学习了spark原理,任务性能提升13倍
作者: | 更新日期:
spark 背后的原理挺有意思的,学习后任务轻松提升10倍。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
一、背景
前文《AI 2分钟生成项目文档与自动解决编译问题》提到,团队内有一个 scala 语言编写的 spark 大数据任务,这个任务每小时跑一次,经常被投诉任务失败或者超时。
我带着一个实习生来优化这个任务,期间遇到问题,心中有非常多的疑问,查询大量资料,理解了 spark 计算框架底层的逻辑后,最终任务性能提升了10~20倍,彻底解决了任务超时的问题。
二、架构
这个任务的逻辑很简单,读取 hbase 数据,列数据转化为表格数据,然后写入到 hive 表中。
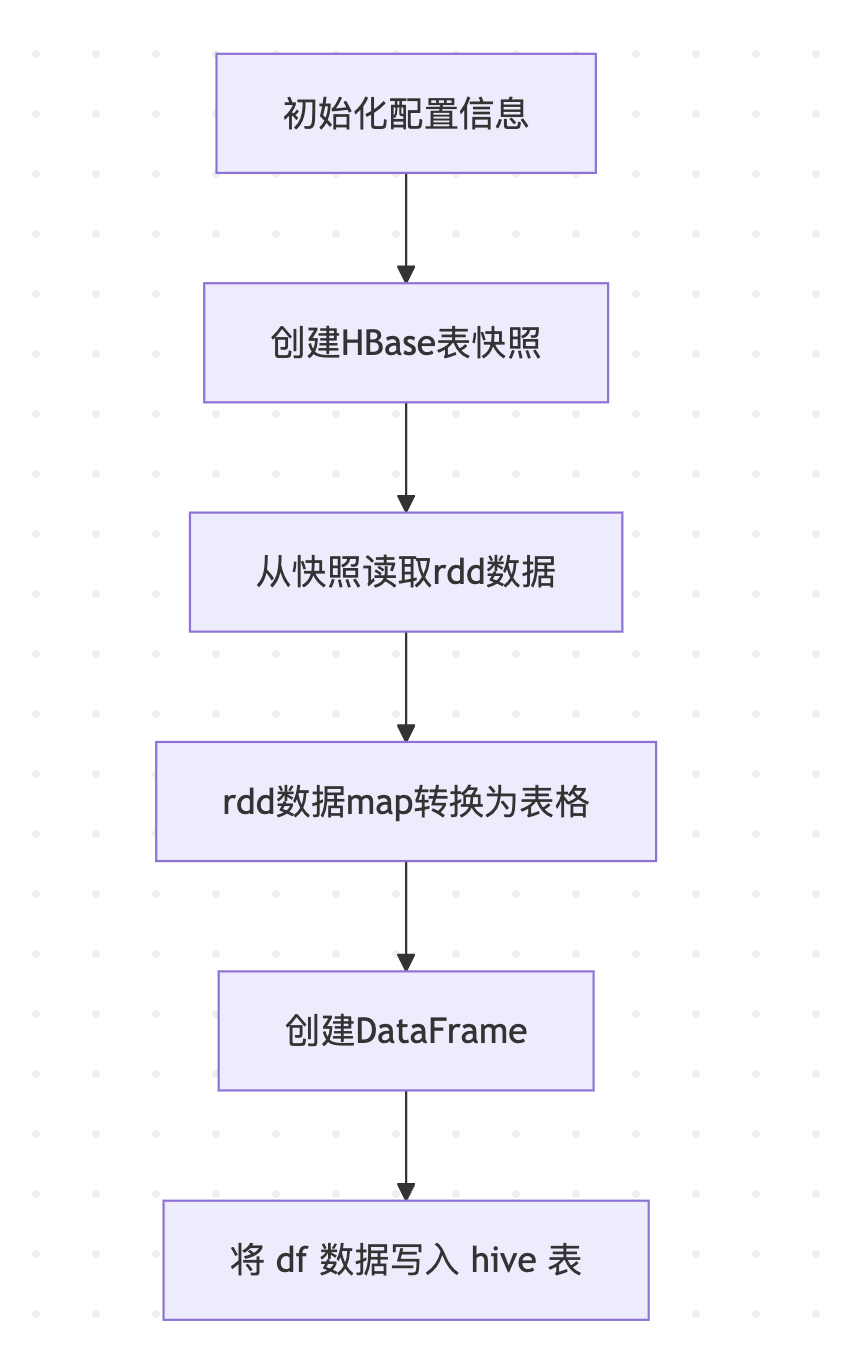
就是这样一个简单的任务,日常需要运行 1个小时半,偶尔运行 2 个小时,极少数情况运行 3 个小时。
三、搭建环境与调试
第一步是搭建编译环境,能够测试运行这个任务。
实习生按照大数据平台的文档,使用 IDEA 很快就把编译环境就搭建起来了。
由于大数据平台换了新平台,实习生测试运行遇到计算资源问题和运行权限问题,花了两天半也没解决。
最后我决策实习生去旧平台上测试运行,旧平台的计算资源和权限都比较简单。
由于新平台我有权限可以运行,还可以点击测试运行一次,后来折中实习生改好代码了,通知我,我点一下运行,周三晚上终于第一次运行成功。
