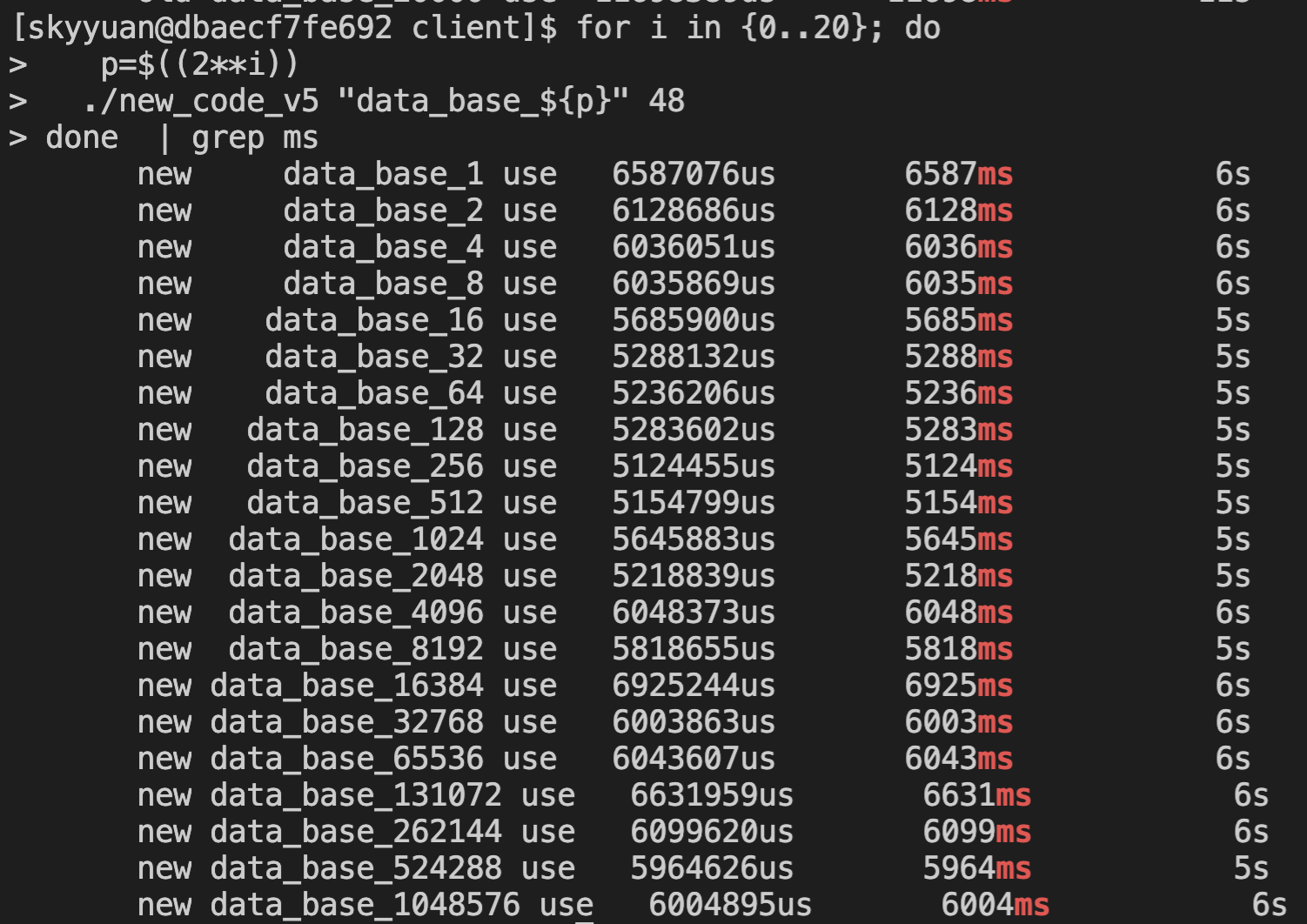
上面文章提到,通过优化架构,性能可以提升 5 倍。
这里使用架构优化后的程序跑一下,可以发现, 批量优化的效果就没那么明显了,仅仅从 6587ms 提升到 5124ms, 提升 28%。
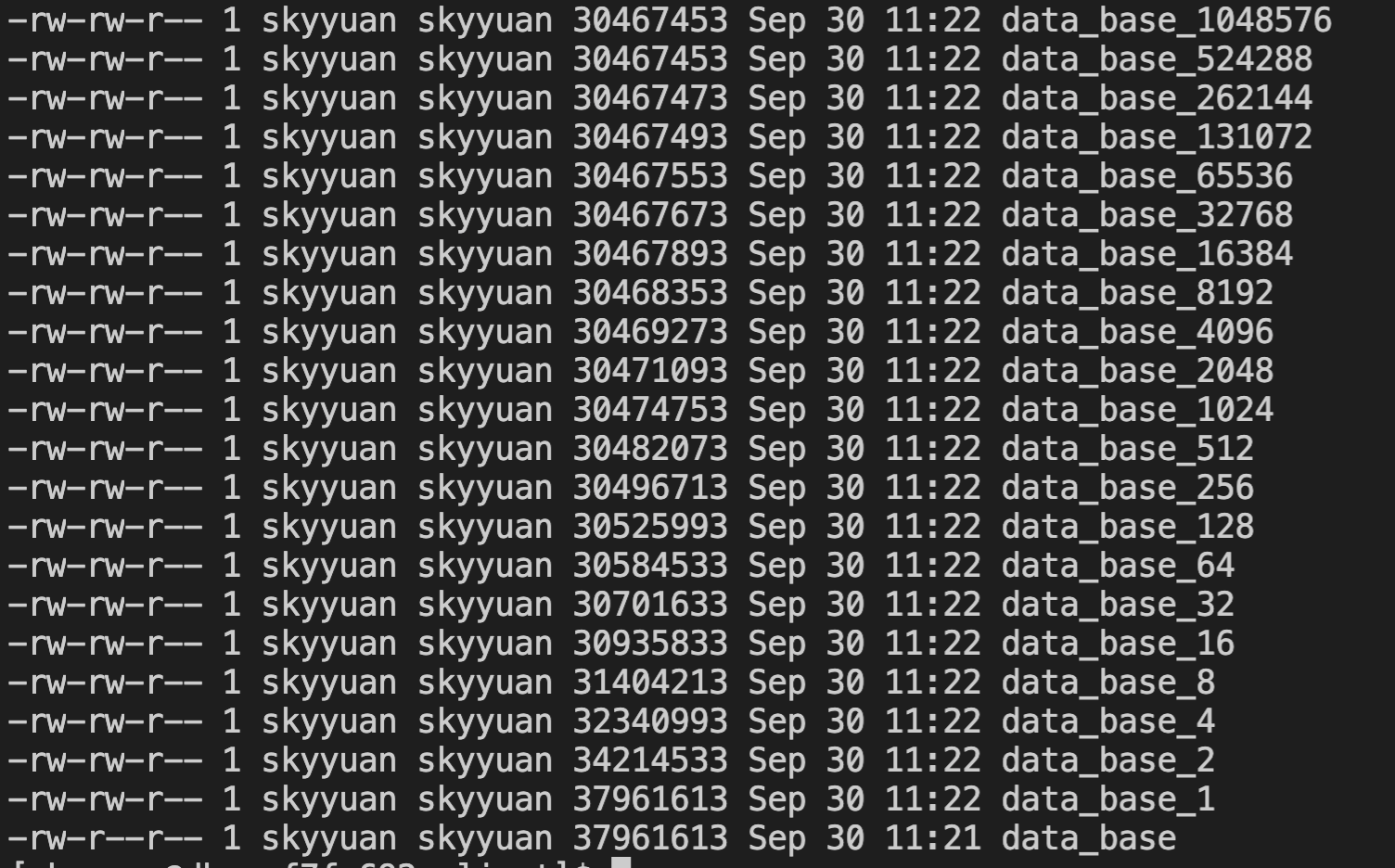
分析 item 合并后,可以发现文件大小降低了 23%,这说明性能提升的主要原因是文件大小的降低带来的。
四、最后
当前的代码,不优化架构,仅仅调整批处理的个数,耗时就可以由 34 秒降低到 11秒。
至于批次应该设置为多大,则需要根据自己的业务特性,进行压测分析,选择适合自己的批次。
而进行架构优化,则可以将耗时降低到 5.1秒,相比批次优化,依旧可以提升 1 倍性能。
回顾这个模块,还有两个地方可以优化。
第一个是 Block 的第一部分是固定 20字节。
未来优化为 4 字节,文件大小可以降低不少,性能应该又可以提升一部分。
第二个是 Block 的第二部分是一个 列表 protobuf,列表的值有是一个 protobuf 序列化后的值。
这里就存在两次 protobuf 解包,即会复制两次内存。
如果合并为一个,则只需要复制一次内存,性能应该可以再次提升。
当然,这两个优化涉及到改动协议,短期内就暂时不动了,十一后先做一下代码优化,先提升 6~7 倍性能再说吧。
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号:tiankonguse
公众号ID:tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
