发生故障,你的服务能承受住考验吗?
作者: | 更新日期:
故障,是一个验金石。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
一、背景
今天同一时间发生了两起故障,先记录下第一起已经解决的故障,晚几天再记录另外一起。
解决故障的过程中,我领悟到一个道理:平时不管服务宣称的多好,都不好证明。出问题时,才是承受考验的时刻。
二、服务架构
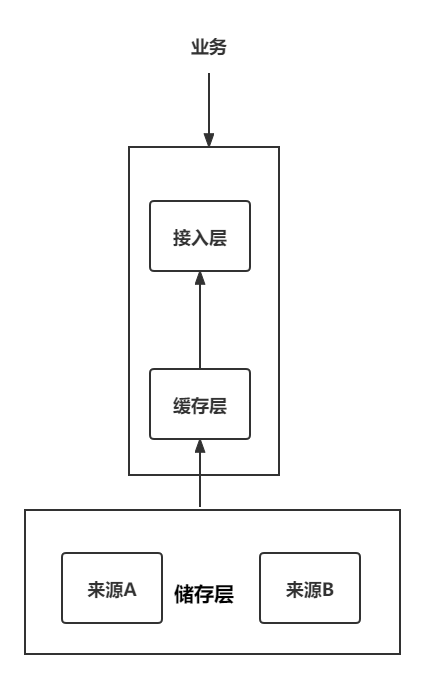
我们的服务架构其实很简单,一个接入层(我负责)、一个缓存层(项目核心人员负责)、底层很多数据源。
服务其中一个很重要的作用是,对读数据的业务屏蔽数据源细节。
例如对于视频表,可能是下面的样子。
视频基础资料数据,A 团队负责,储存在 a DB中,字段名是 A 团队自定义的。
视频播放量数据,B 团队负责,储存在 b DB 中,字段名是 B 团队自定义的。
视频付费数据,C 团队负责,储存在 c DB 中,字段名是 C 团队自定义的。
