【技术】一致性HASH技术的困境
作者: | 更新日期:
三年前我曾介绍过一致性HASH可能会面临的问题,最近再次思考这个问题,记录一下。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
一、背景
三年前,我曾写过两篇文章来介绍一致性HASH技术。
第一篇《一致性hash基础知识》介绍的是一致性HASH的基础知识,也就是一致性HASH是什么,怎么实现的,为什么选择它。
第二篇《一致性hash基础知识(二)》则介绍了在项目实际使用一致性HASH的时,尤其是在高并发与高可靠的场景下,会面临哪些问题。
最近几天,我在思考系统自动化扩容的时候,再次遇到一致性HASH在高并发场景中必然面临的问题。
这些问题我称为一致性HASH的困境。
不是因为这些问题无法解决,而是有多种解决方案。
但是每种解决方案又都会引入新的问题。
我们面对这些解决方案的时候,需要作出抉择,作出取舍。
下面我们就分别来看看这些问题吧。
二、是什么
这里以缓存系统为例来简单回顾一下一致性HASH解决了什么问题,以及怎么解决的。
在缓存的数据量比较小的时候,我们单机就可以储存下所有数据。
那个时候,我们只需要将所有的缓存实例放在路由表下面即可。
业务每次请求的时候,会随机的路由到某一个缓存实例,然后做相对应的逻辑操作。
这里面有一个特征:一次请求可能随机路由到任何一个缓存实例。
即所有的缓存实例是均等的。
后来,随着数据量的增多,单实例不能储存下所有数据了。
单机不能全部储存,意味着命中率的下降,这个在某些时候是不能接受的。
所以我们希望通过多个实例来共同储存一份数据,比如三台机器,每台存三分之一的数据。
这个时候,业务请求的时候,就面临一个问题:该去哪个机器拉取数据。
正常情况下我们会维护一张路由表,然后把 KEY 通过 HASH 取模的方法找到对应的机器。
但是这种方法有一个问题:每次新增机器或者减少机器时,请求 KEY 与缓存机器之间的映射会发生很大的变化。
这种变化意味着,短时间内所有请求都将不能命中缓存。
作为一个高并发的缓存系统,这种状况往往是不能接受的。
所以我们引入了一致性HASH的技术来尽量防止命中率降低。
这里的关键思想在于:新增机器或者减少机器的时候,其他的机器与KEY的映射关系尽量保持不变。
实现方法是:将所有机器 HASH 映射到一个闭环区间上,定义机器节点顺时针上那个连续线段属于这个机器的。
这样,请求的KEY 也映射到这个闭环区间时,肯定会属于某一个机器。
而当添加或减少机器时,只会影响变更机器对应区间线段的映射关系。
假设我们有三台机器,每台机器占用三分之一的区间线段。后来要减少一台机器。
按照上面的规则进行管理的话,则有一台机器会占用三分之二的区间,而另一台机器不变。
虽然这种变化我们不能接受的。
因为删除机器后,剩余的机器的分布不够平均。
对应的解决方法就是虚拟节点。
每台机器不是映射到一个区间,而是映射到N个区间。
则减少机器之前,三台机器将闭环划分为3N个小片段。
减少机器时,N个小片段会重新归属与原先的两台机器。
这里片段是随机的,所以从概率学上看,N个片段将平均的分配到剩下的机器上。
这样,减少机器后,剩余的机器的分布已经是较为平均的。
三、不均衡问题
一致性HASH真实上线后,往往会发现每台机器的请求量并不是均衡的。
原因是一致性HASH算法只是环区间所有数字的均衡,但真实请求可能不是平均分布的。
面对这个问题,最有效的方法是增大虚拟节点。
因为增大了虚拟节点,机器会将环划分为更小的区间片段,我们就可能有更高的机会,将一个流量较大的区间片段分成多部分。
从而起到流量更均衡的作用。
