队列卡住?方向错了,使出十八般武艺也没用
作者: | 更新日期:
不要忘记最初的目标,否则gcore、gstack、GDB、反汇编、寄存器都没用。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
一、背景
上篇文章《发生故障,服务能承受住考验吗?》提到,下午的时候收到两个服务失败率告警。
处理完那个故障后,我多看了一眼监控,发现另外一个失败率还没恢复。
于是,继续找缓存层核心开发,问服务是否还有其他问题。
二、谁的问题
还是先熟悉架构图,如下,分为接入层(我负责)与缓存层(核心开发人员负责)。
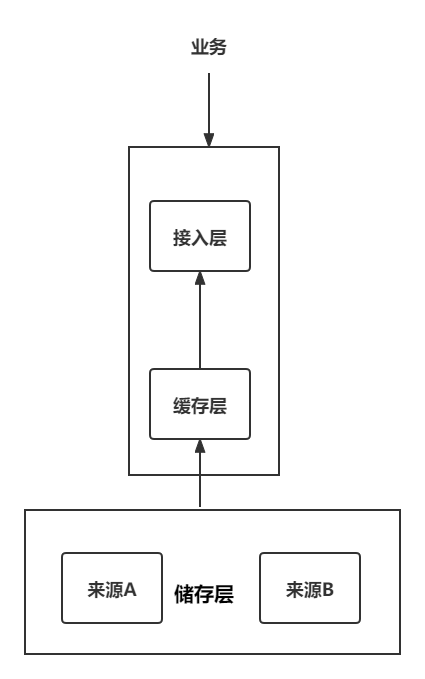
接入层调用缓存层时,接入层有一个主调监控,缓存层有一个被调监控。
主调监控上看,缓存层有一个数据分片存在一个失败率。
从被调监控上看,缓存层自己没有失败率。
只看这个数据,没办法证明是主调接入层的问题还是被调缓存层的问题。
正常情况下,主调监控还会上报主调 IP 与被调 IP:PORT 。
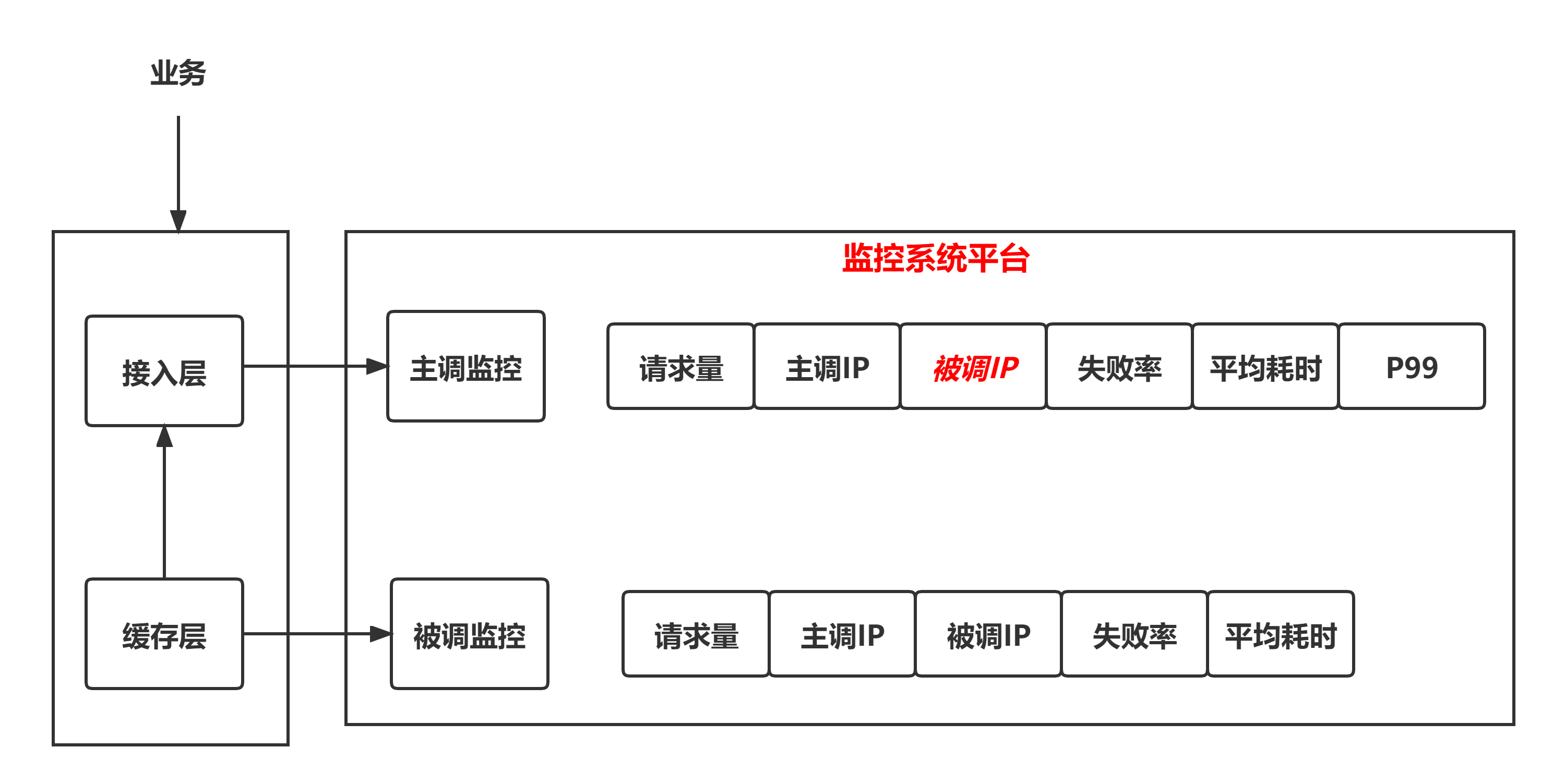
