CSP-J 2021 编程算法比赛
作者: | 更新日期:
需要手搓双向链表
本文首发于公众号:天空的代码世界,微信号:tiankonguse
零、背景
最近我计划研究 CSP-J 与 CSP-S 的比赛题目,之前已经完成了 5 场比赛的题解,今天将分享 2021 年 CSP-J 第二轮比赛的详细题解。
A: 数学计算
B: 二分查找/线段树/分块
C: 模拟与hash
D: 双向链表
代码地址: https://github.com/tiankonguse/leetcode-solutions/tree/master/other/CSP-J/

| 比赛题目分类与题解 |
|---|
| CSP-J 2024 题解 A:扑克牌 入门 B: 地图探险 普及− C: 小木棍 普及/提高− D: 接龙 提高+/省选− |
| CSP-S 2024 题解 A:决斗 普及− B: 超速检测 普及+/提高 C: 染色 提高+/省选− D: 擂台游戏 NOI/NOI+/CTSC |
| CSP-J 2023 题解 A:小苹果 普及− B: 公路 普及− C: 一元二次方程 普及/提高− D: 旅游巴士 普及+/提高 |
| CSP-S 2023 题解 A:密码锁 普及− B: 消消乐 提高+/省选− C: 结构体 提高+/省选− D: 种树 提高+/省选− |
| CSP-J 2022 题解 A:乘方 入门 B: 解密 普及− C: 逻辑表达式 普及+/提高 D: 上升点列 普及/提高− |
| CSP-S 2022 题解 A:假期计划 提高+/省选− B: 策略游戏 普及+/提高 C: 星战 省选/NOI− D: 数据传输 省选/NOI− |
| CSP-J 2021 题解 A:分糖果 普及− B: 插入排序 普及/提高− C: 网络连接 普及/提高− D: 小熊的果篮 普及+/提高 |
一、分糖果

题意:k个糖果,平均分给n个人,剩余的给你。现在k可以在区间[L,R],问如何选择K,你才能获得最多的糖果。
思路:数学计算
显然,糖果个数从小到大变化的过程中,余数也是周期性从小到大变化的,且每个周期的值为[0,n-1]。
如果糖果个数选择大于周期,则肯定可以选择一个糖果个数,使得余数为 n-1。
否则,余数不足一个周期,分为两种情况:
情况1:余数递增,最后一个是答案。
情况2:余数跨越周期分割线,此时肯定包含n-1,答案就是 n-1。
ll Solver(ll n, ll L, ll R) { //
ll LR = R - L + 1;
if (LR >= n) { // 可选的数量大于等于n,可以得到任何余数,返回最大余数
return n - 1;
}
ll ln = L % n;
ll rn = R % n;
if (ln <= rn) { // 递增,说明余数递增
return rn;
} else {
return n - 1; // 否则,余数超过最大值后从0重新开始
}
}
优化:如果给周期编号,则可以发现,左右边界处于不同周期时,必然经过最大值,否则必然递增。
故判断边界是否在同一个周期即可。
ll Solver2(ll n, ll L, ll R) { //
if (L / n < R / n) {
return n - 1;
}
return R % n;
}
二、插入排序

题意:对一个数组修改与稳定排序,问排序前的第x个元素在排序后处于第几个元素。
思路:二分查找/线段树/分块
稳定排序需要有标识来区分相同值,下标是天然的区分手段,故可以储存值与下标二元组。
vector<int> nums;
vector<pair<int, int>> exNums;
for (int i = 1; i <= n; i++) {
scanf("%d", &nums[i]);
exNums.push_back({nums[i], i});
}
sort(exNums.begin(), exNums.end());
while (Q--) {
int op, x, v = 0;
scanf("%d%d", &op, &x);
if (op == 1) {
scanf("%d", &v);
const int V = nums[x];
removePos(V, x);
addPos(v, x);
nums[x] = v;
} else {
v = nums[x];
int ans = searchPos(v, x);
printf("%d\n", ans);
}
}
方法1:暴力排序
每次修改后,对下标与值进行排序,然后二分查找值与下标的位置。
复杂度:O(Q * nlog(n))
这个方法可以得 52 分。
bool isSorted = true;
auto removePos = [](int v, int x) { isSorted = false; };
auto addPos = [](int v, int x) { isSorted = false; };
auto searchPos = [&n](int v, int x) -> int {
if (!isSorted) {
exNums.clear();
for (int i = 1; i <= n; i++) {
exNums.push_back({nums[i], i});
}
sort(exNums.begin(), exNums.end());
}
pair<int, int> p = {v, x};
auto it = lower_bound(exNums.begin(), exNums.end(), p);
return it - exNums.begin() + 1; // 如果是第一个,
};
方法2:动态维护有序序列
依旧是储存值和下标稳定排序。
查询时直接二分查找。
修改时,先二分查找找到旧的值进行删除,然后二分查找找到新的值的位置并插入。
复杂度:O(Q * (log(n) + n))
由于修改操作不大于 5000,故这个方法可以通过。