周三晚上,我写完文章《AI 2分钟生成项目文档与自动解决编译问题》后,突然发现有一个告警:线上的一个任务运行失败了。
还好当天与实习生一起分析任务,我大概了解日志的含义。
一看日志,卡在创建快照了,再看下代码,快照名字写死的,任务执行前会删除快照然后创建快照,说明删除失败了。
之前的文章提到,周三评审时我临时使用 AI 分析了项目生成了文档,其中我还补充了项目有啥问题,AI 也都分析出来了。

我赶紧找文档看问题列表,看到了快照没删除这一项,我于是猜测出一个结论:测试任务生成的快照权限与正式任务不一致,导致正式任务无法删除快照。
幸运的是我当晚刚好借助 AI 搭建了 Vscode + linux 远程开发机的编译环境。
于是赶紧修改代码,在任务运行完之后,删除快照,然后手动运行测试任务。
之后运行正式任务,果然可以正常运行了。
如下图,20:30 我还在解决编译问题,22:53 我已经用首次编译通过的程序解决了一个线上问题。
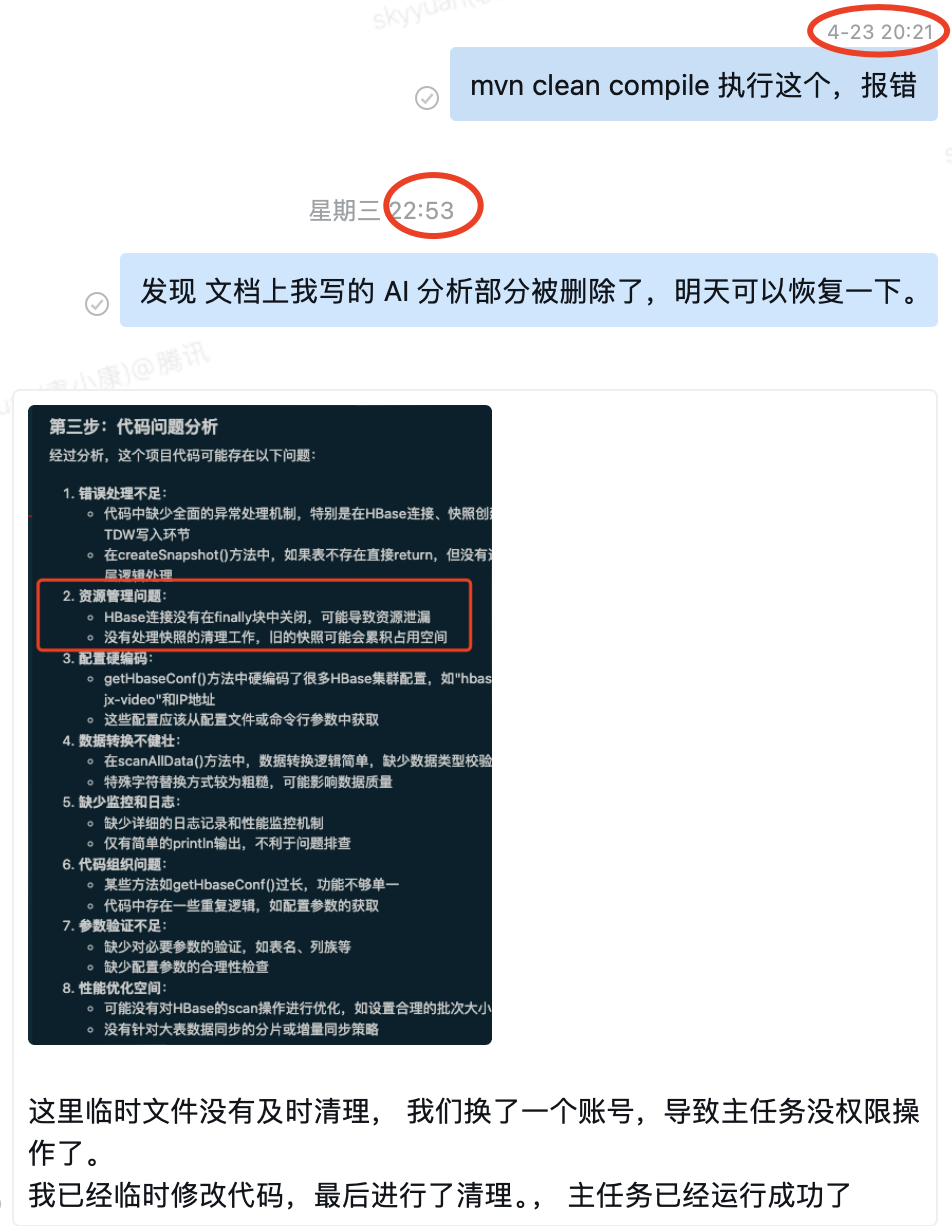
PS: 这也是我为何一定要搭建编译环境的原因,手上有了可以编译运行的代码,紧急情况下,才能临时修改代码去发布修复问题。
四、并发度始终提升不上去
第二步是增加日志,度量各个步骤的耗时,看耗时消耗在哪里了。
分析日志,发现前面所有步骤都运行的很快,最后一步写入 tdw 表的步骤耗时最长,基本上占用了 99% 的时间。
PS:后来才意识到,其实线上的代码已经在每一步骤打印了时间,也可以看到各个步骤的耗时。
下图为实习生的结论:
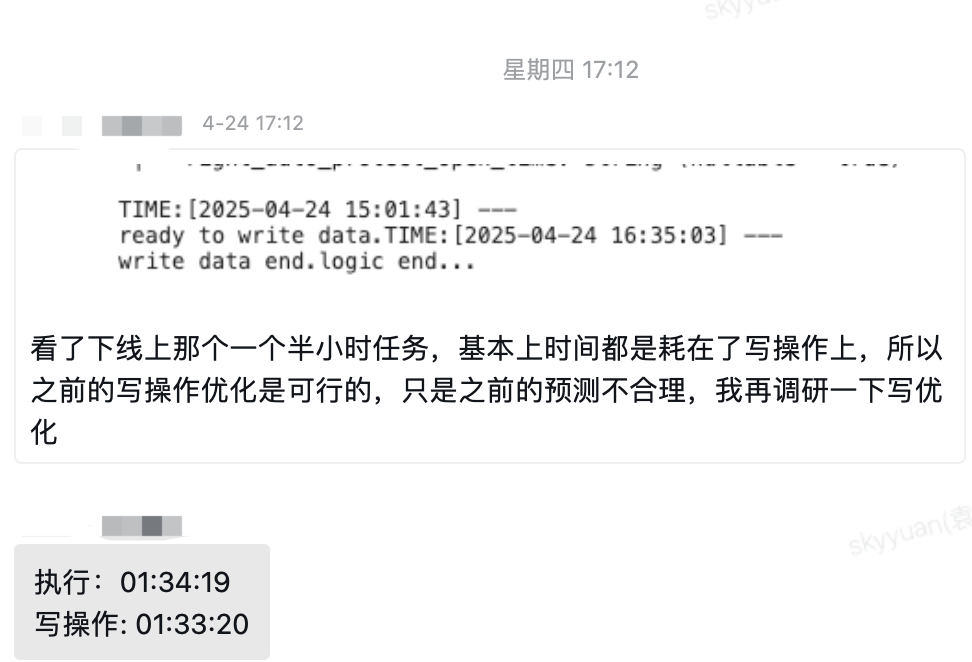
根据日志,可以得出一个结论:我的思路是提升写入 tdw 的性能。
实习生调研后,结论是spark 的并行度不够,从而导致了性能低下。
初步优化方向是调整 executor 和 cores 的数量,让 spark 的并行度提升。
周四实习生研究了 1 天,没有发现性能有什么提升。
周五我让实习生先打印下分区数,发现只有一个。
那一切都清晰了,优化方向就是写 hive 前,主动进行 repartition 提升分区的个数。
不过调整分区后,如下图的日志所示,耗时还是都消耗在写入 tdw 上。
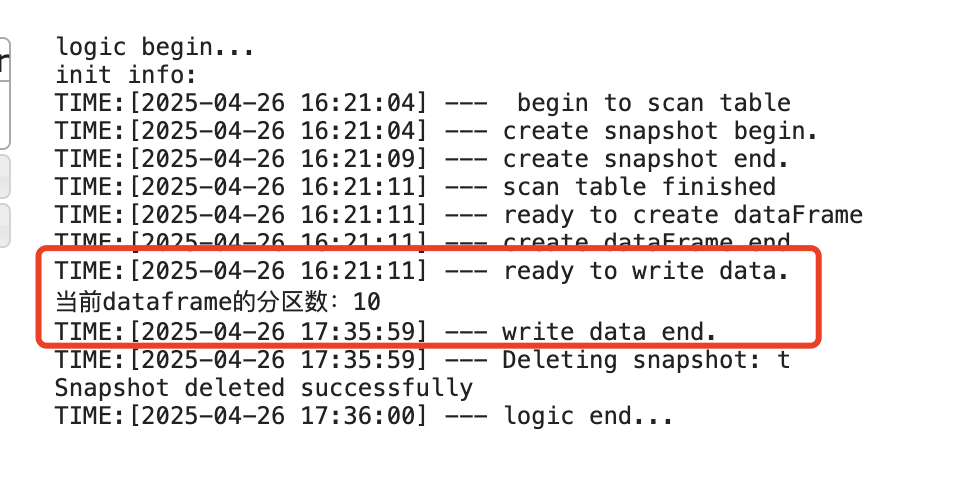
分析 spark 的 Stages, 发现 repartition 后变化如下:
Job 数量始终没变是 1 个
Stage 数量由 1 个变为 2 个
Task 数量由 1 个变为 11 个,第一个 Stage 为 1 个 Task,第二个 Stage 为 10 个 Task。

这就说明,spark 在写入 tdw 的时候,使用了 10 个 Task 来写入。
但是令我奇怪的是,日志显示已经运行在写入 tdw 的步骤上了,但是 Stage 视图上显示只有 1 个 Task 在运行。
另外,看 executors 视图,确实是只有一个 Task 在运行。
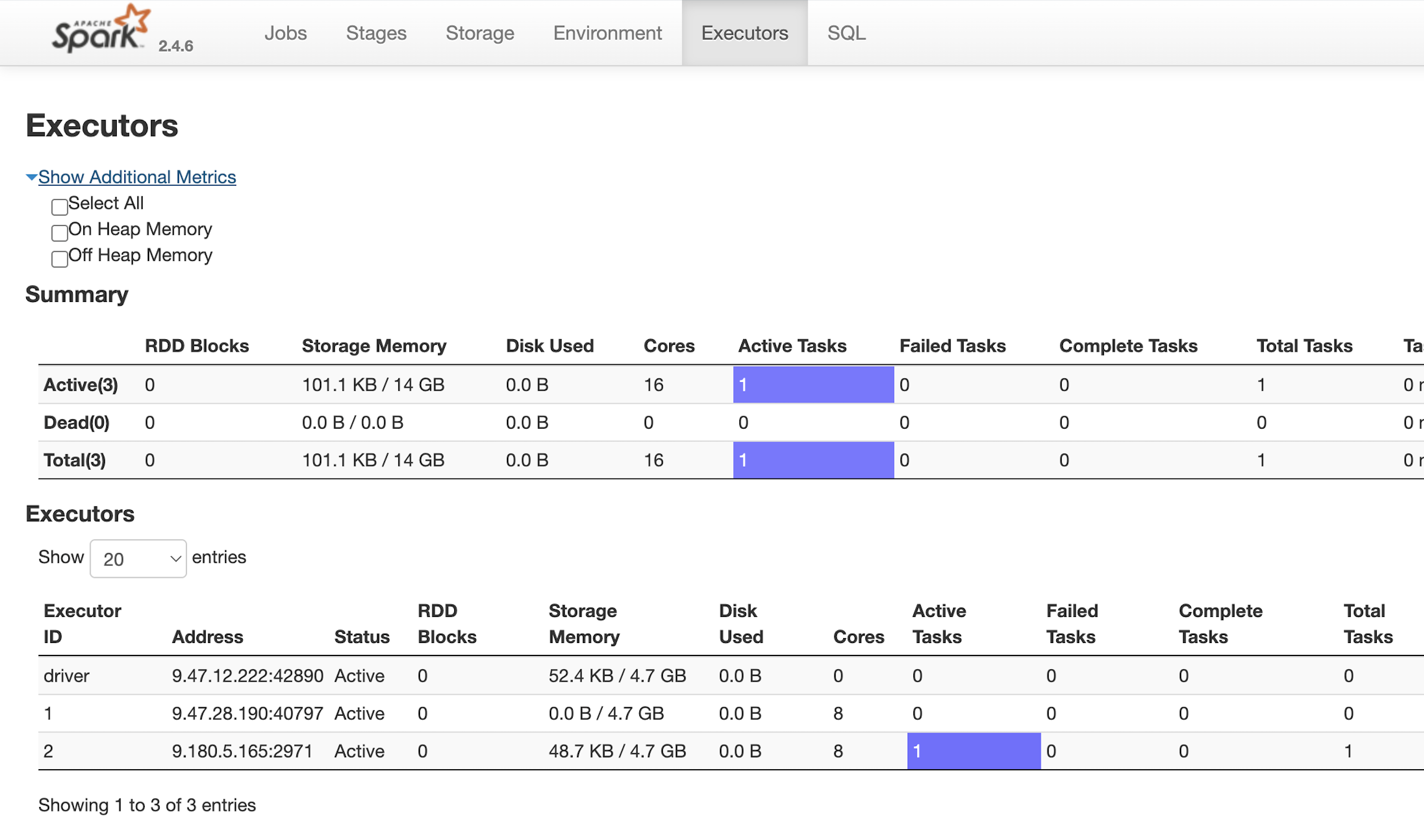
于是我提出来灵魂拷问:申请了 20 个执行器,为何实际只有一在运行?