由于我们的系统访问量比较大,监控系统平台自动把主调监控的被调 IP:PORT 屏蔽掉了。
我看接入层主调监控的主调 IP,可以看到各台容器的失败率比较平均,因此可以排除接入层的单机问题。
所以,我怀疑是被调服务,也就是缓存层存在单机问题,比如某台机器在 coredump。
我这里不能证明是谁的问题,缓存层核心开发说声称看监控自己的服务没问题。
于是我联系监控系统平台,要求打开主调监控的被调IP,不然没法定位问题。
打开半个小时后,从监控上看到了被调IP,也收到了接入层主调监控的单机失败率告警。
果然,缓存层的三台机器异常。
我赶紧让缓存层核心开发把那三个容器从路由发现平台摘除掉,然后再去分析问题。
缓存层核心开发问我怎么摘除,那么多机器找不掉这三台机器。
我说我摘除吧,路由发现平台支持基于IP来搜索的。
于是我随手就把异常的机器都摘除了。
三、寻找原因
现在已经明确,缓存层服务有三个容器存在失败率。
我让缓存层核心开发定位一下。
一段时间之后,缓存层核心开发说看异常机器的被调监控、CPU、负载、内存等都正常,没发现问题。
于是我介入一起看问题。
我自言自语分析到:可以看看单机主调监控,极有可能是某个数据缓存命中率降低,但这样不应该是单机问题。
