手把手教你设计hash表与LRU缓存库
作者: | 更新日期:
数组和链表分享完了,我们就可以设计很多东西了。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
一、背景
之前分享了《链表》系列、《队列和栈》系列、《数组和字符串》系列,今天我们来看看哈希技术,以及相关设计与实践应用。
如果你用过set或者map的话,应该知道这些数据结构可以做到快速插入、查找、删除等操作,而不像数组那样有O(n)的复杂度。
也许你听过,那些底层都是使用树实现的。今天我先教你们用哈希实现。
看完这篇文章,你会发现哈希这么简单。
另外业界的很多项目都使用到了哈希表来实现缓存,所以你看之后也能明白传说中的缓存是如何实现的。
二、原理
哈希表的关键思想就是使用哈希函数,将查询键映射到哈希桶上。
通过这样的操作,我们可以近乎于O(1)的复杂度完成各种操作。
具体来说。
插入时,根据哈希函数,确定数据键分配到哪个桶,然后将键值储存在这个桶。
查询时,使用相同的哈希函数,找到对应的桶,然后在桶里查找对应的键是否存在。
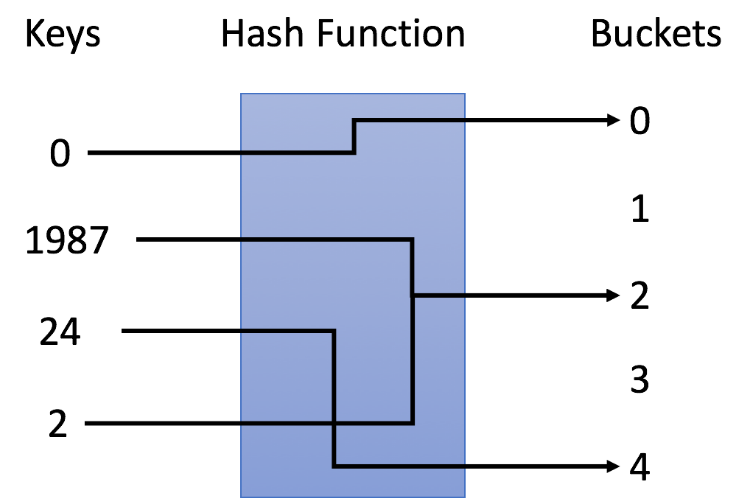
如下图,0 映射到桶 0, 1987 和 2 映射到桶 2, 24 映射到桶 4.
这里可以看到一个问题:不同的键可能映射到相同的桶里。
此时最简单的做法是,同一个桶里的数据使用链表储存起来。
当然,查找的代价是同一个桶里需要遍历链表。
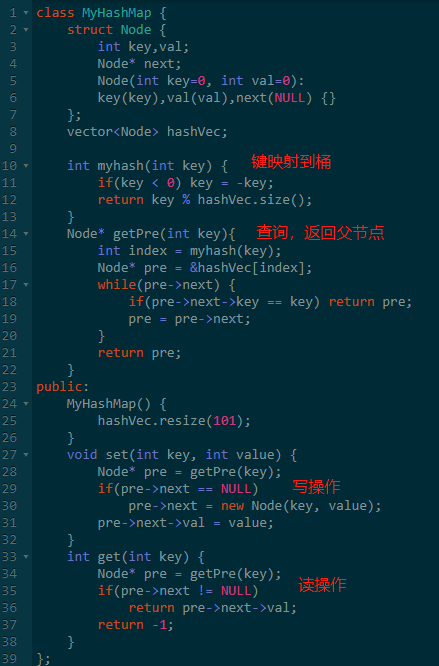
三、基本实现
实现哈希表的时候,需要注意几点。
1.桶大小一般固定(高级的会动态扩容)。
2.键的哈希函数固定。
3.查询操作最好封装起来,读写复用。
实现大概如下。
四、缓存
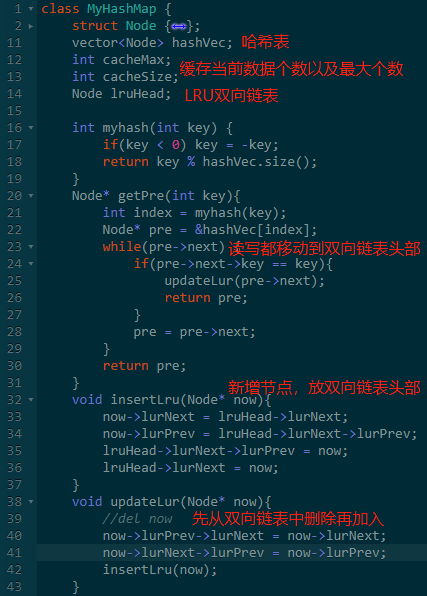
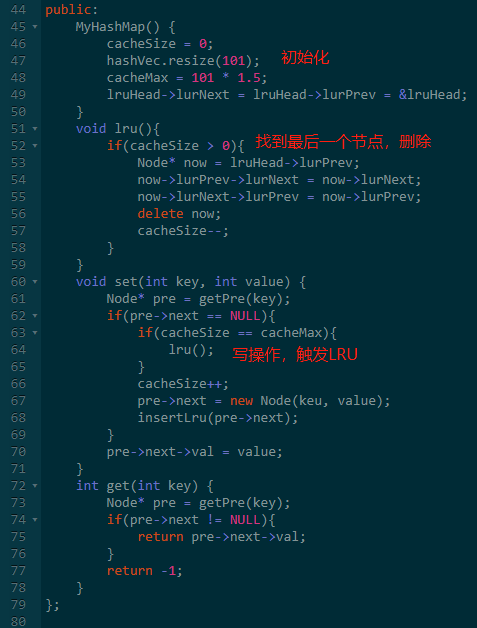
上面的哈希表已经可以当做缓存来用了,数据太多的时候性能太低,所以需要增加一直淘汰策略。
这里我们增加一个 LRU 淘汰策略。
要实现 LRU 淘汰,需要先明白 LRU 淘汰的意思。
LRU 的全称是 Least Recently Used,即最近未使用。
所以,LRU淘汰策略就是优先淘汰最久没有使用的数据。
那怎么找到最久没使用的节点呢?
一种方法是储存所有数据的访问时间,然后根据最小的时间找数据。
这个可以使用平衡树来实现,但是树的成本有点高,负责度也是O(log(n))的。
另一种方法就是双向链表。
如果我们将所有数据使用双向链表存起来,访问的数据移动到链表最前面,那需要淘汰的自然就是链表最后面的数据了。
由于是双向链表,我们可以直接定位到最后一个节点。
这样总体复杂度始终是O(1)。
所以实现 LRU 也很简单,只需要用之前教你们的 双向链表即可。
这里为了简单,我使用 STL 实现了一个简单版的 LRU缓存库。
如果你感兴趣,可以预先分配数据内存,然后通过下标来访问内存数据。 相信你实现了 LRU 缓存后,自己无论是对哈希表还是 LRU ,都会有不一样的理解。
四、最后
这里简单的介绍了 哈希表 和 LRU 缓存库。
实际的算法比赛中,我们不需要自己实现哈希表,一般直接使用set或者map。
set用来判断一个元素是否存在一个集合里面,map用来储存映射关系。
有了 set 和 map 在手,很多问题都迎刃而解。
-EOF-
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