我们的这个服务统一来读取这些数据,然后输出给使用方。
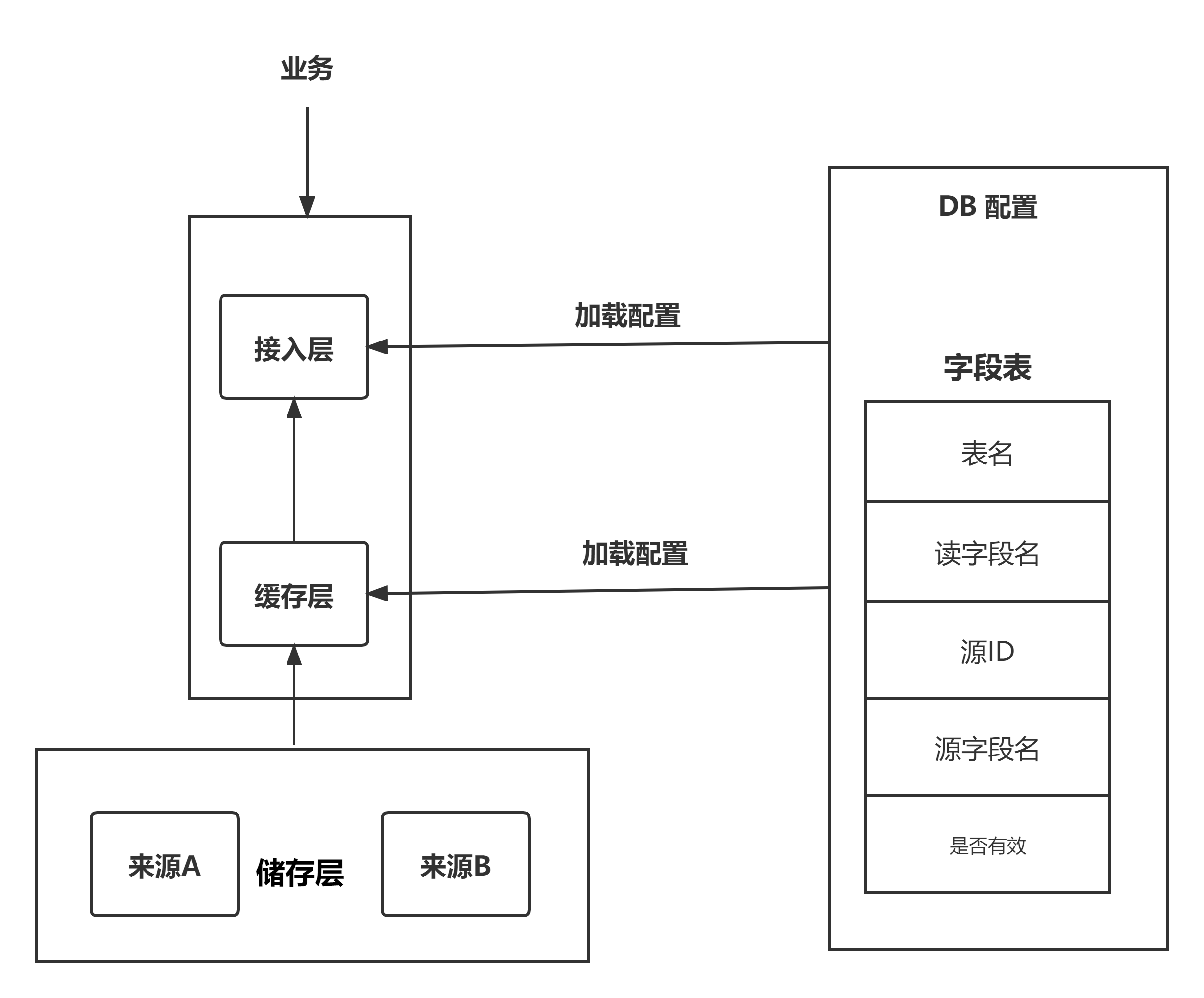
设计这个系统的时候,发现会遇到储存字段名变化的情况。
变化的原因有很多,如下
1、不同团队 DB 中的字段名会冲突。
2、储存中的字段名起的不规范。
3、储存中的字段名可能换名字。
4、一个储存的字段可能突然废弃,切换到另外一个储存。
上面是常见的原因,可能还有其他原因。
总之,我们不能因为储存的名字发生变化,就影响业务读业务方。
所以,我们的服务其中一个很大的特点是分为读字段名和储存源字段名(写字段名)。
使用数据方只关心读字段名,不需要关心数据在哪里储存,名字是什么。
就是在这样一个背景下,今天出现了一个故障。
三、服务 coredump
16:20 的时候,我收到多条告警,是接入层读缓存层存在失败率。
于是赶紧通知缓存层的核心开发人员,问是否有发布,线上存在失败率。
几分钟后,缓存层回复:没发布,发现服务存在 coredump ,在读 redis 的地方挂了。