当然,也可能是系统问题,看属性监控应该可以看出来。
我随手去属性监控一看,发现了问题真相:异常容器有一个队列卡住了。
然后一算失败率,14 个队列,卡住一个,失败率 7%。
与收到的失败率告警完全一致。
自此,缓存层单机失败的原因找到了,是队列卡住了。
所以,接下来是分析为啥队列会卡住。
四、十八般武艺
由于异常机器已经从路由发现平台屏蔽,所以先去吃了晚饭。
饭后,我拉上了 RPC 框架的人,问队列这块的架构是怎么样的。
我的想法是先简单了解架构设计,然后再进行分析。
可能是吃饭时间,RPC框架的同学没有回复消息,我便先自己尝试定位问题。
武艺1:从属性监控上可以看到,是 HandleModel 队列 4 卡住了。
我猜测 RPC 框架是有多线程实现多队列的,所以应该是 HandleModel 4 线程卡住了。
具体原因需要了解架构才行。
但是 RPC 框架的人不在,只能自己随便折腾下尝试一下。
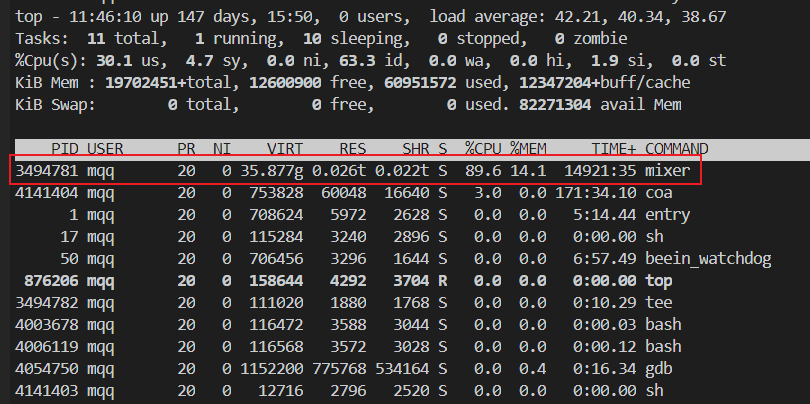
武艺2:查看服务进程 PID - top。
由于是单进程, top 命令即可看到进程 PID。