auto removePos = [](int v, int x) {
pair<int, int> p = {v, x};
auto it = lower_bound(exNums.begin(), exNums.end(), p);
exNums.erase(it);
};
auto addPos = [](int v, int x) {
pair<int, int> p = {v, x};
auto it = lower_bound(exNums.begin(), exNums.end(), p);
exNums.insert(it, p);
};
auto searchPos = [](int v, int x) -> int {
pair<int, int> p = {v, x};
auto it = lower_bound(exNums.begin(), exNums.end(), p);
return it - exNums.begin() + 1; // 如果是第一个,
};
方法3:线段树+动态维护有序性
稳定排序其实分为两部分:值的排序与位置的排序。
对于位置为 x 值为 v 询问,我们关心的是小于 v 的个数以及等于 v 时在位置 x 之前的相同值的个数。
小于 v 的个数,可以通过离散化的线段树的区间计算得到。
等于 v 的个数,再通过动态维护有序序列的方法来计算答案,此时由于通过 v 对序列进行分组,理论上常数会小很多。
vector<vector<int>> indexMap; // {index, pos}
for (auto [op, x, v] : ops) {
if (op == 1) {
int oldP = hashMap[nums[x]];
removePos(oldP, x);
segTree.Update(oldP, -1);
int newP = hashMap[v];
segTree.Update(newP, 1);
addPos(newP, x);
nums[x] = v; // 更新原数组
} else {
int p = hashMap[nums[x]];
int ans = 0;
if (p > 1) {
ans = segTree.QuerySum(1, p - 1);
}
ans += searchPos(p, x);
printf("%d\n", ans);
}
}
方法4:线段树
方法3需要对值v进行离散化,如果我们直接对所有的二元组 {v,x}进行离散化,则可以直接通过线段树计算答案。
复杂度:O(Q log(n))
ll Hash(ll v, ll i) { return v * W + i; }
unordered_map<ll, int> hashMap; // {hash, index}
for (auto [op, x, v] : ops) {
if (op == 1) {
int oldVal = nums[x];
int oldP = hashMap[Hash(oldVal, x)];
segTree.Update(oldP, -1);
int newP = hashMap[Hash(v, x)];
segTree.Update(newP, 1);
nums[x] = v; // 更新原数组
} else {
int p = hashMap[Hash(nums[x], x)];
int ans = segTree.QuerySum(1, p);
printf("%d\n", ans);
}
}
方法5:分块
如果不对修改的次数做出限制,则方法2和方法3插入排序都会超时。
针对这个问题,一直典型的优化是分块加速有序序列的增删改查。
复杂度:O(Q * sqrt(n))
三、网络连接

题意:服务端可以基于有效地址来创建服务,客户端可以连接到已创建的服务上,此时需要输出服务的编号。
要求如下:
1)创建的服务地址必须有效。
2)相同地址只能创建一个服务
3)客户端连接的服务地址必须有效
4)连接的服务地址必须已创建服务
思路:模拟与hash
首先按照题目要求检查地址是否有效。
bool SkipNum(const char*& p, const int maxVal) {
if (!(*p >= '0' && *p <= '9')) {
return false; // 至少一个数字
}
if (*p == '0' && *(p + 1) >= '0' && *(p + 1) <= '9') {
return false; // 不允许有前导零
}
int num = 0;
while (*p >= '0' && *p <= '9') {
num = num * 10 + *p - '0';
if (num > maxVal) {
return false;
}
p++;
}
return true;
}
bool SkipChar(const char*& p, const char c) {
if (*p != c) {
return false;
}
p++;
return true;
}
bool Check(const char* p) {
if (!SkipNum(p, 255)) return false;
if (!SkipChar(p, '.')) return false;
if (!SkipNum(p, 255)) return false;
if (!SkipChar(p, '.')) return false;
if (!SkipNum(p, 255)) return false;
if (!SkipChar(p, '.')) return false;
if (!SkipNum(p, 255)) return false;
if (!SkipChar(p, ':')) return false;
if (!SkipNum(p, 65535)) return false;