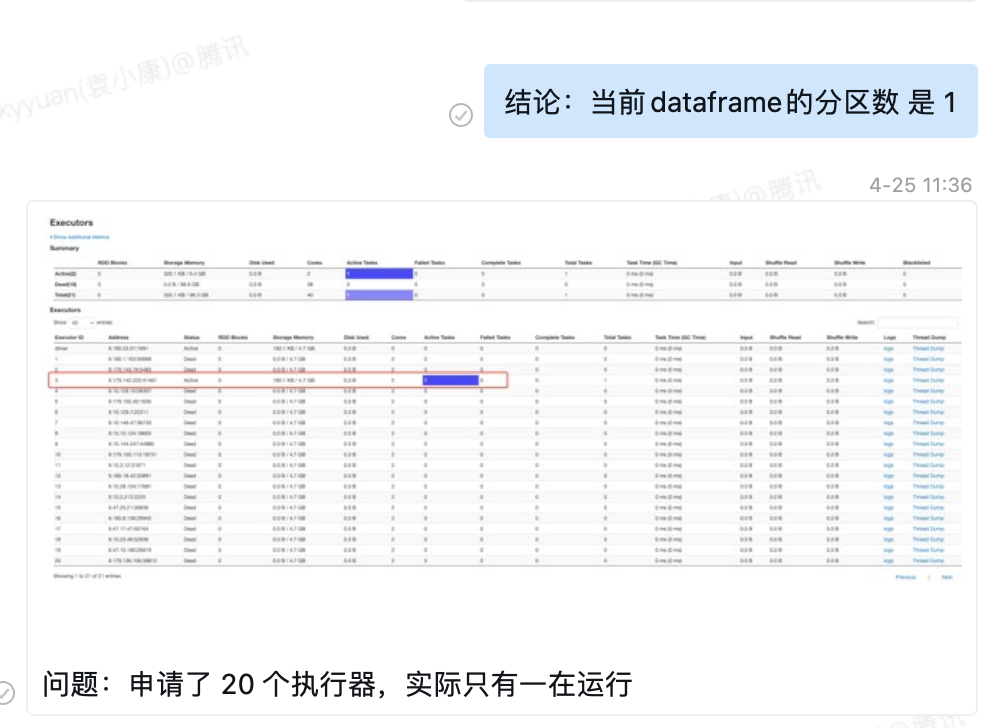
实习生猜测虽然 Task 拆分为 10 个,某种原因,这些 Task 是串行执行的,所以 executors 视图上只有一个 Task 在运行。
所以重点放在了调整 executor 和 cores 的数量上。
五、spark 请教
针对这个问题,我明白是因为我们都不懂 spark 的原理。
术业有专攻,所以我决定找人请教一下。
找到一同事,问道:问个大数据任务的问题, 我们定时把 hbase 的数据导入到到 tdw, 导入时写入一个时间分区了。
现在的问题是运行速度 比较慢,看spark 调度,虽然申请了很多核,但是看只运行了一个 task。
这里怎么能提高运行并发度来降低运行时长吗?
同事回答: 如果确定任务级的资源没问题的话,可以试试repartition,增加并行度看看哈

我继续追问:这里,设置了 repartition(10个), 分配了2个执行器,但是只在一个上运行。
df 设置了 repartition, task 会变多,但是都是在一个 执行器上运行。
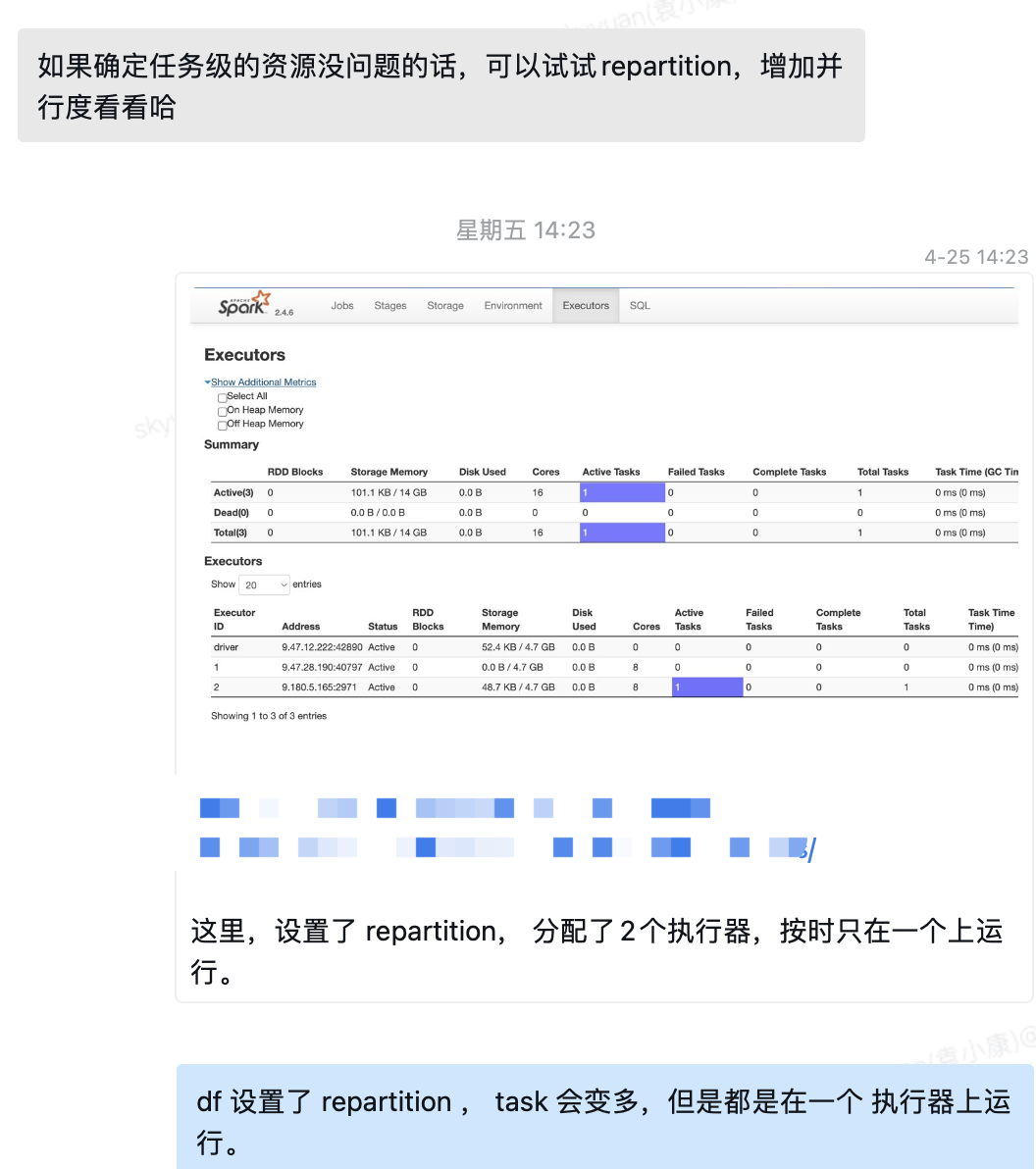
同事看了我的任务监控视图后,我们两就不在一个频道了。
同事通过 stage 监控来论证任务处于什么状态,我使用日志来论证任务处于什么状态。
同事说任务还在运行读 hbase,我说看日志已经在写入 hive 了。
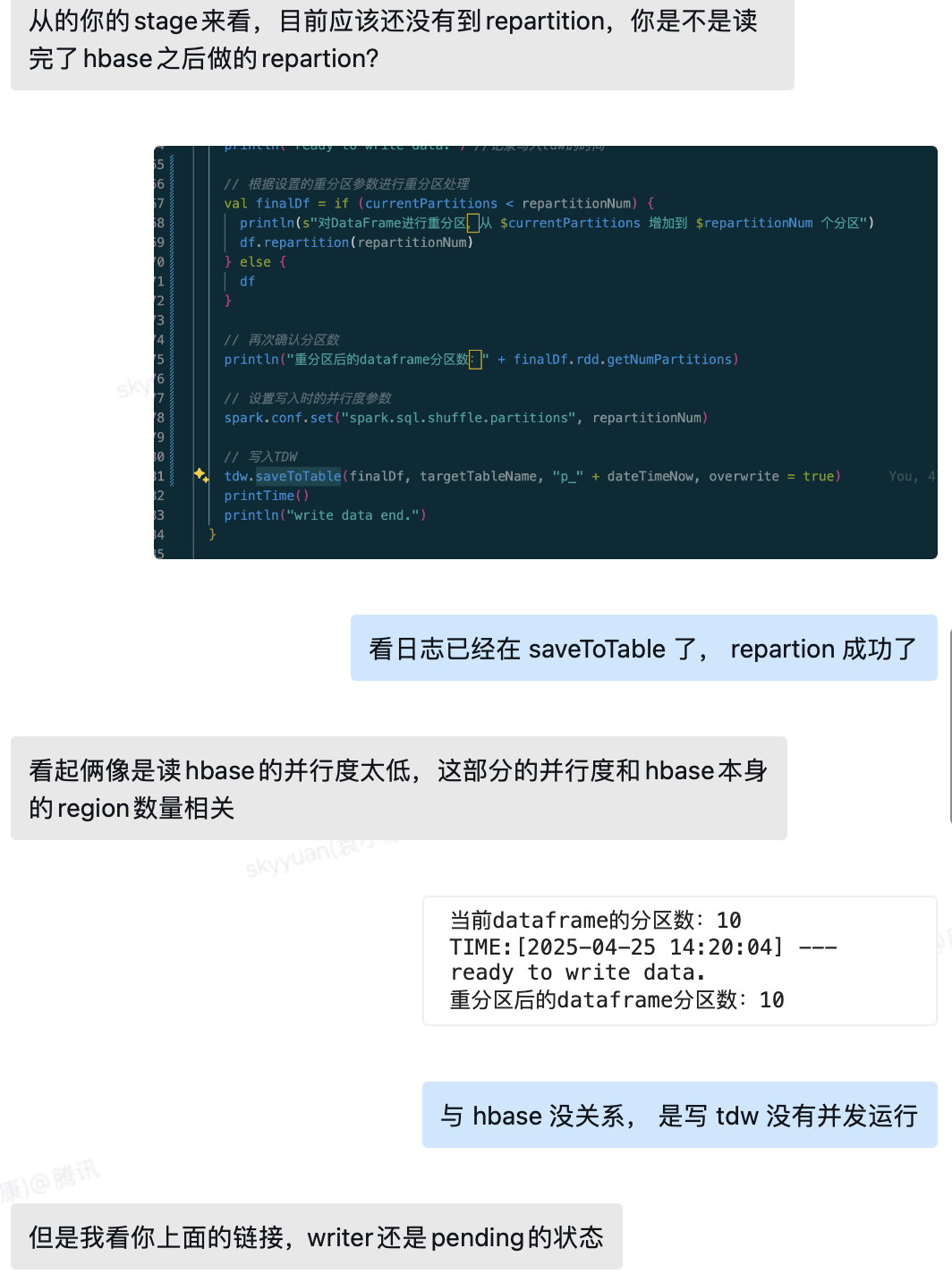
同事后来不再和我争论了,让我提供下代码链接。
