vibe coding:放弃 Node,转 Go
作者: | 更新日期:
Node 性能太差了,Go 太香了。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
零、背景
上上周我在《2周消耗4亿tokens做8个项目》提到,我连续两周 vibe coding 写了不少项目。
上周我在《spec code 将被 agent 替代》中分享了我使用 OpenSpec 的经验,以及在《更强大的 spec-kit》中分享了 Spec-kit 的经验。
之前 vibe coding 写的代码全是前端代码,技术栈是 Node + JavaScript + SQLite。
这周继续 vibe coding,发现当需要大量计算数据时,Node 性能太差了,所以我开始转向生成 Go 代码。
回顾一下,这周 vibe coding 了 5 个工具:时钟误差检测工具、Redis 数据一致性监控系统、缓存中间件一致性监控系统、HTTP 代理系统、Union 压测系统。
另外,对于之前开发的热度值监控系统,我也使用 Go 进行了重构,重构后系统稳定多了。
接下来简单分析下这些系统工具。
一、热度值监控
热度值监控,是为了从用户视角监控每个剧集的热度值发生变化时,数据是否会回退。
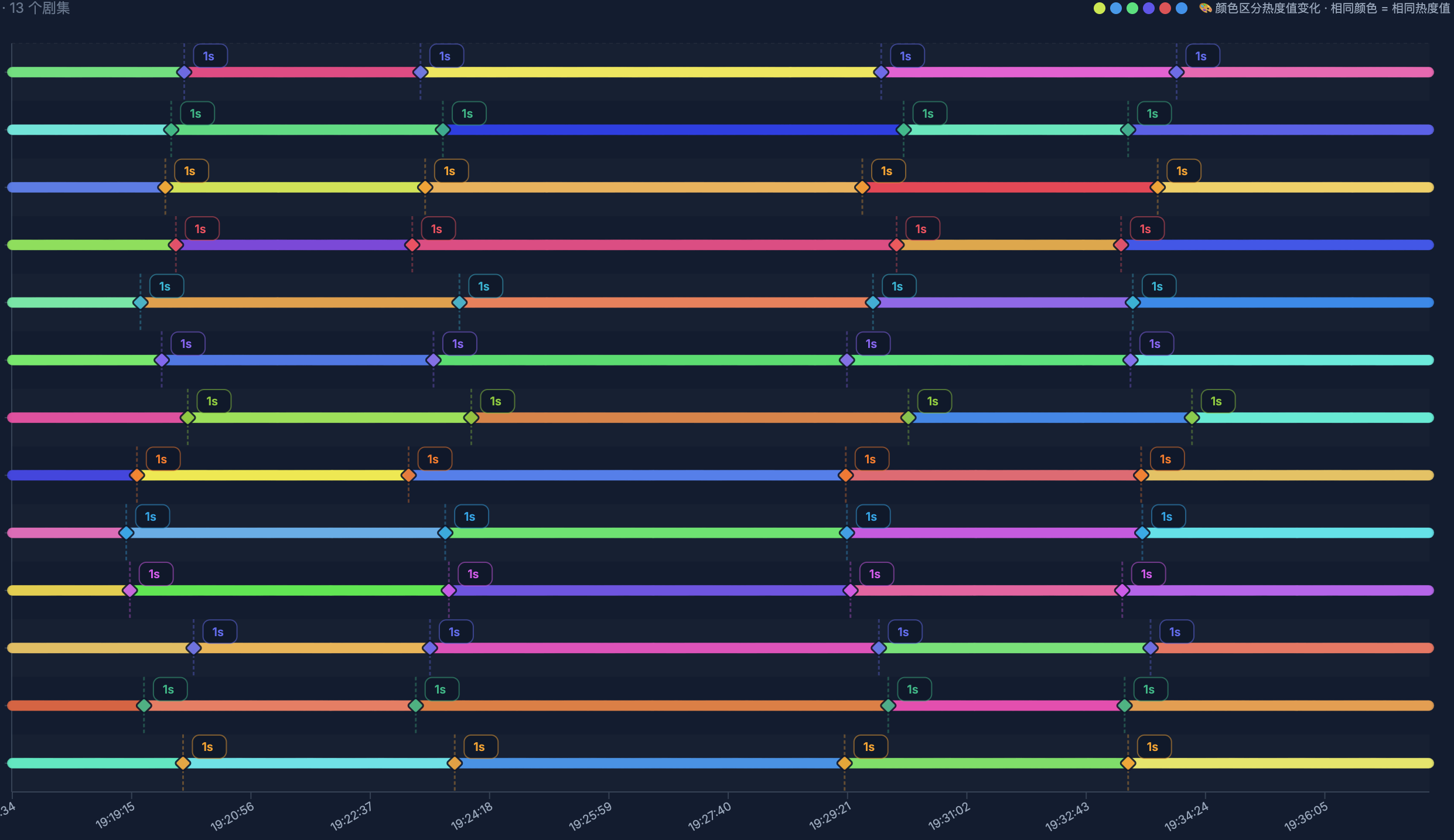
虽然做了一版优化,监控数据显示,优化后依旧存在某些时刻会有数据回退的现象。
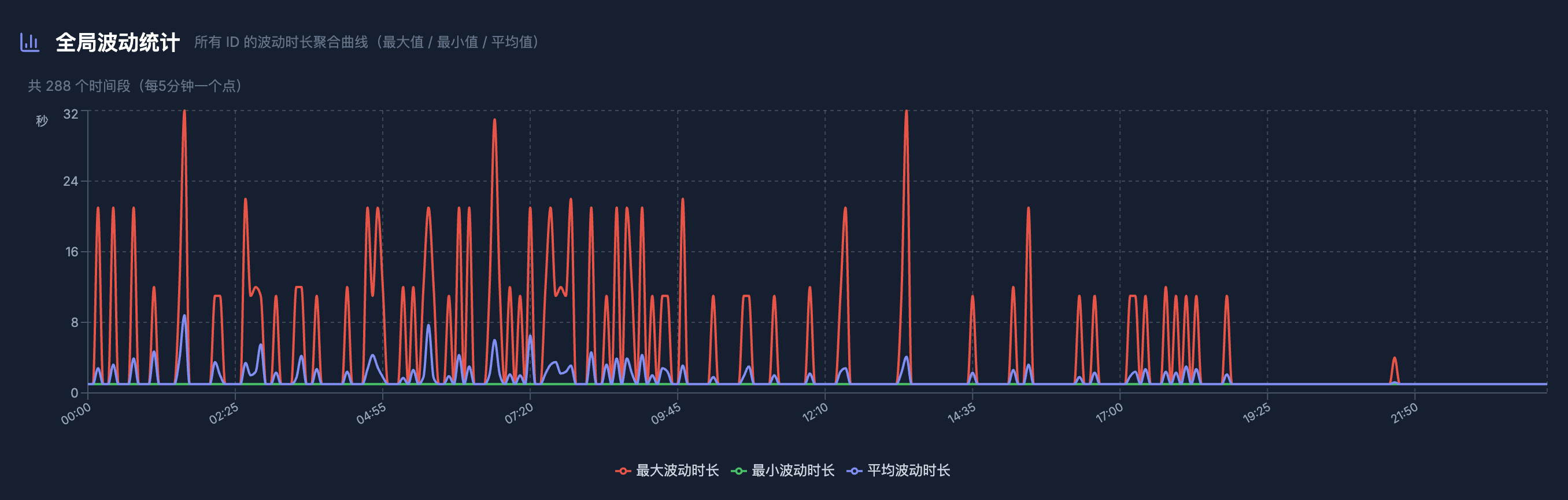
所以,需要分析是什么原因导致了数据回退。
为此,我开发了以下这些工具。
二、时钟误差检测工具
每个剧集的热度值,会在固定的时间统一刷新。
如果多个机器的时间存在差异,那自然就会有些机器刷新较慢,导致拉到旧数据。
基于此,我 vibe coding 了一个容器时钟偏差检测服务 Time Checker。
服务功能:一个基于 NTP 式四时间戳探测的中心化时钟偏差检测系统,用于检测多个容器之间的系统时钟是否一致。
系统架构如下:

实现原理很简单,通过两个机器之间互相发送一个数据包,各自记录发送时间与接收时间,从而能够解方程计算出时钟偏差,还能顺便计算出平均网络延迟。
NTP 式偏差计算原理如下:

跑完之后,发现各个机器之间的时间误差只有 1.5 毫秒,排除了时间误差这个方向。
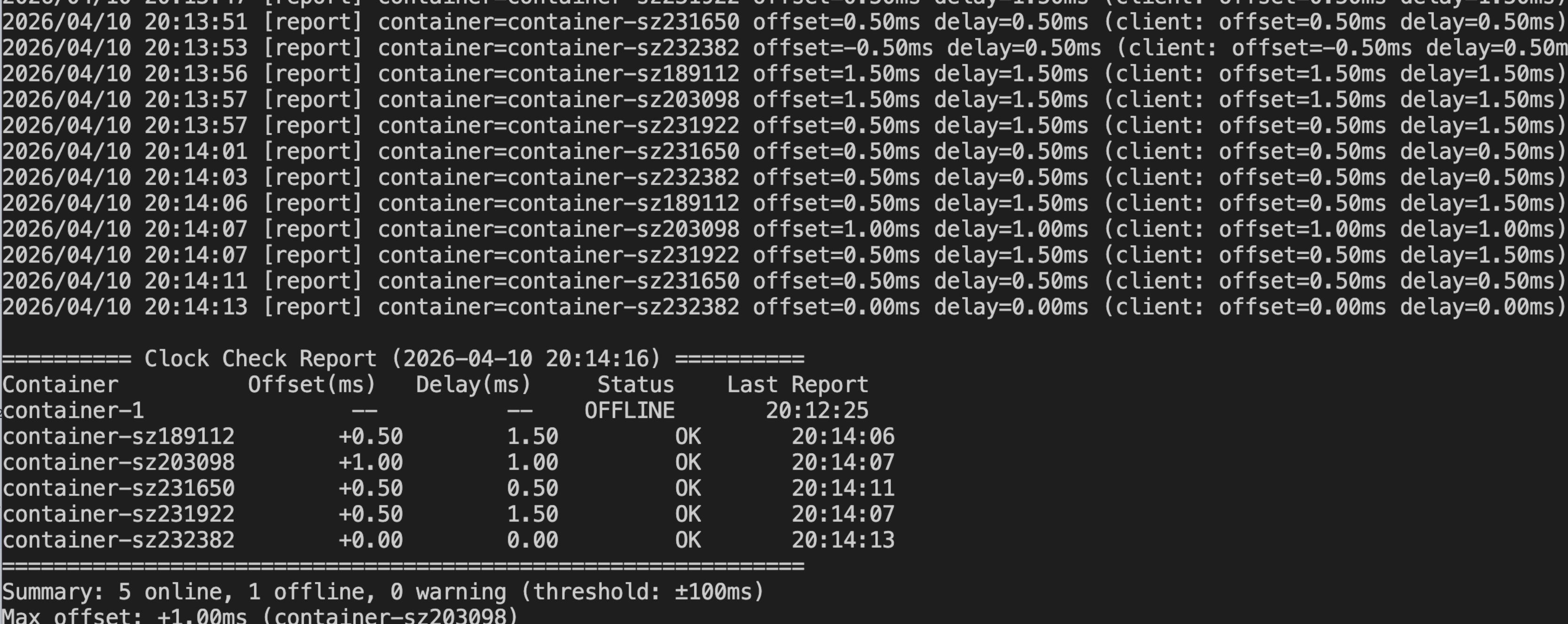
三、Redis 热度值实时采集与监控系统
既然机器时钟没问题,那底层的存储是否有问题呢?
