忐忑的解决了一个别人的问题
作者: | 更新日期:
前几天极度忐忑的帮别人解决了一个问题,回顾一下。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
一、背景
16号的时候,我在文章《二叉搜索树就是这么简单-基础篇》里提到,本来15号要发一篇文章,结果突然工作上遇到了一个紧急的问题,就被耽搁了。
今天站在我的角度回顾一下这个问题。
二、基础知识
我负责一个服务,如下图。所有业务都是从我的服务读数据的,其他服务都是其他同事负责。
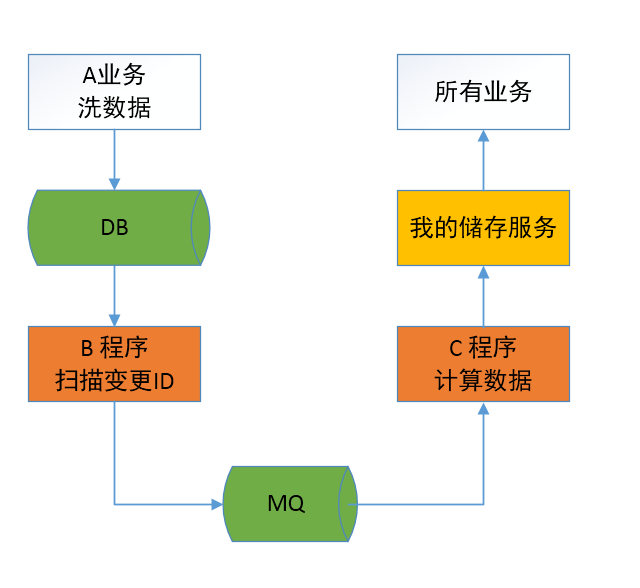
这个流程大概是:
- 基础数据在 DB 中。
- 有一个 B 程序可以从 DB 中获得有变更的 ID 列表,发给 MQ。
- 一个 C 程序从 MQ 获取 ID,计算后的数据写入到我的储存服务。
- 业务通过我的储存服务来读数据。
这个流程其实也没什么大的问题。
只是 B 程序 和 C 程序原先的负责人在一个月前转岗走了,新接手的同事不熟这块。
三、出现问题
当 A 业务在吃饭时间开始大量更新数据(俗称洗数据),我的储存服务收到了最大值告警(我自己设置的最高访问量,超过会进行短信通知)。
问清楚是预期洗数据后,我看了这个服务下的四五个子模块的监控,一切正常。
于是我警告他们:我的服务都正常,但是可能有其他业务处理不过来(还有其他服务接收变更通知)。
大概2.5小时之后,收到部分投诉,我的储存服务拉不到最新的数据。
一个老大也跑过来问出了什么问题。
我通过之前自研的一键定位问题工具,只用了三秒就找到了问题:上游没把数据写到我的储存服务,我的储存服务正常。
于是赶紧通知 A 业务,洗数据挤压了,他们停止洗数据。
四、解决问题
大概等了 10 分钟,有更多的人在投诉了。
和他们沟通后,他们的结论是: 通过 MQ 监控发现 MQ 没数据挤压,怀疑是 B 程序挤压。
我给出了第一个解决方案:B 程序肯定有一个配置偏移量,马上修改偏移量为最新的时间,重启服务,就可以直接跳过历史数据。
他们回答不知道怎么配置这个偏移量。
大概又等了 10 分钟,投诉的人更多了。
我冥思苦想,给出了第二个方案:修改所有变更数据的时间为洗数据前的时间,重启服务(这样相当于修改了偏移量)。
我有建议安全起见可以先修改一个数据测试一下。
他们回答风险太高。
又等了 10 分钟,问题还没问解决。
于是只好让他们把需要写的数据发给我,我手动写到我的储存服务中。
在这个过程中,我猜想:也许是 C 服务挤压了,快速跳过 C 服务的历史数据即可。
于是和对应的同事讨论出了第三个方案:重新搭建一个 MQ + C 服务,这样就可以解决新数据问题了。
又等了一小会,发现第三个方案也没那么简单。
于是我只好使用第四个杀手锏方案:打扰一个离职一两年的朋友,之前 B 服务和 C 服务他曾负责过一段时间。
于是我根据要到的解决方法,申请 C 服务所有机器的权限,开始操作了。
操作前,我犹豫了三秒:
要不要操作呢?