看完我的代码,同事直接说电话沟通吧。
于是同事在会议上,投屏给我介绍了下 spark 的原理。
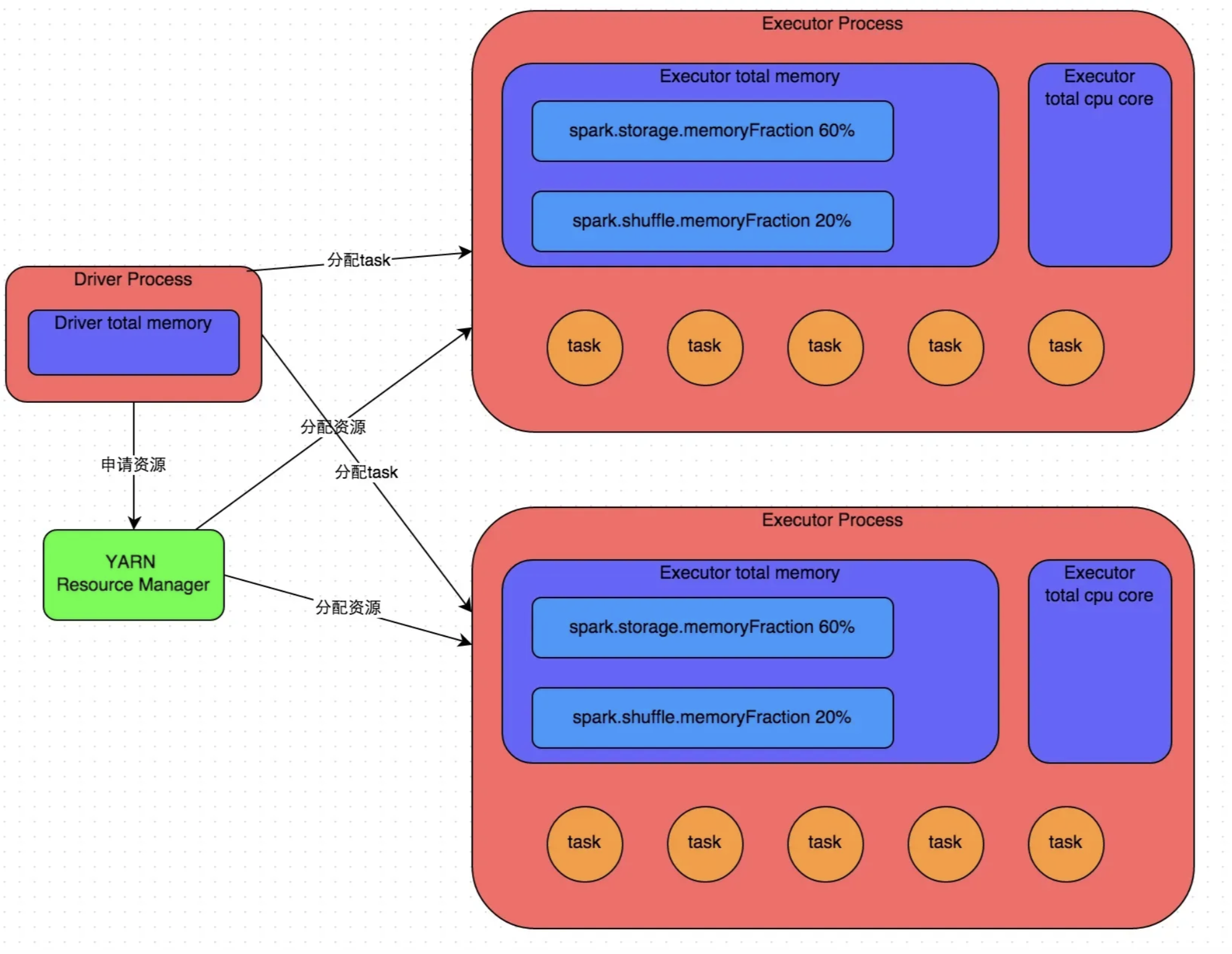
六、spark 原理
spark 执行器分为 driver 和 executor,driver 负责调度,executor 负责执行。
提交任务后,driver会走一遍代码,生成 DAG(有向无环图),然后实际由 executor 来执行。
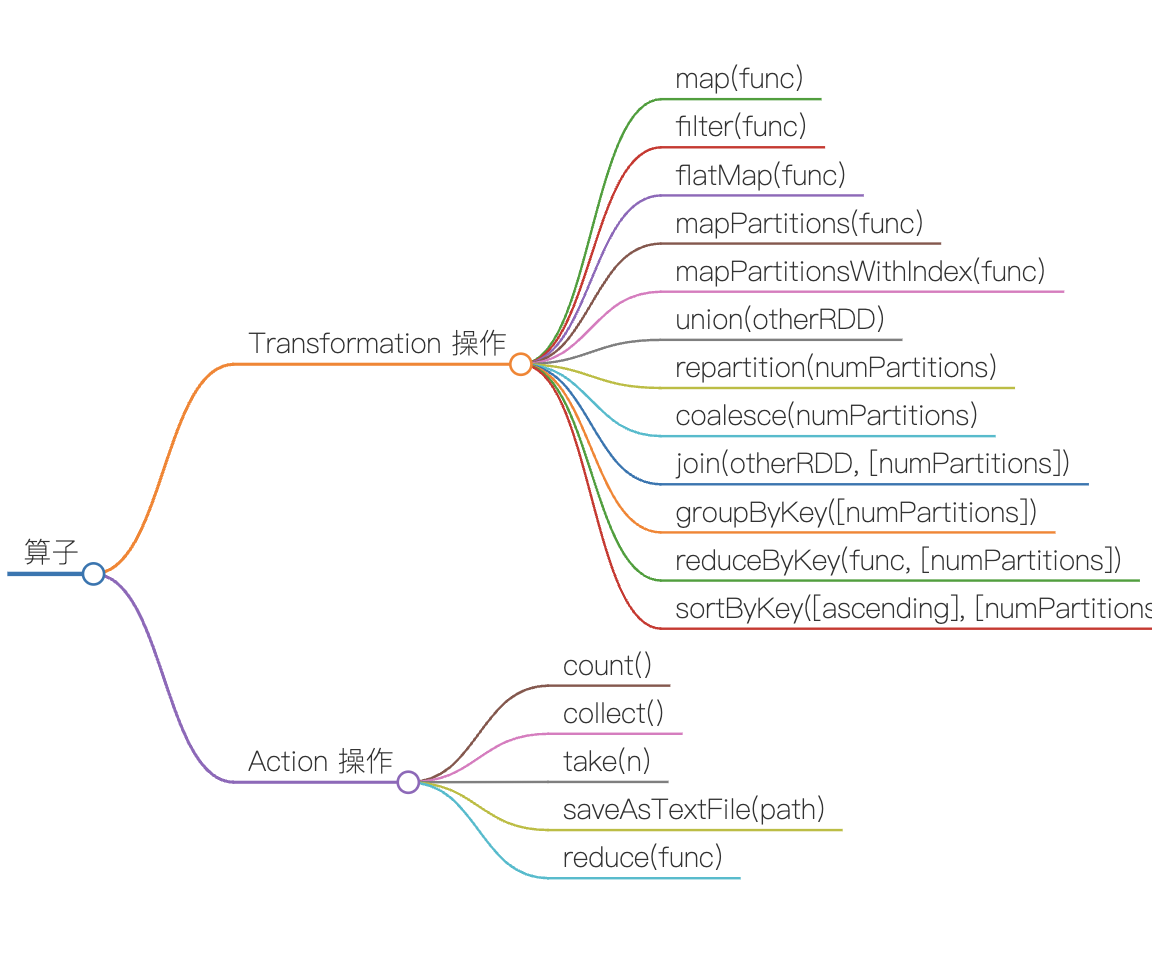
代码的函数分两类: Transformation 操作 和 Action 操作。
其中 Transformation 操作是惰性计算的,只有在 Action 操作时才会触发计算,依次链式执行。
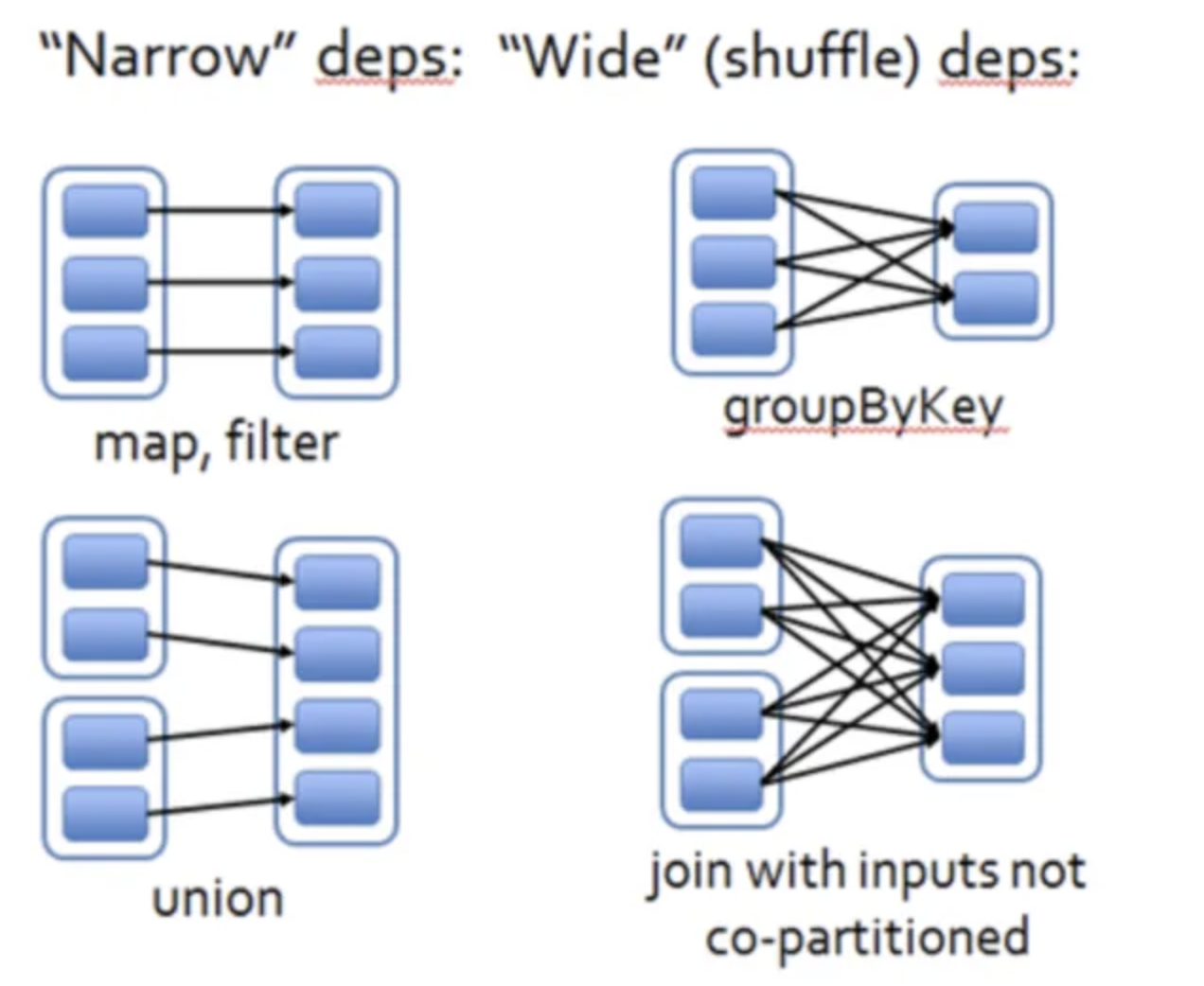
另外,Transformation 也分为窄依赖和宽依赖,主要是看是否有 shuffle 操作。
窄依赖:map、filter、union、sample、coalesce、mapPartitions
宽依赖:groupByKey、reduceByKey、join、distinct、cogroup、repartition、sortByKey
宽依赖由于要进行 shuffle 操作,所以需要大量的传输数据,性能会比较低下,需要尽量避免。
关于 Job、Stage 和 Task 的关系:
1)Job:一个 Action 操作对应一个 Job,一个 Job 就是一个 DAG。