如果存储数据本身就存在来回跳变,那上游系统自然也会发生来回跳变。
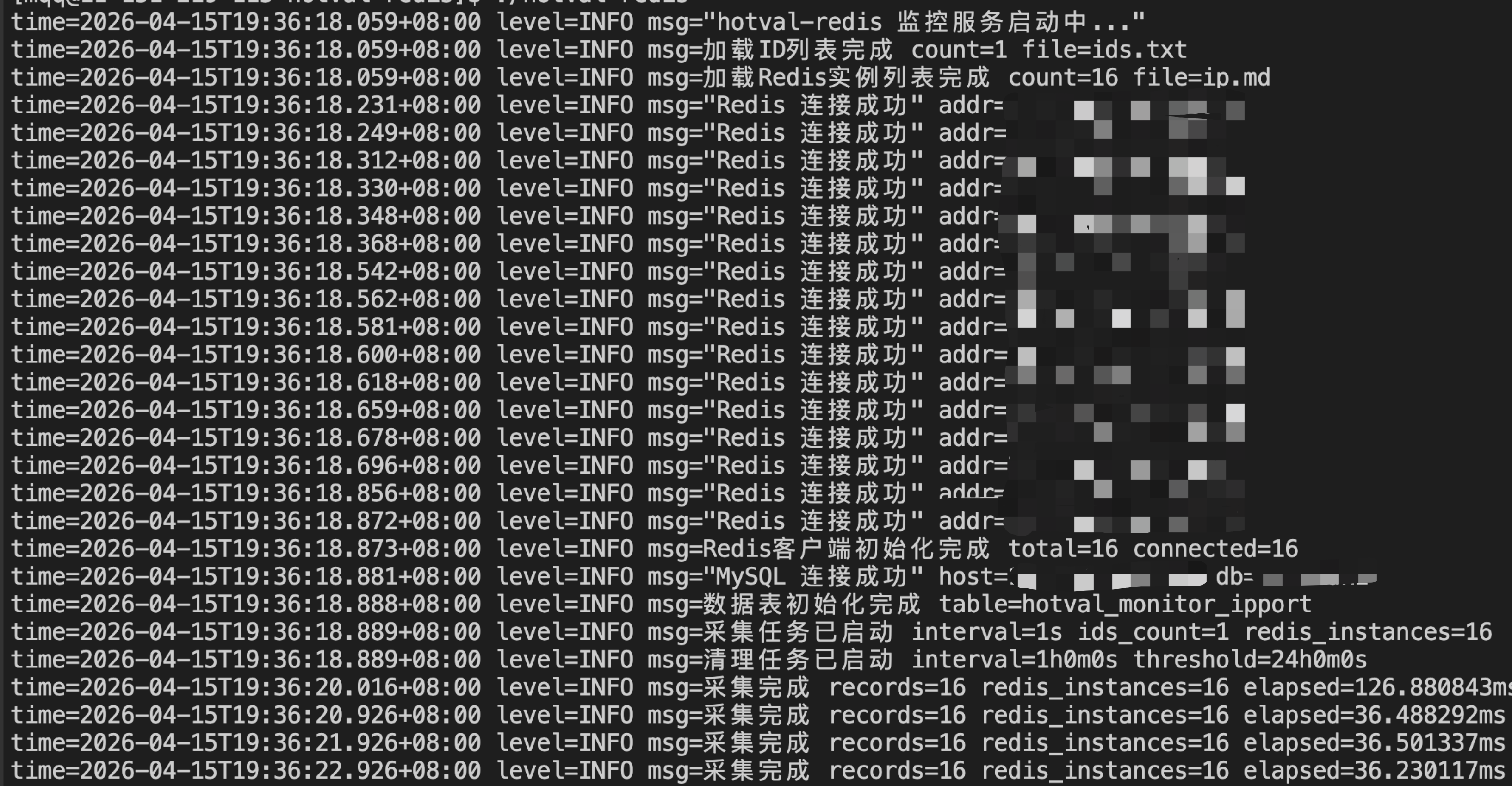
需求:实现一个高性能的 Redis 热度值监控后台服务,使用 Golang 开发,每秒从 Redis 中批量拉取 10 个剧集 ID 对应的两个热度值,解析后写入 MySQL 表中,并定时清理超过 24 小时的历史数据。
选择 Go 的理由:性能优先;Go 的并发模型(goroutine + ticker)天然适合定时采集任务,内存占用低,编译为单一二进制部署简单。
技术栈
- 语言:Go 1.21+
- Redis 客户端:github.com/redis/go-redis/v9(高性能,原生支持 Pipeline)
