protobuf 启用 GZIP 压缩功能
作者: | 更新日期:
竟然没人使用过这个功能
本文首发于公众号:天空的代码世界,微信号:tiankonguse
一、背景
最近有朋友问我怎么缩小数据占用内存的大小。
我回答道:如果是为了缩小内存大小,可以尝试压缩一下?
接着我有补充道:这个算是使用时间换空间,压缩和解压缩需要时间的。
朋友又问:自己 protobuf 已经进行序列化了,这个和压缩是等价的吧?
我回答到:反序列化压缩的大小很有限。平常 protobuf 序列化缩小内存的说法是相对于 json 等文本协议来说的。
二、自带压缩功能
我给朋友建议,找一个压缩算法,比如 snappy 压缩算法。
然后先对 Protobuf 进行序列化,然后对序列化的二进制进一步压缩。
后来我便思考,二进制压缩效果如何呢?
一搜索,发现 protobuf 自带压缩功能,可选的压缩算法有 GZIP 和 ZLIB。
此时我便感兴趣了,所有 pb 协议的缓存系统都可以引入这个压缩功能来缩小内存。
三、网上的压缩样例
网上一搜索,所有的 protobuf 压缩样例都是文件当做出入输出的。
压缩序列化样例:
std::ofstream output("scene.art", std::ofstream::out | std::ofstream::trunc | std::ofstream::binary);
OstreamOutputStream outputFileStream(&output);
GzipOutputStream::Options options;
options.format = GzipOutputStream::GZIP;
options.compression_level = _COMPRESSION_LEVEL;
GzipOutputStream gzipOutputStream(&outputFileStream, &options);
scene->SerializeToZeroCopyStream(&gzipOutputStream)
可以看出来,大概分 5 步骤:
1、定义一个 写文件流
2、文件流 塞到 OstreamOutputStream 中。
3、定义压缩参数 Options。
4、定义压缩流 gzipOutputStream。
5、序列化
反序列化也类似。
std::ifstream input("scene.art", std::ifstream::in | std::ifstream::binary);
IstreamInputStream inputFileStream(&input);
GzipInputStream GzipInputStream(&inputFileStream);
scene1->ParseFromZeroCopyStream(&GzipInputStream)
解压缩只需要 4 个步骤。
1、定义一个读文件流。
2、文件流塞到 IstreamInputStream 中。
3、定义解压缩流 GzipInputStream
4、反序列化
使用文件可以跑通了,那能不能直接把数据压缩序列化到 string 呢?
网上搜索一圈,全部是介绍 文件的 样例。
而这个文件的操作样例也是 protobuf 官方提供的。
于是我便只能去读一下 protobuf 的压缩部分的源码,找找如何使用 string 来输入输出。
四、偶遇解决方案
由于正常的 protobuf 代码我已经看过了。
所以这里只需要看压缩解压缩的代码了。
先看 Gzip 流的文件代码,发现特别简单,就两个类。
一个压缩类 GzipInputStream,一个解压缩类 GzipOutputStream,都继承了 零拷贝 类 ZeroCopyStream。
再看看 Istream 流文件代码,发现也是几个简单的类。
比如输入流 IstreamInputStream 和 输出流 OstreamOutputStream,还有些其他的类,都继承了 ZeroCopyStream。
然后我就对这个 ZeroCopyStream类好奇了,一步小心打开错文件了,这不要紧,中大奖了。
我本来计划打开 zero_copy_stream.h 文件的,结果打开了 zero_copy_stream_impl_lite.h 文件。
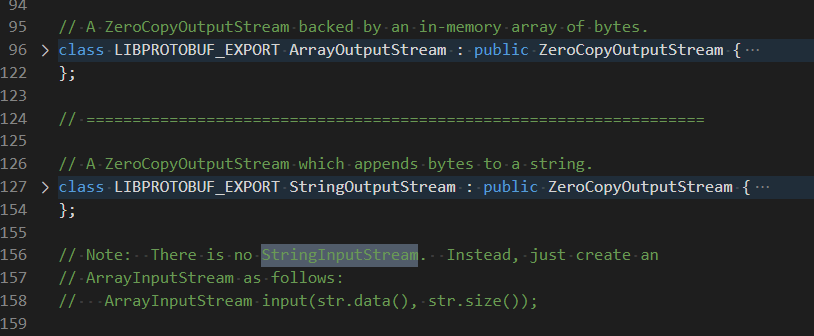
只因多瞅了一眼,竟然看到了 StringOutputStream 这个类。
顾名思义,iostream 是读写文件的,那 stringStream 就是用于操作 string 的了。
序列化需要 StringOutputStream ,那自然可以猜到反序列化就需要 StringinputStream 了。
但是发现这个类不存在。
一搜到,在注释里找到了解释,原来要使用 ArrayInputStream。
就这样,我使用 string 写出了压缩序列化与反序列化 protbuf 的代码。
五、完整版方案
完整版代码如下:
#include <google/protobuf/io/gzip_stream.h>
#include <google/protobuf/io/zero_copy_stream_impl.h>
std::string output;
// 压缩序列化
google::protobuf::io::GzipOutputStream::Options options;
options.format = google::protobuf::io::GzipOutputStream::GZIP;
options.compression_level = 9;
google::protobuf::io::StringOutputStream outputStream(&output);
google::protobuf::io::GzipOutputStream gzipStream(&outputStream, options);
person.SerializeToZeroCopyStream(&gzipStream)
gzipStream.Flush(); //数据刷到储存中
printf("COMPRESSION output size : %d\n", static_cast<int>(output.length()));
// 解压缩反序列化
person.Clear();
google::protobuf::io::ArrayInputStream inputStream(output.data(), output.size());
google::protobuf::io::GzipInputStream gzipStream(&inputStream);
person.ParseFromZeroCopyStream(&gzipStream)
这里有一个坑就是,压缩序列化的时候,必须进行 Close 或者 Flush 操作。
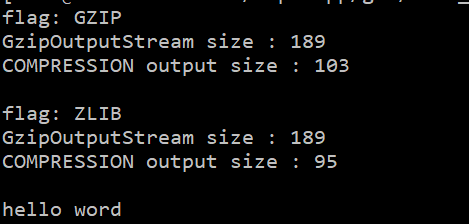
压缩效果可看出来,我随便构造了一个数据,ZLIB 压缩算法比 GZIP 压缩算法稍微好一些。
六、最后
网上查看了不少文档,发现还是看源代码比较靠谱。
由于 protobuf 官方的样例是通过文件流的方式压缩序列化的,以至于整个互联网上所有的资料都是文件流压缩的教程。
甚至有些服务为了能够使用这个压缩功能,还专门先压缩到文件,然后读文件到内存。
由此也说明,官方对外提供文档的时候,一定要提供全。
不然就会像这个压缩功能,明明有直接压缩输出到内存的方法,所有人都使用文件这么蹩脚的方式来用这个功能。
思考题:你怎么看待这个现象呢?
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号:tiankonguse
公众号ID:tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