2)Stage:一次 Shuffle 操作对应一个 Stage, 如 repartition。
3)Task:分区数决定 Task 数量。
这里原始代码中,只有一个 Action 操作,没有 Shuffle ,所以只有一个 Job 和一个 Stage。
后面进行 repartition 操作后,增加了 Shuffle,所以有了两个 Stage,且第二个 Stage 有 10 个 Task。
由于 repartition 操作是 Transformation 操作,所以不会立刻执行。
只有在后面有 Action 操作时,才会触发计算。
这个也是看到的日志与 stage 视图不一致的原因,这个日志是没有参考意义的。
七、方案评估
同事介绍完原理后,我明白了问题所在。
根本原因在于 hbase 只有一个分区。
一开始我的想法是线上的 hbase 就尽量不操作了,看看能不能通过调整 spark 的并行度来提升性能。
为此,我还咨询了大数据平台的技术支持,对方只是把 AI 诊断任务的建议罗列了一下,我试了没啥用。

考虑到这些技术都是公共开源的,我也咨询了四五家大模型,都给出了建议,但是建议运行后都是没有效果的。
于是周六这仅有的一天休息日,我看了一天的 spark、hbase 相关的原理文章。
最终得出一个结论:只调整 spark 参数是没用的。
本来我打算把任务拆分为增量和全量,全量一天跑一次,增量每小时跑一次,跑最近2天有变更的数据。
看下写入量,一天几百条,可以接受。
看下当前任务的下游依赖,竟然接近一百多个,那推动下游改造是不现实的。 ’
所以,我最终决定还是修改 hbase 分区个数。