- MySQL 客户端:github.com/go-sql-driver/mysql + database/sql(标准库连接池)
- 日志:Go 标准库 log/slog(Go 1.21+ 内置结构化日志)
- 配置管理:硬编码 config 结构体(项目简单,无需配置文件解析库)
- 部署环境:Linux(直接运行二进制,nohup 或 systemd 管理)
- 构建:Go Modules
架构设计
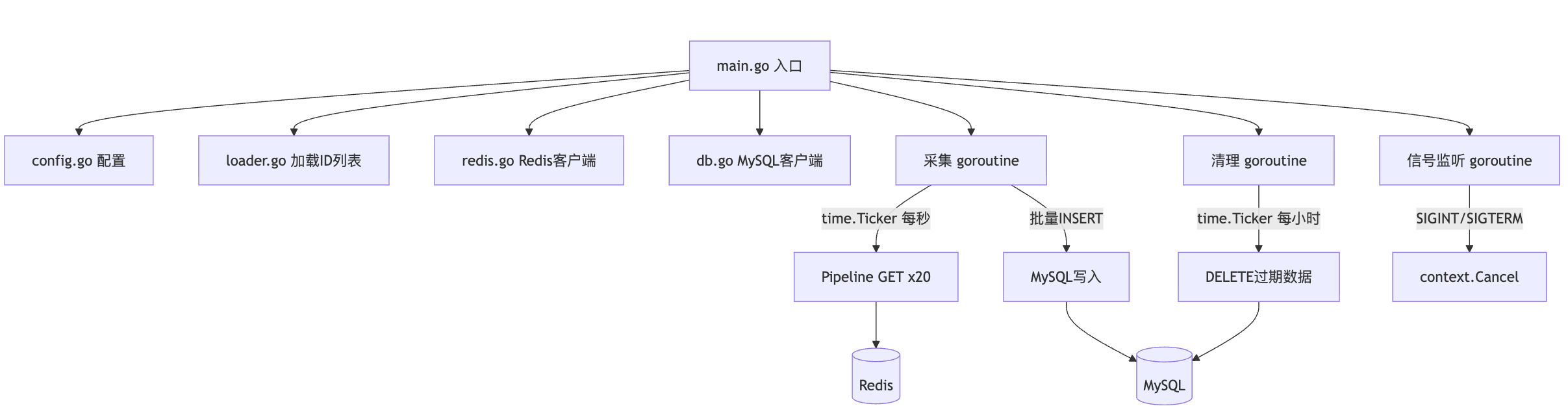
跑了半个小时,就再次遇到热度值波动。
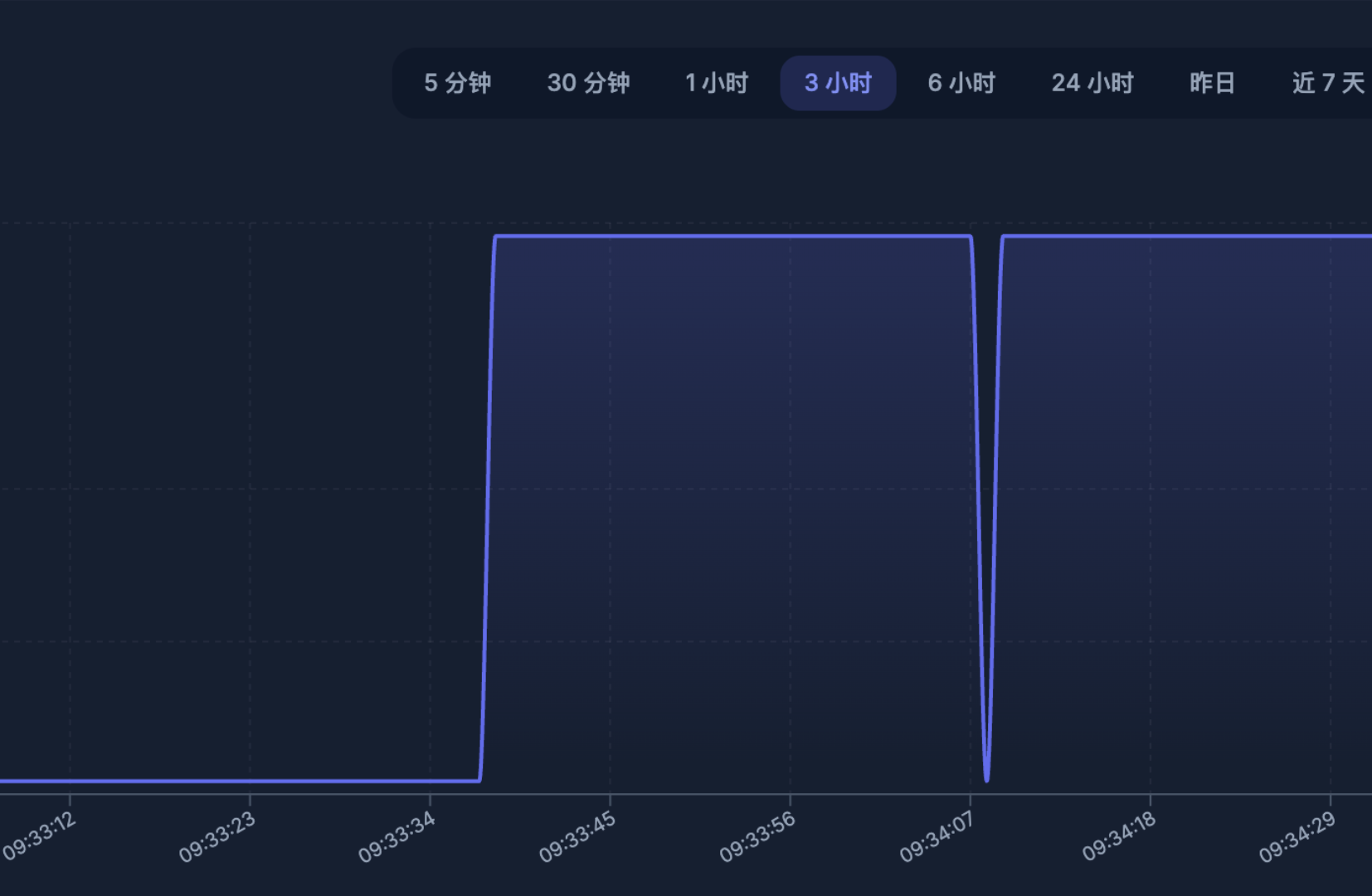
分析这一分钟 Redis 的流水,发现 Redis 数据是正常的。
分析 Redis 实例,发现 Redis 开启了副本读,会不会是副本的数据比较旧呢?