我马上说电话 redis 的开发同学看下,是否是 redis 有变更导致。
几分钟后,回复:redis 那边没有变更。
16:27 拉了一个群,贴出了core 截图,我便看有什么特征。
看到图中没有堆栈时,我赶紧说:把堆栈发出来,甚至看能不能把redis请求与回包打印出来。
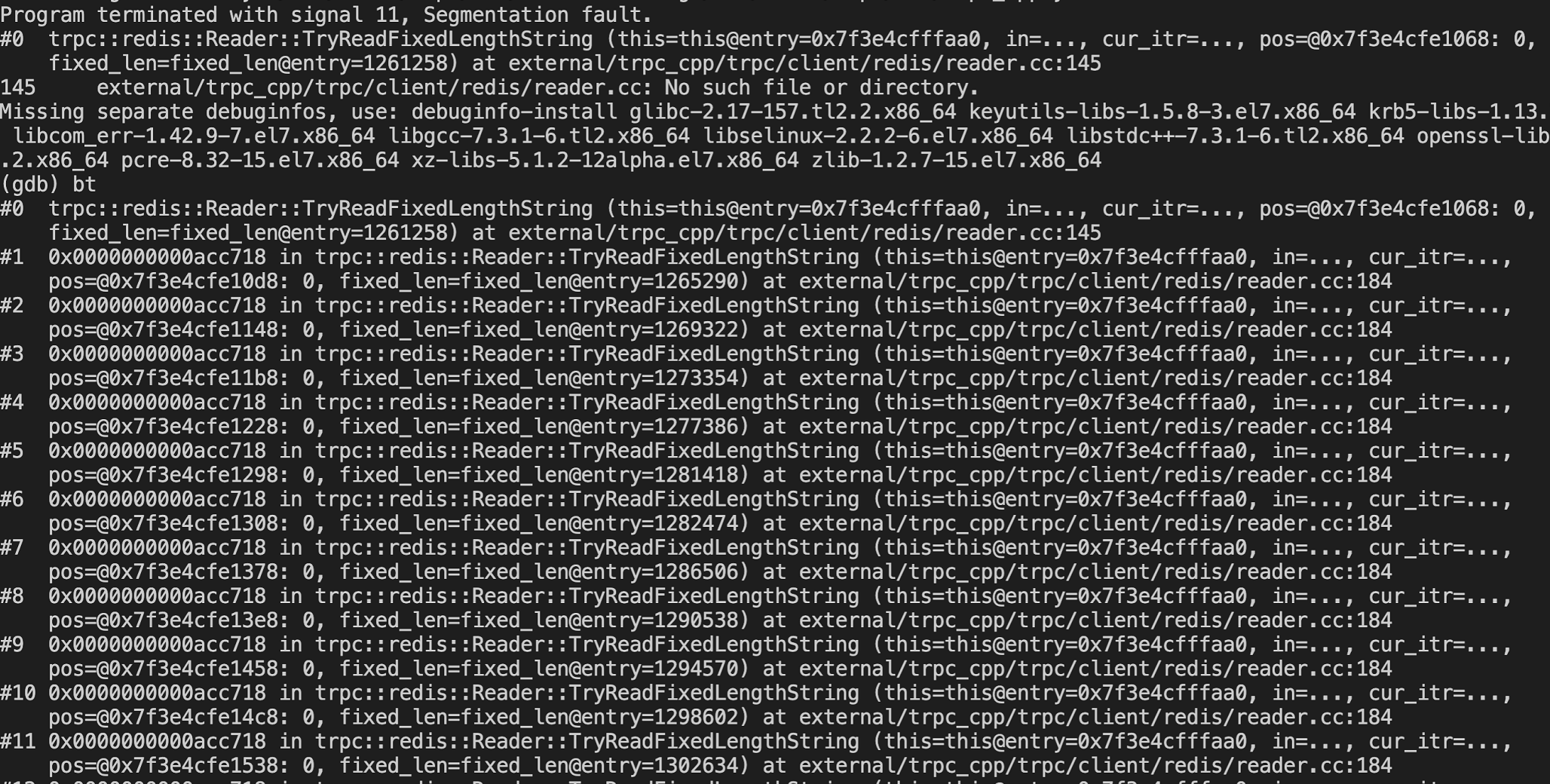
缓存层核心负责人发出堆栈截图后,补充道:好像死循环了,堆栈的函数都是同一个。
而我则观察到,函数最后一个参数是包的长度,很大,足足有 1M。
于是大家都猜测可能时大包的问题。
四、紧急处理
缓存层核心负责人把所有堆栈打印出来后,找到了一个异常字段。
我问写负责人,这个数据时今天上线吗?
得到的回复时上线好几周了。
于是,我们做出了一个合理的猜测:只有这一个字段有大包问题,然后触发了RPC框架的BUG(事后,我甚至猜测只有一条数据有问题)。
接着做出了一个合理的措施:下掉这个字段。
还是看架构图,下掉这个字段有两个方法。