这个服务不是我的,我完全不了解。
有可能那个朋友记错了,操作后这个服务就彻底死了!
风险太大了,负责这个服务的同事都不敢动,我敢动吗?
此时我想起了一句话决与择的哲学话题。
最后我还是决定勇敢的试一试,于是操作了一台,等了一分钟,看我的储存服务的监控:调用量确实降了。
于是又马上操作了一大半,再去看我的监控时,发现我操作的机器的来源访问量都是 0 了。
我心里马上凉了一大半。
恰好此时,老大的老大过来找我手动写几个数据,想到我操作机器都没量了,可能把服务搞死了,心里有点慌,手自然就有点发抖。
老大的老大说不要慌,慢慢来(他不知道我刚才做了什么,自然不知道我在慌什么)。
我稍微稳定一下情绪,先把老大的老大反馈的问题都手动写到我的储存服务里。
等他们走之后,我又找了几台机器测试。
操作前发现在不断的刷日志,代表在处理数据;操作一台,就马上没日志了,代表没量了。
就这样试了三台都是这样,我的心情是非常忐忑的。
赶紧跑过去问负责这块的同事是否有做什么操作(也许他们做什么把量弄没了)。
他们说没操作什么。
我赶紧问:如果扩容一台机器需要做什么特殊操作吗?直接安装就可以吗?
他们回答:安装就可以,不过没机器扩容了。
我听后很高兴,即使我把服务搞挂了,可以缩容再扩容,这样肯定是可以恢复的。
结果卸载再安装后,发现服务依旧没量。
此时我的心情忐忑到了极点,按道理这样就可以有量的,结果竟然和预期不一样。
于是我再次跑过去问他们在干什么。
有人说他们把 B 服务搞挂了(后来才知道是主动停服了)。
我听后稍微安心一些了,也许是 B 服务不发数据了, C 服务才没量的。
于是回来后,把所有机器操作了一边。
接着在群里帮他们一个个的手动修复数据。
后来不知什么时候,我突然发现 C 服务有量了,马上过去问他们做什么了。
他们说 把 B 服务启动了,而且测试一切都恢复正常了。
此时,我忐忑的心才彻底恢复平静。
此时我想出第五个方案:只需要对 C 服务的所有机器缩容再扩容就行了。
当然,这个是马后炮了。
五、哪里出问题了
事后,他们在讨论:到底是 B 服务的问题还是 C 服务的问题,需要给出具体原因给老板。
而他们操作了 B 服务,我操作了 C 服务,到底是哪个操作修复了问题。