于是我又改造这个服务,改成每秒读取 N 次,看是否存在数据不一致。
最后发现 Redis 数据依旧是一致的。
四、缓存一致性监控系统
由于热度值监控系统是通过外网页面接口抓取的,所以无法获取到数据是从哪个缓存节点读取的。
而这个缓存组件有一个 debug 开关,支持对指定来源流量,把链路的缓存节点信息也返回出去。
于是我便开发了一个缓存一致性监控系统,打开 debug 开关,把缓存节点信息和数据都当做流水存到 DB 中。
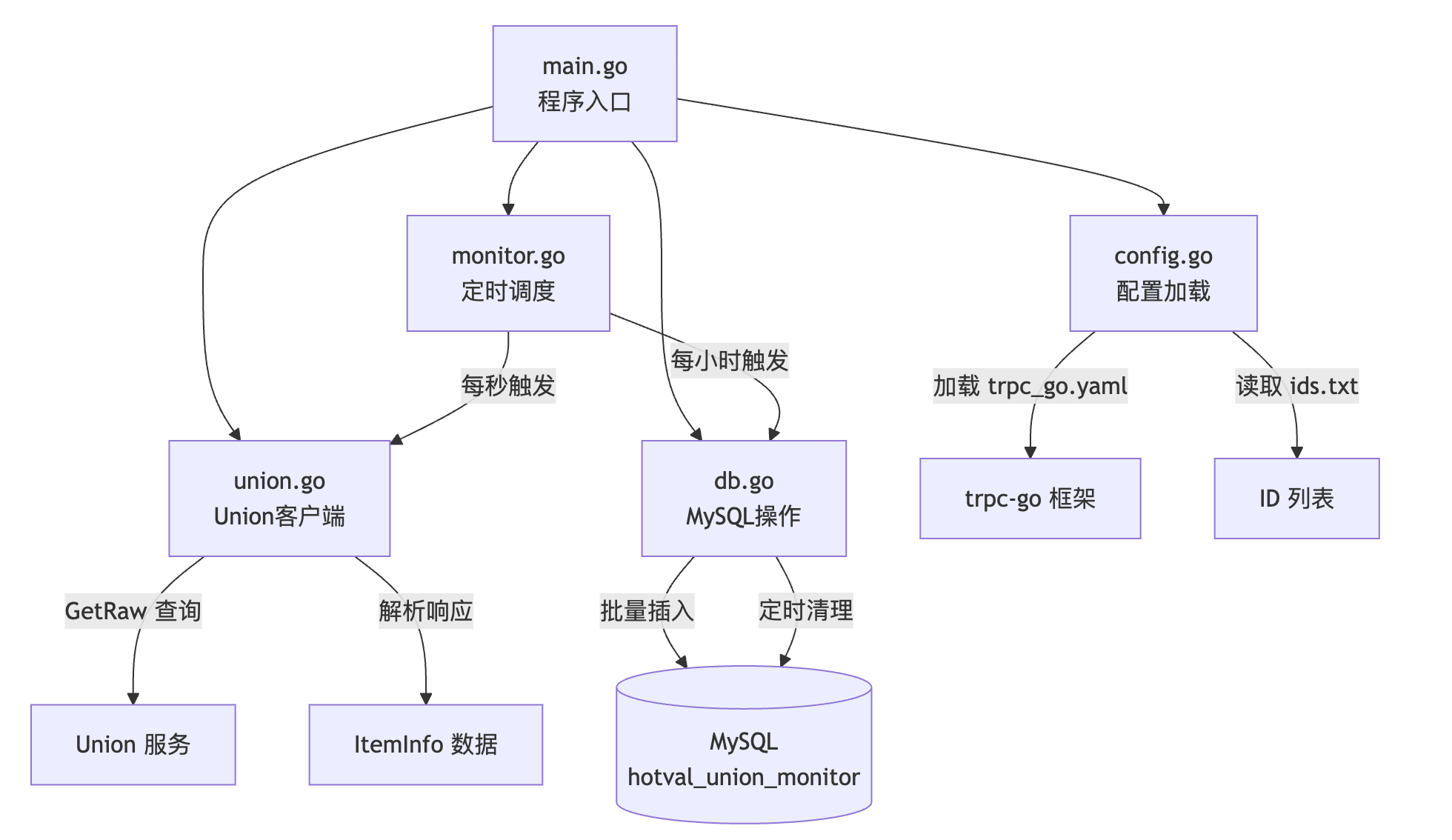
需求:一个 Golang 后台常驻程序,定时从 Union 接口拉取指定剧集 ID 的热度值数据,解析后存储到 MySQL 数据库,并自动清理过期数据。
系统架构:
数据流:
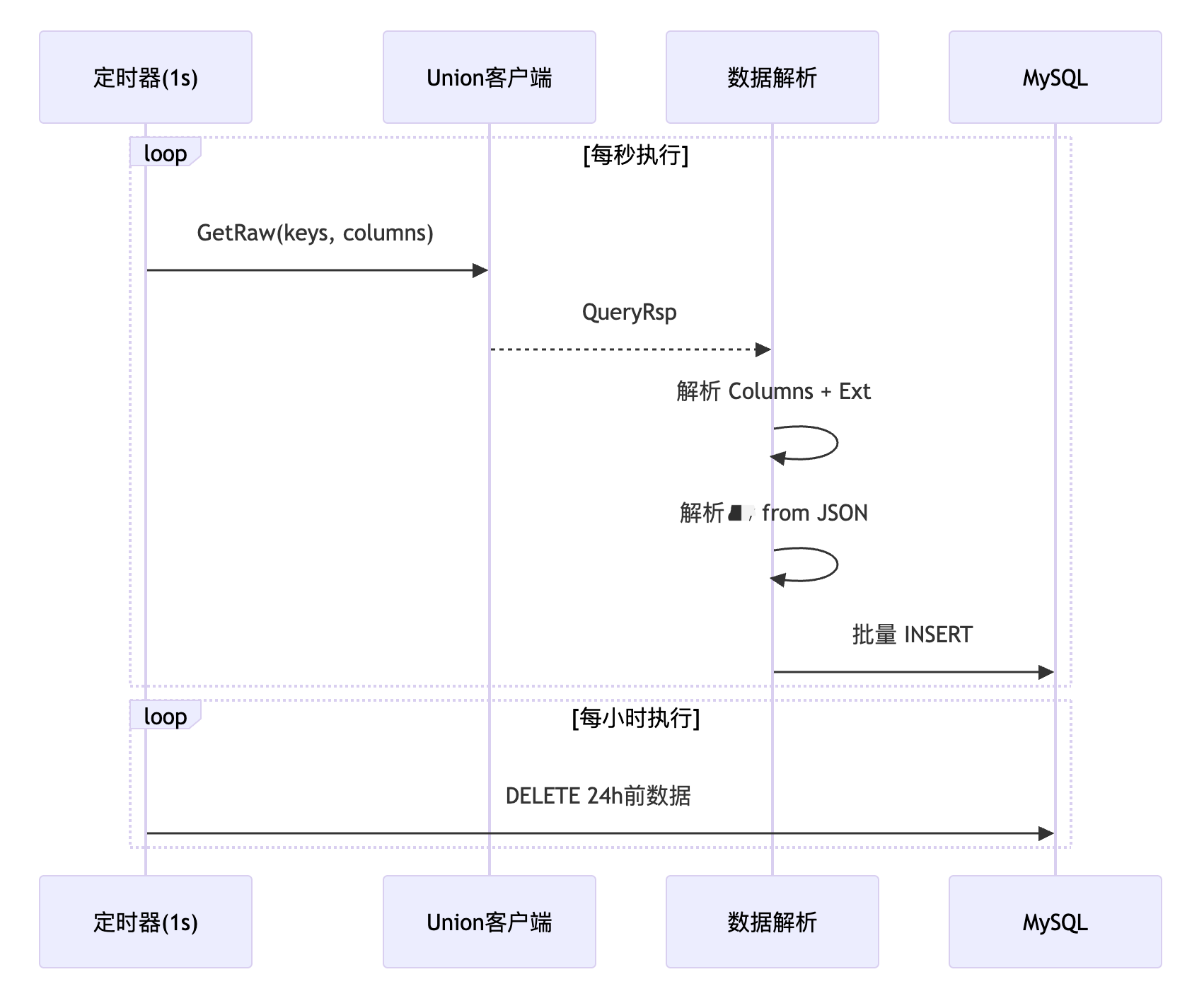
可以发现,这个系统和上面的 Redis 监控系统非常类似,区别在于把下游从 Redis 换成了缓存中间件,并且存储的数据多了缓存节点信息。
当热度值监控系统发现有不一致时,分析缓存一致性监控的流水,竟然没有发现数据跳变。
这时候,我就开始怀疑是不是热度值监控系统自身的问题了。
一个是 Go 系统,一个是 Node 系统,理论上结果应该是一致的,很奇怪。
五、HTTP 代理服务