一个是修改读字段名,这样业务请求的时候就报错,会触发失败率告警。
另外一个是修改写字段名,这样不会报错,储存中会读出空数据,之后流程完全无感知。
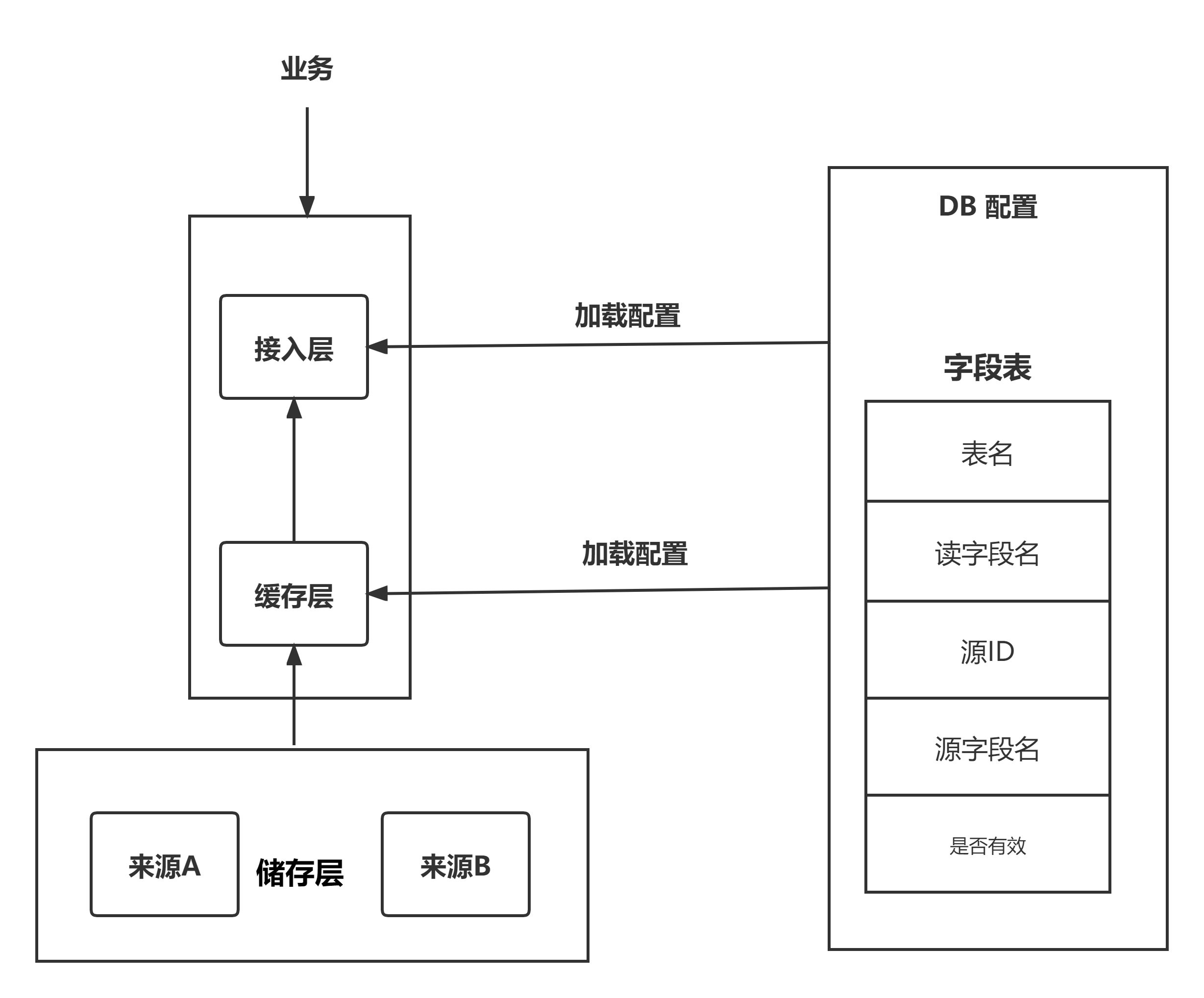
为了不触发告警造成骚然,我提出方案一:赶紧修改储存源字段名。
在这个服务重构前,底层储存出问题时,我经常这样搞,解决了无数问题了。
修改完写字段名后,等了几分钟,从接入层看监控依旧有失败,缓存层核心开发人员也反馈依旧在 core。
缓存层不是我实现的,所以我不清楚原因,也没时间去看源码。
缓存层核心人员说可能生效需要时间吧,于是等了很久,迟迟没有彻底恢复(事后看监控,可能真的生效慢)。
于是,我提出方案二:修改读字段。
修改后,刷新监控,失败率已经下降,恢复正常。
之后也符合预期的收到一个失败率告警。
原因是有些业务只读这个表的一个字段,现在字段不存在了,命中了字段全部非法的错误码逻辑。
五、流量调度
故障恢复平静后,领导说:接入层之前不是实现了流量调度能力吗?
