leetcode 第 206 场算法比赛
作者: | 更新日期:
图论题果然是一个难点
本文首发于公众号:天空的代码世界,微信号:tiankonguse
零、背景
昨天一觉睡到下午四点多,没有参加 leetcode 的年度个人赛,也没参加计蒜客的 acm 比赛。
但是 leetcode 的双周赛还是尽量要参加的,这是一种底线吧。
不过今天再次被 leetcode 的卡超时卡住了,而且这次是卡 STL,换成数组就过了。
看来以后能使用 c 语言的算法还是尽量不适用 STL 了,太坑了。
一、二进制矩阵中的特殊位置
题意:给一个矩阵,如果一个坐标值是 1 且当前行和列其他位置都是 0,那么算一个特殊坐标。
求特殊坐标的个数。
思路:
第一个方法是按照题意暴力枚举计算,复杂度O(n^3)。
第二个方法是预处理每行每列有多少个 1。
然后枚举坐标,利用预处理的信息按照题意判断即可。
复杂度:O(n^2)

二、统计不开心的朋友
题意:有 n 个人互相认识是朋友,给出每个人的朋友从高到底的亲密度关系。
这里已经将 n 个人分成了 n/2 组,求不开心人的个数。
不开心定义:假设有两个分组x,y 和 u,v。
如果 x 与 u 的亲近程度胜过 x 与 y,且u 与 x 的亲近程度胜过 u 与 v,则称 x 不开心。
思路:按照题意,枚举判断每个人是否开心即可。
对于每个人,自己的分组是固定的。
需要枚举其他朋友,判断那个朋友是否会使自己不开心。
两个分组确定后,还需要遍历关系判断亲密程度。
复杂度:O(n^3)
优化:亲密程度可以预处理得到是第几个亲密的,然后O(1)比较即可。

三、连接所有点的最小费用
题意:给 n 个坐标,坐标之间的距离是曼哈顿距离,求最小生成树。
思路:并查集或者 prim 都可以。
这道题我被卡超时了。
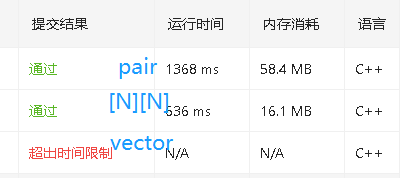
因为边我使用的是vector<vector<int>>来储存了。
各种reserve优化都不行,最后改成[1001][1001]变通过了。
赛后看有人使用vector<pair>通过的,我比较了下耗时,相差果然很大。
代码如下,标准的并查集:

四、字符串局部排序
题意:问能不能不断对字符串的字符串排序,使得字符串变为目标字符串。
思路:
如果对一个字符串排序,我们可以通过不断对相邻字符串冒泡排序来做到这件事。
所以只需要看相邻子字符串的排序,这样进行一次,对原字符串的影响也最小。
先来看目标字符串的第一个字符 c。
为了通过若干次子字符串排序,使原字符串中的第一个 c 移动到最前面。
那原字符串中第一个 c 的前面肯定不能有比 c 小的数字。
因为如果存在,c 是无论如何也移动不到最前面的。
将 c 移动到最前面后,剩下的问题就是相同的子问题了。
不考虑性能问题,就可以在 O(n^2)的复杂度内暴力实现了。
优化:能不能通过预处理,快速找到 c 并移动 c 呢?
这里涉及三个问题:
1、怎么快速找到第一个 c。
2、怎么快速判断第一个 c 前面没有更小的数字。
3、如何在不修改字符串的情况下,使得子问题不受 c 的影响。
其实通过统计每个数字第一次出现的位置就可以解决前两个问题。
而将 c 移动到最前面意味着,c 的第一次出现位置需要更新,即寻找 next c。
这个通过预处理每个数字下次出现的位置即可解决。
复杂度:O(10 n)

五、最后
这次比赛中,第三题好坑,调了五十分钟。
最开始是 vector 储存边的并查集,超时。
然后各种 reserve 和 resize 提前申请内存来优化。
后来改成 prim 也超时。
期间还犯了一个很严重的错误,我以为只剩一组数据了,就写死答案了,结果还有其他数据卡超时。
最后改成 [N][N] 储存边的并查集,一下就过了。
再来看下耗时对比,C 数组果然是最快的:
思考题:这些题你都是怎么做的呢?
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号:tiankonguse
公众号ID:tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