PS:今天我就做了这样一件事,之前内部的负载均衡组件默认是划分100个虚拟节点,而最高支持1000个虚拟节点。
那毫无疑问,我将所有的一致性HASH环调整为了1000个节点,之前困扰我很久的不均衡问题初步得到缓解。
四、热点问题
有时候,我们已经将一致性HASH的虚拟节点调至最大了(假设有上限),发现流量依旧不均衡,甚至部分节点CPU跑满。
这时候甚至扩容都无法解决问题。
这种部分节点的流量总是比其他机器的流量高的问题,称为热KEY问题。
这里面原因是多方面的,有可能确实是概率因素,但更多的是有单KEY流量太高。
此时我们怎么扩容或者增大虚拟节点个数都是无效的。
因为一个KEY只会路由到一个机器,而这个KEY的量那台机器支持不住,那只能想其他办法了。
面对热KEY问题,常见的方案有两个半。
先说那半个方案。
降低热KEY机器的权重,也可以理解为降低虚拟节点的个数(其他的不变)。
当一台机器的虚拟节点个数降低时,这个机器分配的区间就会更少,那路由来的流量就更低。
之所以说是半个,是由于这个方案并不能彻底解决问题,而只能降低问题的概率,即缓解问题。
第一个方案是维护多个一致性HASH环。
可以想象,目前只有一个一致性HAHS环,一个机器负载太高,增加节点无法解决问题。
那增加一个一模一样的一致性HASH环,流量即可导走一半,这样热点问题就可以解决了。
还有热点?再增加一致性HASH环。
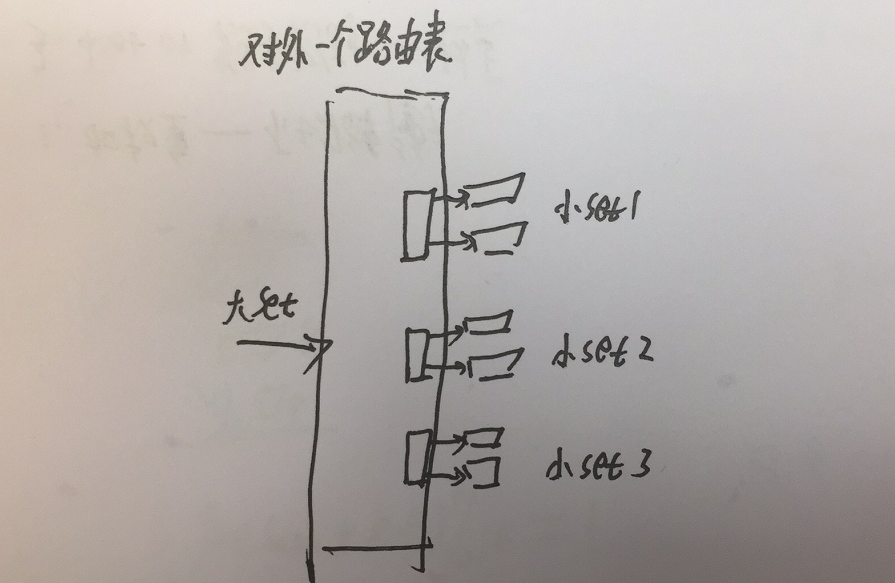
这种一致性HASH环,我们内部称为小set。
含义代表小set是一个一致性HASH环,能支持指定指标流量的最小单位。
当流量上涨超过指定指标时,我们就增加一个这样的最小单位。
具体实现上,对外一个路由表,路由层会有一定的策略将当前请求路由到其中一个小set。
这个策略对于所有小set是均等的,这样热key就会被均摊到不同的小set,从而解决热KEY问题。
这种架构是一种可无限扩容的设计。
但是命中率不足需要加节点时,会发现成本很高,所有一致性HASH环都需要扩容,成本巨大。
当然,这里面还有维护成本。
每一个小set都有自己的路由表,由于某些原因小set的机器还需要知道自己属于哪个大set时,配置表将更为复杂。
如果服务的发布系统是我自己做的话,可以集成这些功能,从而做到高效扩容,高效管理。
但是在我们公司,所有的功能模块都是独立的,从而使得没办法集成这些定制化的功能。
所以目前还需要人工维护这些配置表,扩容成本相当高。
第二个方案是一致性HASH环下的节点不再是机器,而是一个路由表,每个路由表下又有多台机器。
这个时候,热KEY就可以通过多台机器来均摊流量。
这种设计其实我在之前分享的第二篇一致性HASH文章中介绍过。
后来,由于某些原因,没有选择这种设计方案(现在我在考虑要不要改造为这种模式)。
这种设计其实和上面的小set设计很像。
但是有一个天然优势:按需扩容。
由于只有一个HASH环,某个节点负载高了,对应的节点下面增加机器即可。
节点的整体命中率降低了,增加一组节点即可。
而命中率这一方面,小set是处于劣势的,因为所有小set都需要去扩容,成本太高。
当然,这种方法也面临着小set的管理问题。
由于每个节点都是一个路由表,我们就需要维护很多路由表。
如果这些路由表不能和管理系统结合,那将来扩容时,都会有很高的成本。
五、扩散问题
大家使用一致性HASH的时候,可能都是只有一个路由KEY。
但是对于批量请求的缓存服务,就涉及到一致性HASH扩散问题了。
比如我们的一个HASH环下有5个节点,业务一次请求批量拉取30个KEY,业务的请求是10W/s。
此时我们该如何使用一致性HASH支持这个需求呢?