上一小节提到,热度值监控系统因为使用外网接口,导致无法获取缓存节点调试信息。
那就有必要开发一个 HTTP 代理服务来代替外网接口,协议保持一致,从而可以返回调试信息。
需求:一个轻量级的 HTTP 网关服务,将 HTTP 请求转换为 UnionPlus 内部 RPC 调用,实现对视频/内容热度值数据的批量查询。
架构设计:

随后修改热度值监控系统,把返回的缓存节点信息也存下来。
当再次发生返回旧数据的 case 后,分析流水,发现返回旧数据的那个容器在数据变化后的这段时间里从来没被访问过。
也就是说,对于同一个容器,数据一旦变化,确实都返回新数据了。
那为什么偶尔一个节点在数据更新若干秒后,还会返回旧数据呢?
这时候,只有一个答案了:缓存节点确实返回了旧数据。
什么场景会发生呢?
其实,当确定缓存节点返回旧数据时我就想到答案了。
缓存系统在数据更新时,为了避免热 Key 的回源量太高,都会做一个 singleflight 功能。
singleflight 的含义是只让一个请求去回源。
对于其他请求,目前缓存中间件的策略是直接使用旧数据。
也正是这个策略,有概率使得访问量不大的剧集热度值返回旧数据。
六、Union 压测系统
上一小节提到,热度值返回旧数据的原因猜测是 singleflight 导致的。