我猜想是 C 服务处理不过来,他们说也可能是 B 服务加载的数据太多。
每次发中转后,C 服务都及时处理了,所以 MQ 上没有挤压,由于监控是分钟级别的,也看不出毛刺。
听着都很有道理,于是只好找出代码来看是谁的问题了。
一群人围观一起看了代码,发现 C 程序虽然用了 MQ,但是实际取完数据马上向 MQ 回 ACK,因此 MQ 看着没有挤压(为了提高并发量,也说的通)。
于是他们猜想:C程序有一个个数限制,超过个数就丢弃。
结果看代码,发现超过个数后没有丢弃,而是进行短信微信告警,但是告警接收人是已经转岗的同事。
好吧,我猜想今晚他的短信和微信肯定被轰炸了。
但是,看到这里,还不能证明是 C 程序的问题,需要证据。
于是我借同事的电脑去查看机器内存的监控,根据这个内存数据,彻底揭开了这个问题的答案。
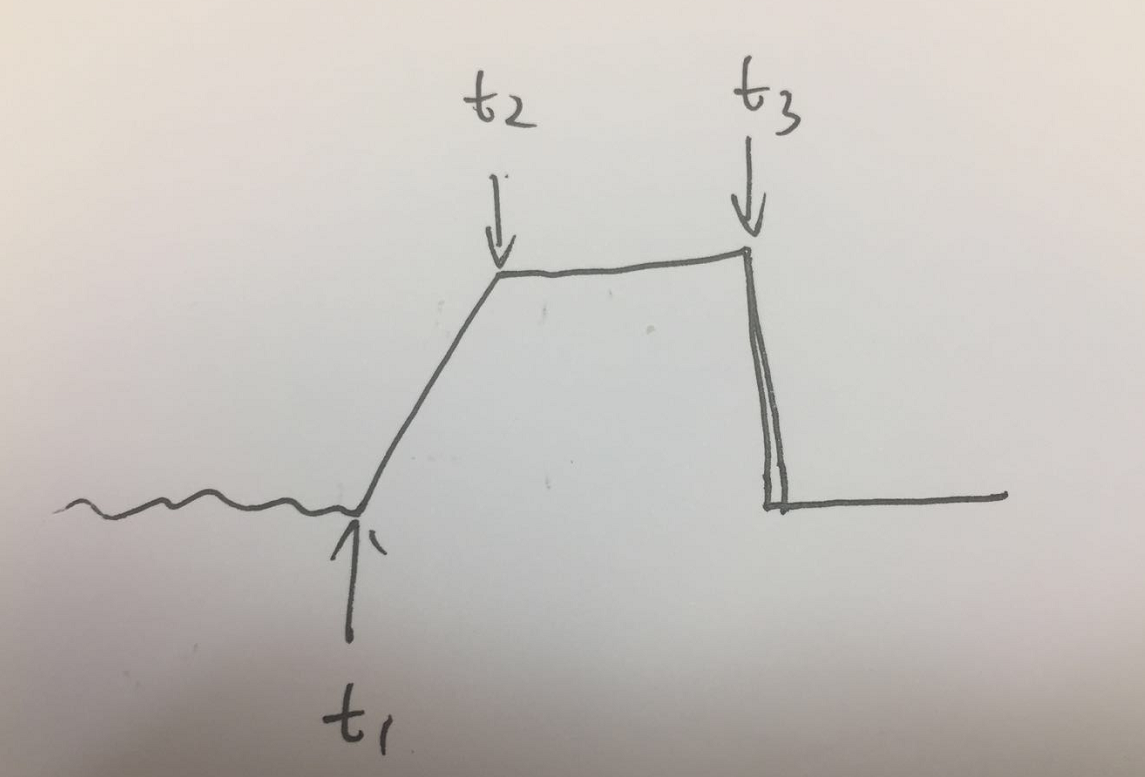
根据上图可以看到,内存曲线有三个关键时刻。
t1时刻是洗数据时间,由于处理不过来,内存越来越大。
t2时刻是 B 程序停服时刻,由于不再生产数据,内存停止增长。
t3 时刻是我操作 C 程序的时刻。清理数据,内存恢复。
有同事问为啥t2~t3是平的,我回答因为挤压的数据量太多了,处理量几乎可以忽略,所以斜率是平的。
自此,一切都解释清楚了。
后面他们应该需要做的事情不少,毕竟这个服务暴露了不少问题。
不过他们是在内部讨论这个事情的,具体细节我就不清楚了。
六、最后
事后想想,这个问题迟迟没有解决,关键是谁都不了解那两个服务的细节。
而这个问题其实他们很早就知道了,但是由于这个服务太重要了,也迟迟不敢动。
于是,最终只能眼睁睁的看着问题爆发了。
类似的问题其实是悖论,无法解决的。
很多的时候,我们知道这个问题很重要,但是不被上面重视,总是有其他紧急的事情需要处理。
直到有一天,这个重要的问题爆发了,然后大家各种忙,各种熬夜,还造成很大的影响。
如果预先认识到这个问题时,就处理这个问题,也许后面的生活就会平平静静的渡过了。
-EOF-
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