可以把这个异常表的请求都路由到一个只有一个业务的小众集群去,这样即使再出问题,也不会影响到大众业务。
说起流量调度,还是需要看架构图。
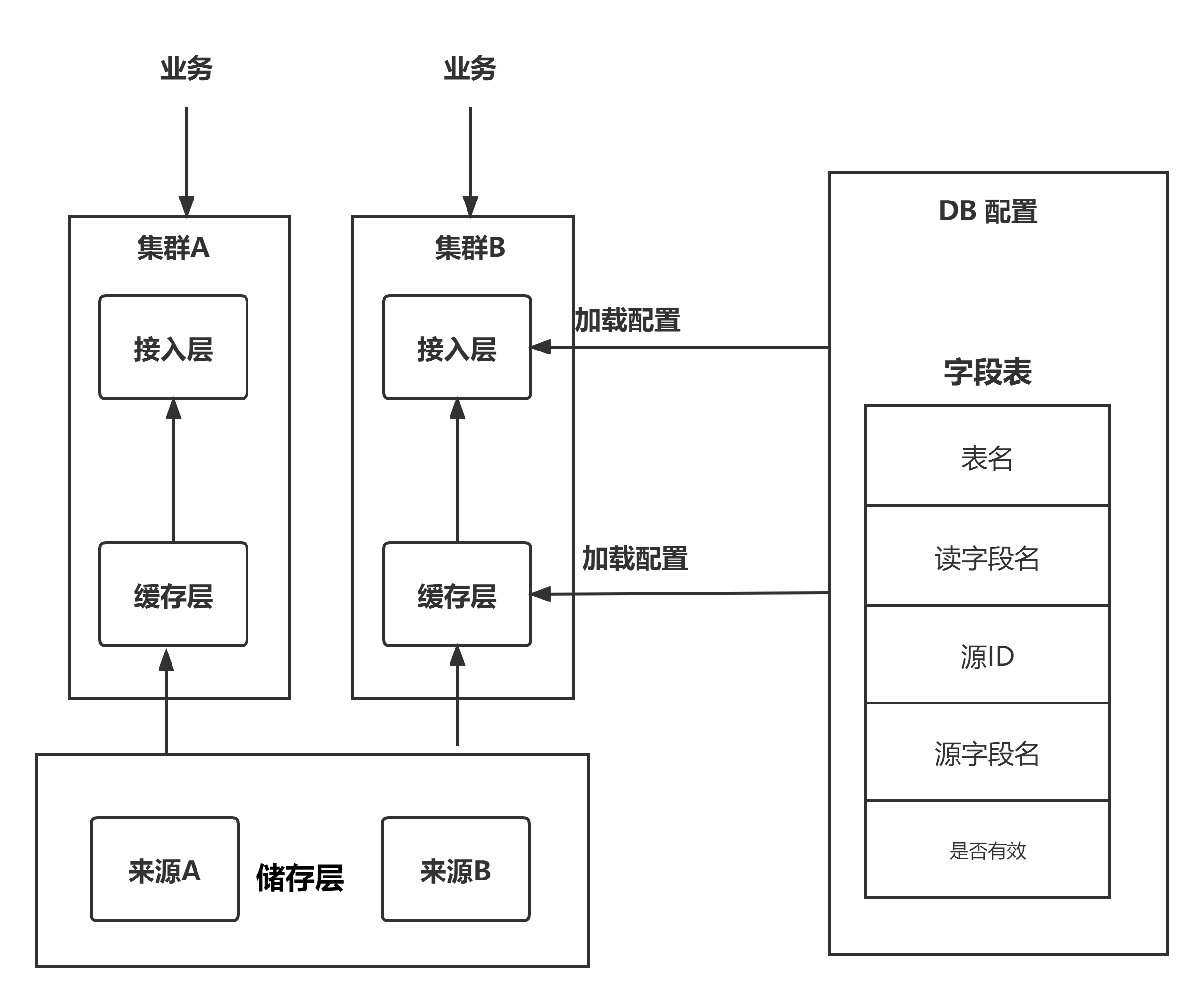
实际上,我们部署了多套物理隔离的集群(来源除外),给不同业务提供服务。
面对 A 集群流量暴涨,B 集群还有充足容量时,如果能够把 A 的部分流量调度到 B 时,就可以让 A 集群的服务质量。
所以我们做了一个流量调度能力。
当然,最理想的流量调度是在客户端实现,但是依赖的路由发现中台还在开发中。
我们便在接入层实现了这样一个基于业务标识的转发功能。
面对领导的这个要求,我说没问题。
说干就干,操作之后,看监控,流量都符合预期的到达那个小众集群去了。
刚开始因为小众集群没缓存,还收到一波告警。
不过超时率也在快速的衰减,这个超时也算符合预期。
六、最后
当然,我们发现字段有大包问题时,也在让写服务的核心开发去联系具体问题的数据表的业务负责人,咨询是否可以直接从储存中删除大包数据。
另外,我们把这个问题反馈给 RPC 框架时,框架的开发人员说最近正好解决了一个类似的问题,建议我们升级到最新版本。
最后,当缓存层核心开发升级到最新版本后,我又取消屏蔽这个字段了。
初步验证没有再 coredump ,问题算是解决了。
吃饭的时候,我便想:异常情况才能真正检验平常做的功能是否有效。
比如我们紧急去解决问题,平常预备了方案一二三。
可能自测宣称是有效的。
可能演习宣称时有效的。
但是否真的有效不好说,当线上来了真实的问题时,才是考验这些功能是否有效的时候。
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号:tiankonguse
公众号ID:tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