触发场景是对应的剧集访问量太小,缓存节点持续很久都没有被访问,突然来的访问又存在并发,从而触发了 singleflight。
针对这个猜测,验证手段就是进行压测,看增加流量后是否还有这个问题。
于是,我又开发了一个 Union 压测系统。
功能:batch_union 是一个基于 tRPC-Go 框架的 Union 数据平台批量压测工具。
它按照指定的 QPS(每秒请求数)持续向 UnionPlus 服务发起批量查询请求,用于对 Union 读取链路进行压力测试和稳定性验证。
执行流程:

架构设计如下:

几分钟这个压测系统就写好了。
然后进行压测,发现热度值确实稳定多了。
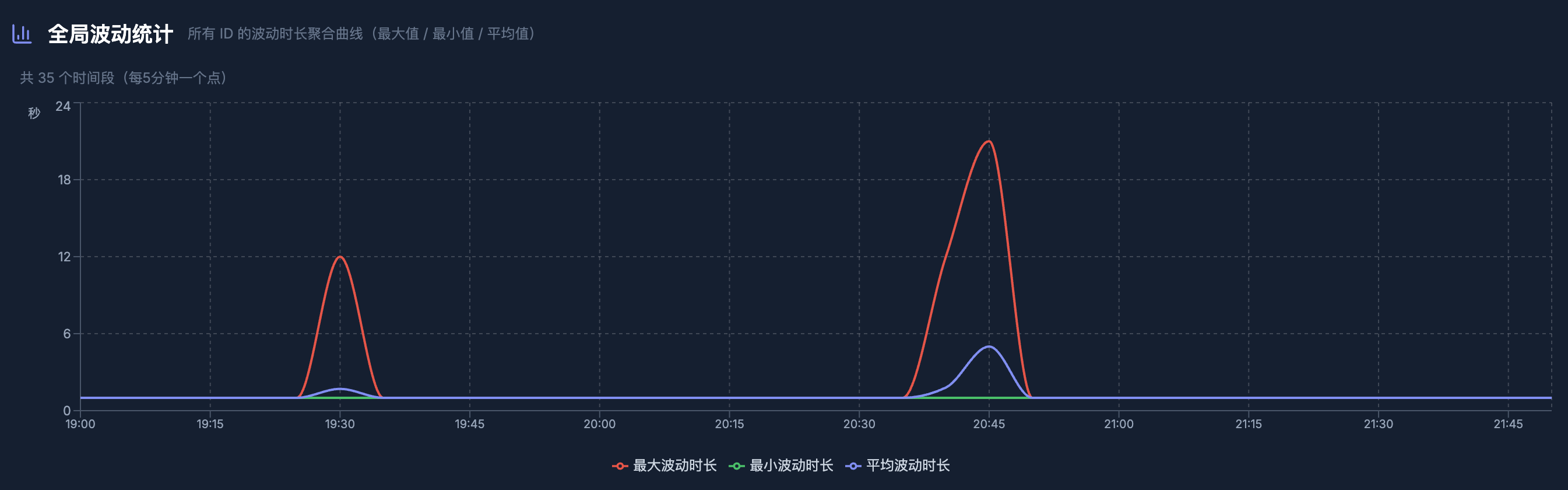
这个是压测前的监控:
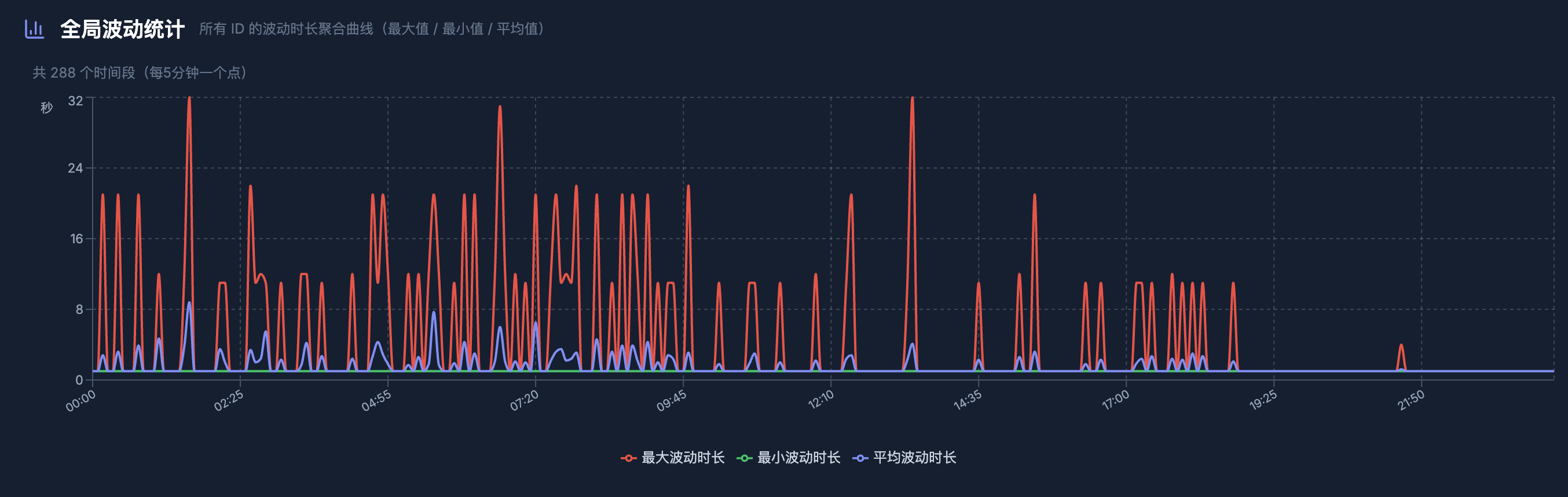
下面是压测后的监控,跳回旧数据的波动明显小了很多。
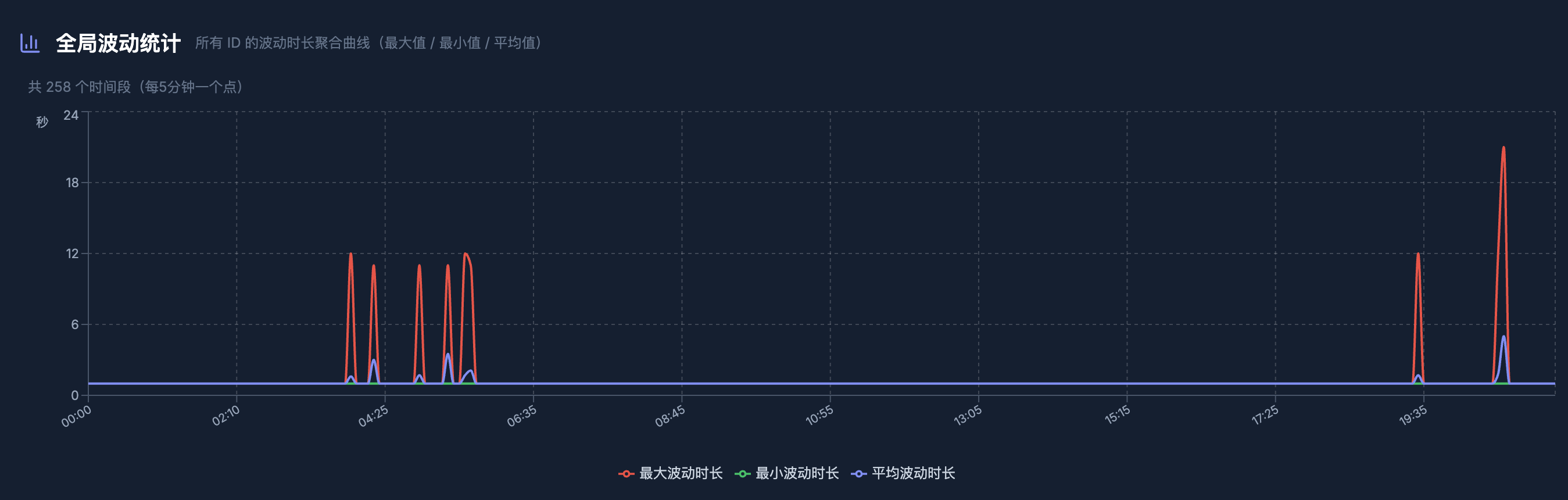
为何还是会偶尔有波动呢?
针对这些 case 去分析流水,发现是热度值统计错误。
在数据变化的时候,偶尔会丢失几秒的数据,从而导致系统误判为波动。
七、Go 重构 Node
上一小节提到,系统偶尔会丢失数据,从而导致误判波动值。
为啥会丢失数据呢?