这些结论我当然不能直接告诉实习生,于是我让实习生去调研一下,输出 hbase 分区现状与问题、调整分区的收益与风险、hbase写现状、hbase读现状、执行计划。

PS:培养一个人成本确实很高。
组内给大家分配任务时,大多数时候,我基本都粗略的调研过或者简单的验证可行性了,但是我不能告诉对应的 owner,需要他们独立去调研、输出方案、执行落地。
这也是为啥评审方案时可以直接指出方案缺陷,或者代码 CR 时可以直接指出逻辑漏洞,项目启动之前这些我都已经考虑过了。
八、优化
由于方案确定是修改 hbase 分区了,周六晚上,我找了一个测试的 hbase 表,进行了各种拆分分区、合并分区的验证。
验证了 hbase 的分区是通过 rowkey 的字典序来分区的,因此我也提前跑出了 rowkey 的前缀分布图。
PS: 实际1位前缀、2位前缀、3位前缀我都跑了,这里只展示下 1 位前缀的样例。
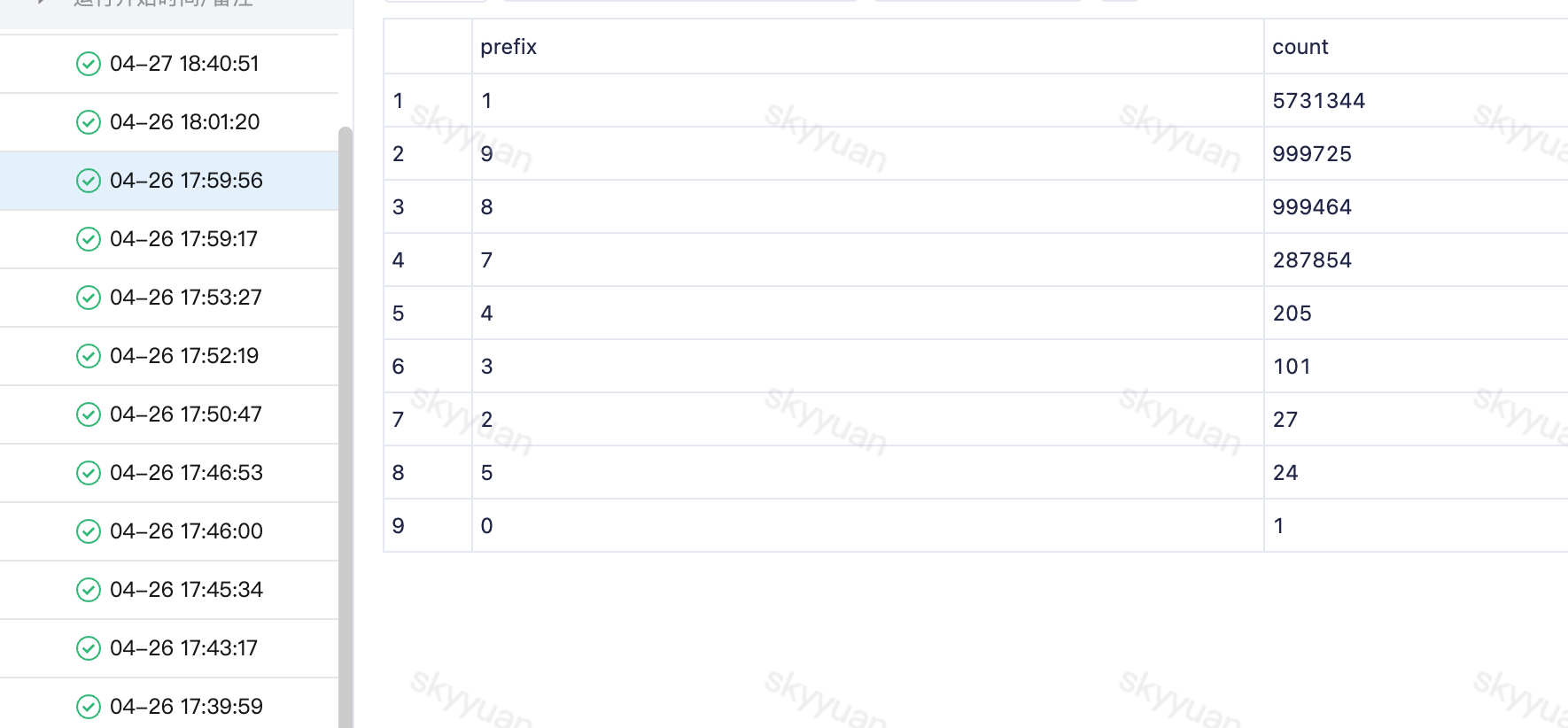
还记得前面提到调研现状吗?
实际上我也整理了一份简版的,如下:
hbase 分区现状与问题:1个分区,入口任务一小时跑不完,下游任务延迟。
调整分区的收益:任务速度可以提高十几倍。
调整分区的风险:
1)调整分区期间,不会丢数据。
2)但是影响读写性能。原先需要读一个分区,拆分区间部分key需要读两个分区。
3)如果有多个分区,只影响拆分的分区性能,不影响其他分区性能。
hbase写现状:写量很少,一个表一个小时只有几十个,另一个一小时1百多个,一分钟不到2个写请求。