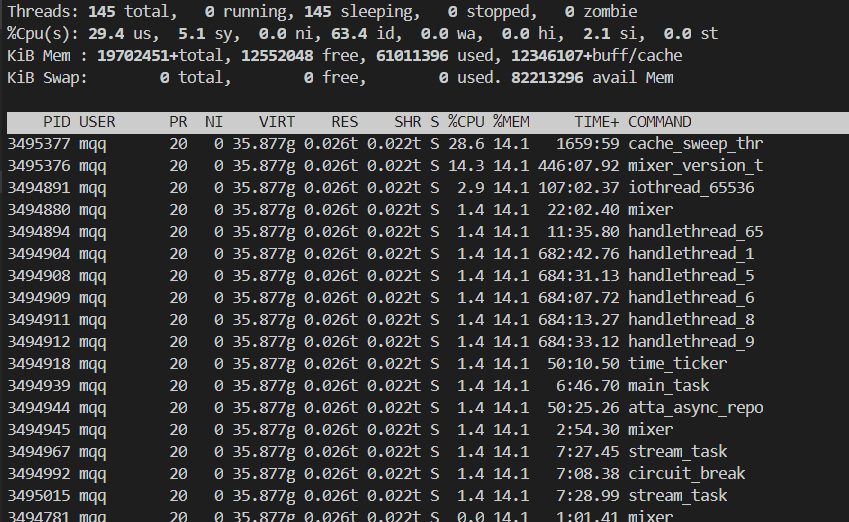
武艺3:查看卡住的线程 ID - top -H。
由于 RPC 框架对各种管理的线程进程了命名,所以根据线程名就可以找到对应的线程 ID。
命令:top -H -p $PID
解释:-H 是显示线程, -p $PID 是只显示指定进程的信息。
合起来就是只显示进程 $PID 的线程信息。
武艺4:top 信息非交互式输出。
这个服务的线程有几百个,top 一屏幕显示不下,所以看不到对应的线程 ID。
非交互式输出的好处是可以使用管道来进一步使用其他命令对输出处理,或者重定向到文件里。
命令:top -H -b -n 1 -p $PID
解释:-b 是按 Batch-mode 模式运行,含义是批处理模式,即非交互模式,可以使用管道的模式。
-n 1 含义是 top 只允许一次,默认是无限运行,可以用来多次采集进程或线程信息。
这样,我们就可以在文件里搜索到对应的线程 ID 了。
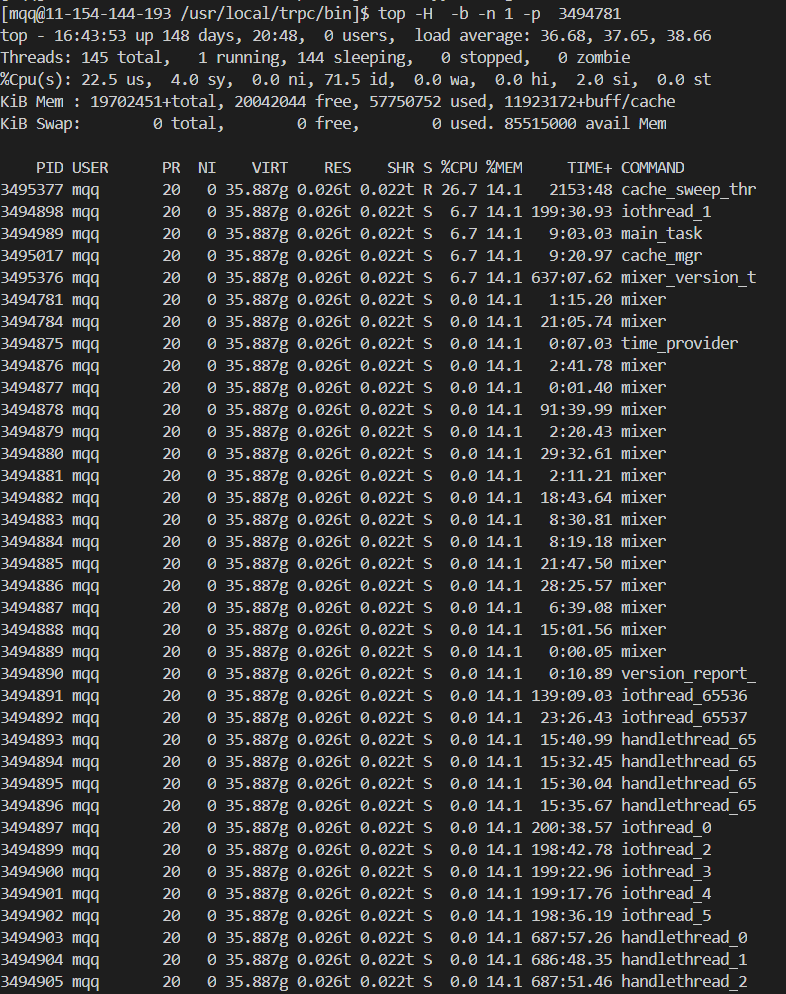
武艺5: gcore 保存进程 core 镜像文件。
问题是突然发生的,不知道怎么复现的。