if (*p != '\0') return false;
return true;
}
创建服务时,使用哈希表储存地址与编号,这样服务端可以去重,客户端可以查询。
if (name[0] == 'S') {
if (!Check(address)) {
printf("ERR\n");
} else if (mp.count(address)) {
printf("FAIL\n");
} else {
printf("OK\n");
mp[address] = i;
}
} else {
if (!Check(address)) {
printf("ERR\n");
} else if (!mp.count(address)) {
printf("FAIL\n");
} else {
printf("%d\n", mp[address]);
}
}
四、小熊的果篮
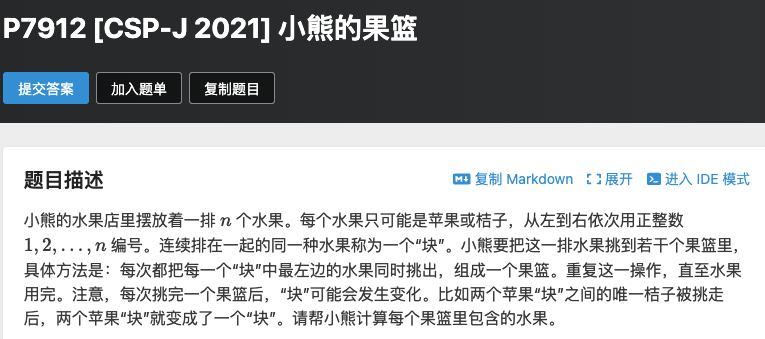
题意:有一排水果,分别为苹果和桔子,连续相同的水果组成一组。
每一轮可以按顺序选择所有分组中的第一个水果,不断重复,直到所有水果都被选择。
按轮数输出选择的水果编号。
提示:中间部分分组可能会合并。
思路:双向链表
根据题目描述,需要对链表做两个操作:删除第一个元素,合并相邻链表。
合并链表时,需要前一个链表的尾指针,因此使用双向链表最合适。
链表封装,使用数组来模拟链表。
struct LinkList {
int val = 0;
int pre = 0;
int next = 0;
} linkList[N];
int linkListIndex = 0;
void InitLinkList() { linkListIndex = 0; }
int NewLinkListNode(const int v) {
const int cur = ++linkListIndex;
linkList[cur].val = v;
linkList[cur].next = cur;
linkList[cur].pre = cur;
return cur;
}
int MergeLinkListNode(const int firstHead, const int secondHead) {
const int firstTail = linkList[firstHead].pre;
const int secondTail = linkList[secondHead].pre;
linkList[firstTail].next = secondHead;
linkList[secondHead].pre = firstTail;
linkList[secondTail].next = firstHead;
linkList[firstHead].pre = secondTail;
return firstHead;
}
int RemoveFirstLinkListNode(const int head) {
if (linkList[head].next == head) {
return 0; // 只有一个,删除后是空
}
const int tail = linkList[head].pre;
const int newHead = linkList[head].next;
linkList[tail].next = newHead;
linkList[newHead].pre = tail;
return newHead;
}
初始化时,每个节点都作为一个链表,并尝试与前一个链表合并。
vector<pair<int, int>> segs;
auto add = [](vector<pair<int, int>>& segs, int color, int head) {
if (head == 0) return; // 空列表
if (segs.empty() || segs.back().first != color) {
segs.push_back({color, head});
} else {
segs.back().second = MergeLinkListNode(segs.back().second, head);
}
};
for (int i = 1; i <= n; i++) {
int color;
scanf("%d", &color);
add(segs, color, NewLinkListNode(i));
}
多轮选择时,按顺序删除链表的第一个节点,之后尝试与前一个链表合并。
while (!segs.empty()) {
segsTmp.clear();
bool firstVal = true;
for (auto [color, head] : segs) {
const int val = linkList[head].val;
add(segsTmp, color, RemoveFirstLinkListNode(head));
if (firstVal) {
printf("%d", val);
firstVal = false;
} else {
printf(" %d", val);
}
}
printf("\n");
swap(segs, segsTmp);
}
五、最后
这次比赛难度适中。
第一题签到题。
第二题由于数据较弱,可以用暴力方法通过。如果数据范围再大一些,就只能使用线段树或者分块了。
第三题除了分析地址有效性稍微复杂一些,其他的模拟部分没什么难度。
第四题需要动态维护双向链表,这里封装了一个 add 函数,使得实现过程简单了许多。
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号:tiankonguse
公众号 ID:tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