hbase读现状:读量只有两个任务,一小时一次,理论上只有每小时的一开始读快照时需要访问 habse,之后就不需要读 hbase 了。
执行计划:预期是让实习生梳理 key 前缀的分布的。然后根据这个分布,划分出 hbase 的分区 rowkey 前缀以及分几批次,每个批次设置哪个 rowkey 前缀。
一切准备就绪,尝试进行了 hbase 的分区调整,发现调整第一个较小的表速度挺快的,隔了几秒刷新页面竟然已经完成了一次分区的拆分。
拆分后运行任务,速度果然提升了不少,不过没有降低一半。
之后继续拆分,再运行,速度继续提高。
第二个表比较大,第一次花费了几分钟,之后速度就快了,最终拆分了18个分区。
运行下任务,原先需要 100 分钟的任务,最终只需要 7~8 分钟,提升了 13 倍。
九、总结
优化这个任务后,发现还是需要了解一个技术的底层原理,才能更好的优化任务。
不然各种调参、猜测、验证,花费了大量时间,还是无法解决问题。
其实,周六我还了解了 spark 的其他技术原理,比如 SparkContext、SparkSession、分区方式(hash)、RDD只读特性、调度过程、资源配置、shuffle原理与优化、Broadcast、cache 优化等等。
这些和这个项目关系不大,我只是浏览阅读了一遍原理,没有具体项目实践,理解也不深,这里就不展开介绍了。
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号: tiankonguse
公众号ID: tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