那几秒 Node 刚好在定时压缩数据,负载跑得比较高。
看来跑数据还是不能使用 Node,使用高性能编程语言才是最优解。
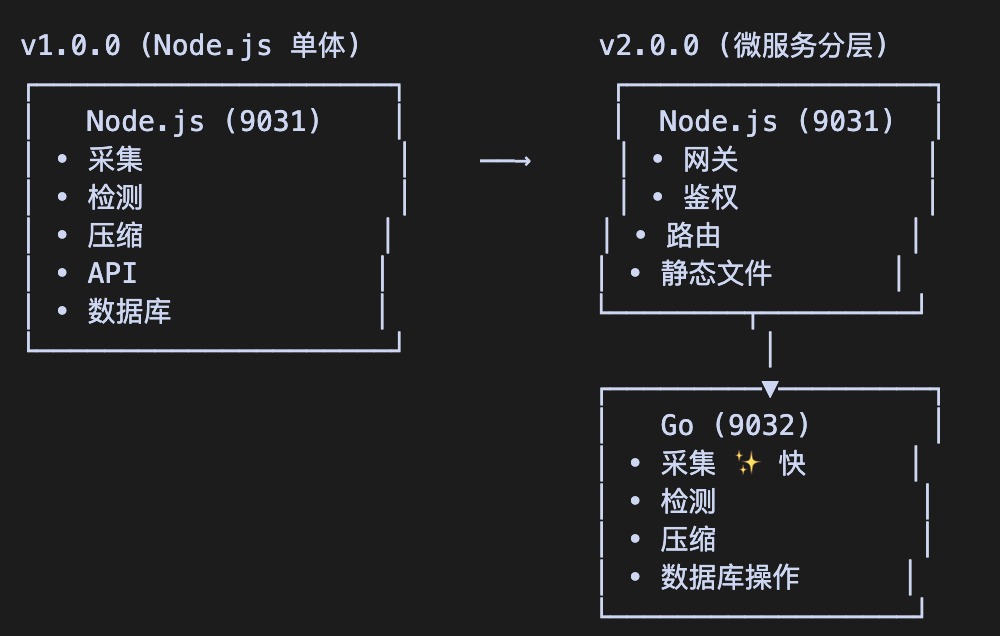
需求:将 HotVal 热度值监控系统中的数据采集模块从 Node.js Server 提取出来,使用 Golang 重新实现为独立的数据服务。
该服务负责数据采集、变化检测、数据压缩、数据修复、统计计算以及剧集管理 API。
同时对 Node.js Server 进行瘦身,使其仅保留前端页面服务和只读数据库查询,写操作代理转发到 Go 数据服务。
架构演进:
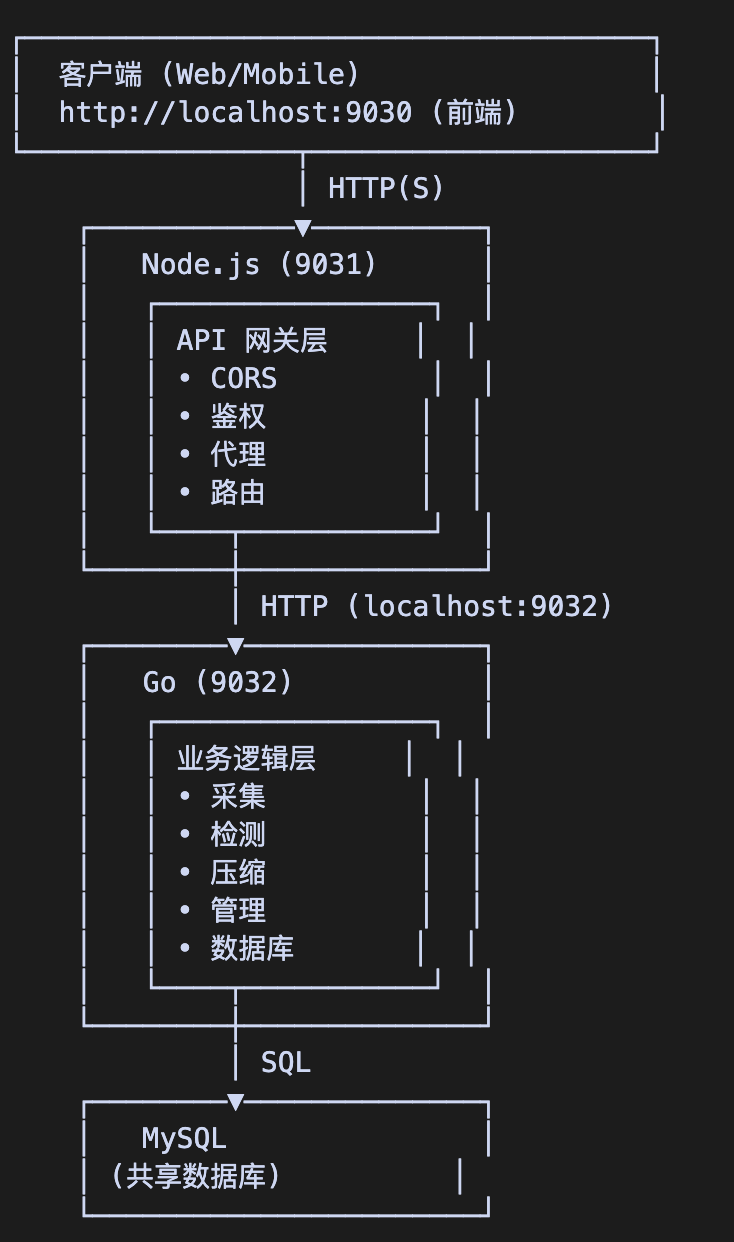
系统架构:
优化效果:

优化后,问题出现的概率确实进一步降低了,但由于增大流量只是降低概率,还是偶尔会发生一次。
针对这个问题,我之前其实有相关的优化规划。
产生旧数据的原因是相同 Key 并发过期时,只有一个请求下去更新。
如果其他使用旧数据的请求还有其他字段也需要去下游拉取最新数据,那么这些请求在回包之前,对于命中 singleflight 的字段可以再读一次缓存,就有很大的概率读到最新的数据。
当然,这个优化也只是进一步降低概率,但再读一次共享缓存的成本非常低,为何不再读一次呢。
八、最后
这两周 vibe coding 又使用了几亿的 Tokens。
但是借助 vibe coding 确实大大提高了效率。
如果是以前,写一个工具,半天就过去了。
工具稍微复杂点,一天甚至两天就过去了。
而现在,有任何想法,马上就可以花十几分钟做出一个工具来,可以马上去验证想法了。
部分场景下,效率提升确实是几十倍。
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号:tiankonguse
公众号ID:tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