可能有些人没看出来问题是什么。
假设我们30个KEY分别一致性HASH向下拉取数据,那么对外路由层QPS是10W/S,对内缓存层QPS是300W/S。
这么大的流量,网络操作等非业务操作就会消耗很多资源。
所以一般批量请求需要聚合数据批量向下请求。
比如30个KEY平均的均摊在5个节点上,每个节点的6个KEY可以一次请求去拉数据,而不是6次请求。
但是这样做对内的QPS也有50W/S,其实这个量也不小。
此时,当负载过高时,我们增加一致性HASH节点无法解决问题。
为什么呢?
假设5台机器,对外QPS是10W/s,对内聚合请求QPS是50W/s(每个节点10W)。
一致性HASH增加5个节点,这时对内的聚合请求QPS就是100W/S了,每台机器依旧是10W的QPS。
另外,这时候扩散更严重,意味着网络操作等额外操作会消耗更多的资源,
根据这个结论,我们可以反推出另一个结论:一致性HASH下应该有多少个节点?
答案是能够满足命中率指标的前提下(如储存下全量数据),节点数应该尽量的少。
因为多余的节点不仅不能增加命中率,反而会因为扩散更严重而更消耗资源。
PS:昨天(3月26号),我有一个SET的命中率特别高,单机即可储存下全量数据。我尝试较少节点,CPU下降了好几个点。
六、自动均衡
前面我们提到过。
面对热KEY问题,我们可以手动降低热KEY所在机器的虚拟节点数来降低这个机器的流量,从而缓解问题。
这个调整其实就有动态负载均衡的味道。
我们可以实现一个监控程序来监控每个节点的负载。
当遇到部分节点负载过高时,就调小高负载节点的权重,调大低负载节点的权重,从而使得各机器的负载较为平均。
当然,这个是理想的操作,是我自己首次提出来的,但是内部还不支持。
这里我们来谈谈这种理想操作该如何实现。
这里只有一个问题:怎么判断节点的负载高低与权重的关系。
对于高并发服务,其实有三个基本指标:请求量、失败量、延时。
我们可以通过这三个基本指标计算出一个权重来。
对应的关系是:与失败量负相关、与延时负相关、与请求量正相关。
那可以写出一个简单的公式来:权重 = (请求量 - 失败率)/耗时
当然,这个公式只是基础模型,具体实现的时候可能会加一些系数或者什么来使得负载更均衡。
另外,使用动态负载的时候,还需要考虑一个问题:抖动。
假设负载都是正常的,不能因为我们的算法导致某台机器的流量一会高一会低。
这个抖动也势必会使命中率发生抖动,所以需要想办法避免。
比如一段时间内只调整一次,或者权重忽略低位等等,方法很大。
七、最后
这里谈了一致性HASH在高并发服务上可能遇到的问题,比如负载不均衡问题、热KEY问题、批量请求扩散问题。
还介绍了一种理想模型:自动调整一致性HASH的权重从而做到自动调节负载。
如果你没有真实使用过一致性HASH,或者没有高并发服务的经验,可能你看不懂这篇文章吧。
-EOF-
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