现在遇到了,如果把进程搞挂了,问题现场就不存在了。
所以,一般情况下,需要保留一份现场环境,用于后面持续分析与定位。
命令:gcore $PID
如果看 gcore 的源码,会发现是一个 bash 脚本,备用调用的是 GDB 命令。
武艺6: GDB 打开 core 文件
命令:gdb ./exe_name core.$PID
武艺7:gdb 查看线程信息
命令:info threads
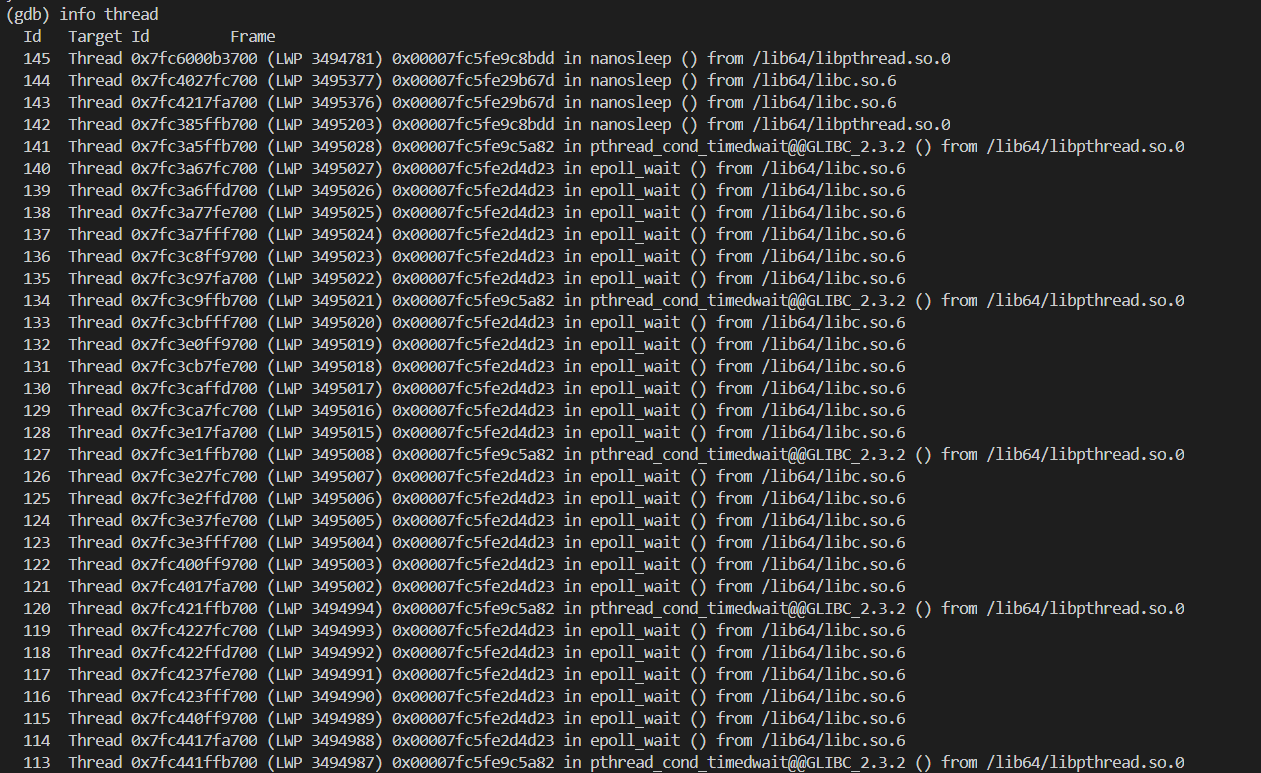
可以发现,对于每个线程 ID,GDB 中需要另外一个序号 id。
武艺8: gstack 查看全部线程信息
固然可以把几百个线程ID都输出来,然后复制到文本中搜索,但是不优雅。
所以,我想起 gstack 这个命令,可以打印所有线程的堆栈,包括线程 ID 和 那个序号。
PS:由于 gstack 运行的较慢,我最终还是从之前的 GDB 里把所有线程信息复制出来了。
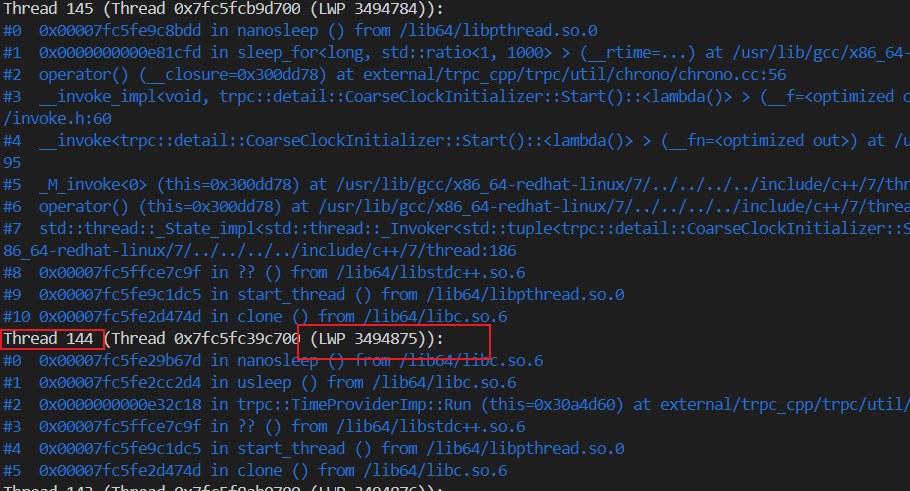
当然,如果你查看下 gstack 的源码,会发现也是通过 gdb 实现的,而且比 gcore 实现的优雅一些。
所以,另外一种方法是在 GDB 里执行命令,然后把线程信息输出到文件里。
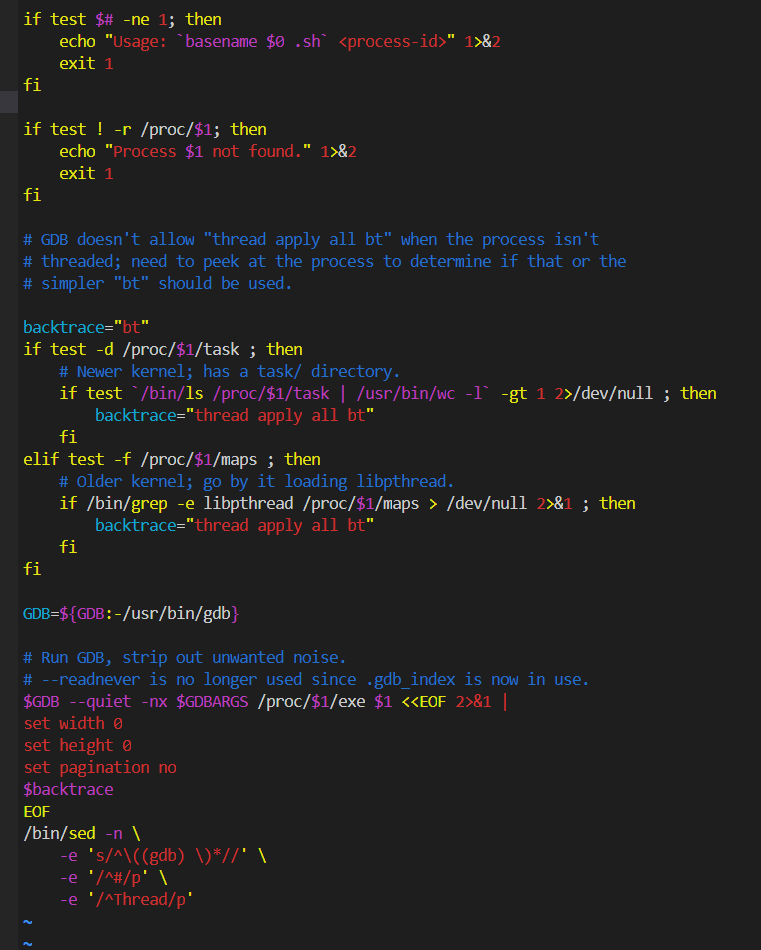
武艺9:gdb 切换到对应的线程上下文
命令:thread 线程对应的序号ID

武艺10:gdb 查看堆栈
命令:bt
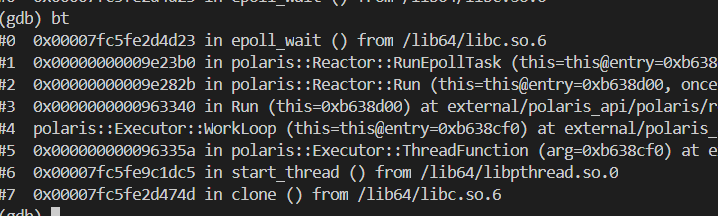
武艺11:查看 RunEpollTask 的源码
可以发现,RPC 框架函数 RunEpollTask 调用了系统函数 epoll_wait ,之后就卡住了。
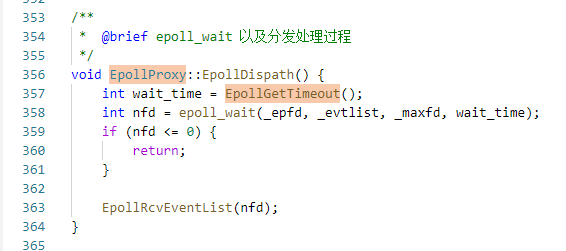
武艺12:查看 EpollGetTimeout 的源码
可以发现,代码里判断了大小,防止减法减出负数来。
但是由于没有把 thread->GetWakeupTime() 的值保存下来,并发执行的情况下,可能前一时刻不小于,后一时刻就小于了。
所以这个函数可能是正常的算出很大的值,也可能是相减算出负数,然后变成无穷大值。
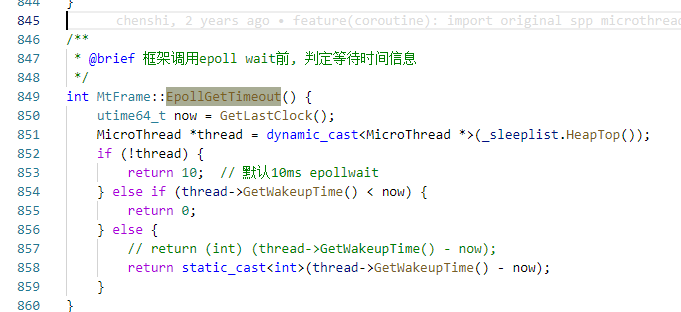
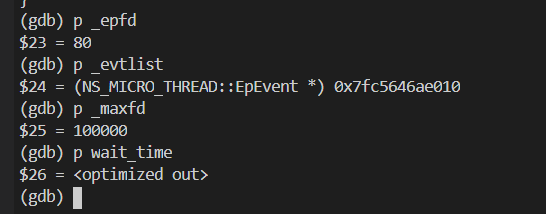
武艺13:打印参数
RunEpollTask 调用 epoll_wait 时传了四个参数,很不幸,第四个最重要的时间参数被优化掉了,打印不出来。
武艺14:反汇编,查看传参
看到一堆汇编指令,发现与大学以及网上查到的汇编指令不同,但是又长得差不多。
武艺15:复习汇编
大学汇编课程与网上的汇编资料都是 Intel X86 汇编。
多年前,我也在《汇编快速认识》整理过一些简单的汇编知识。
而 Linux 下的汇编是 GUN GAS 汇编。
两个语法又不少差异。
差异1:第一操作数时目的操作数,第二个操作数时源操作数(刚好相反)。
差异2:间接寻址,通用寄存器加括号即可获取间接操作数。
差异3:寻址万能公式。
segment:displacement(base register, index register, scale factor)
等价于
segment:[base register + displacement + index register * scale factor]
真实地址:segment × 16 + 偏移地址
至于寄存器 SP、IP 等与命令 MOV、PUSH、POP、CALL、RET、以及一堆 test 指令,差异不是很大,这里就不展开介绍了。
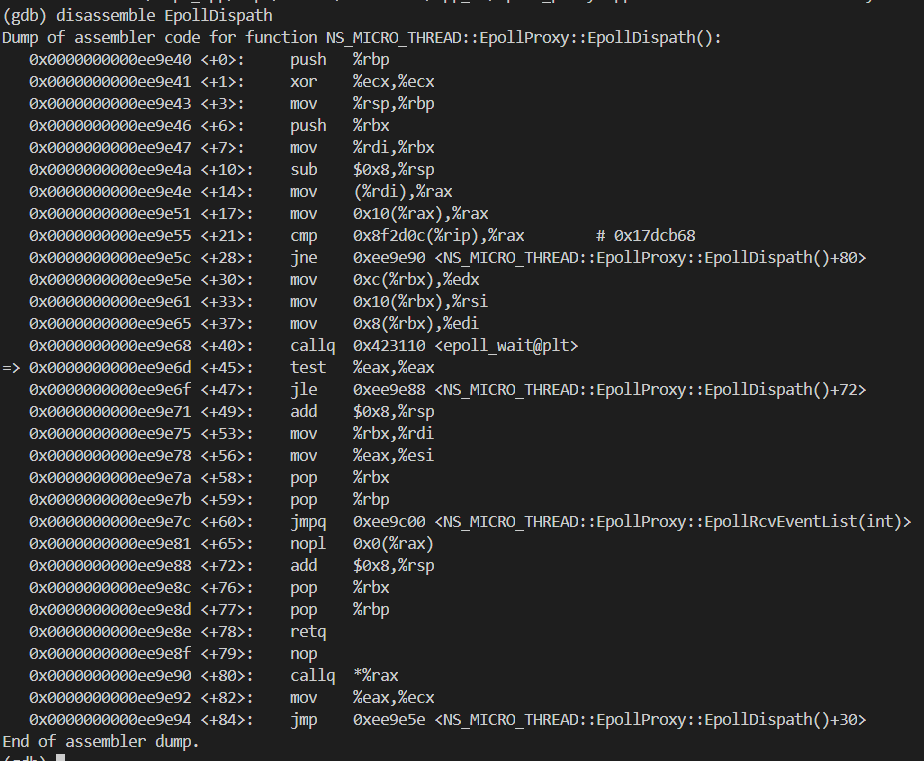
武艺16:函数调用汇编如何传参
我们知道,函数调用时,有两种方法传参。
一种是全部使用寄存器,另一种是压入栈里面。
0x0000000000ee9e5e <+30>: mov 0xc(%rbx),%edx
0x0000000000ee9e61 <+33>: mov 0x10(%rbx),%rsi
0x0000000000ee9e65 <+37>: mov 0x8(%rbx),%edi
看上面反汇编的截图,可以发现是通过寄存器传参的。
只不过 epoll_wait 有四个参数,这里只能看到给三个寄存器赋值。
这是因为编译器进行了优化,最后一个参数 wait_time 是调用函数的返回值,那在调用函数返回的时候就可以赋值了。
查下寄存器会参数位置的文档,可以发现参数从前到后的寄存器依次是edi、rsi、edx、ecx。
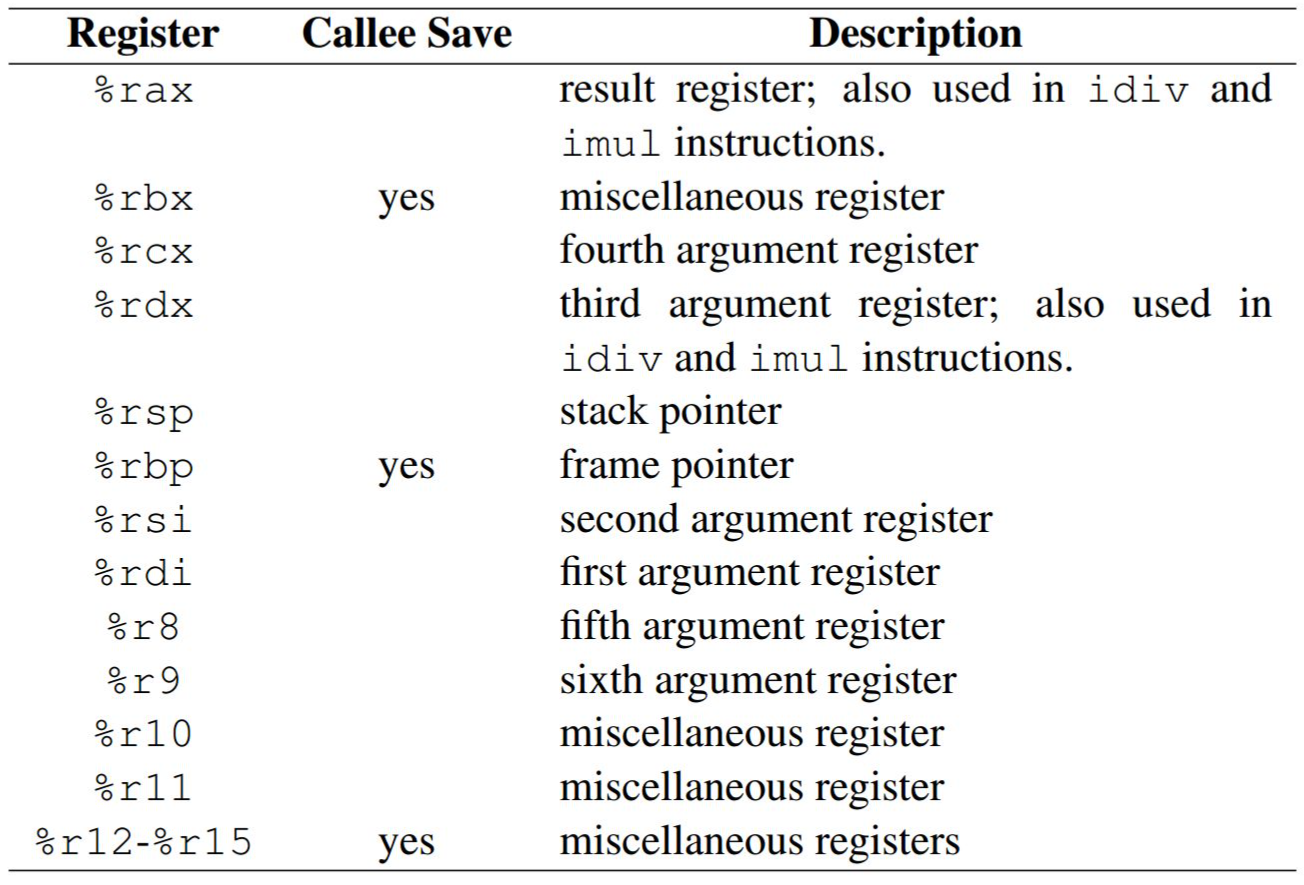
对应到反汇编上,就是下面四条指令。
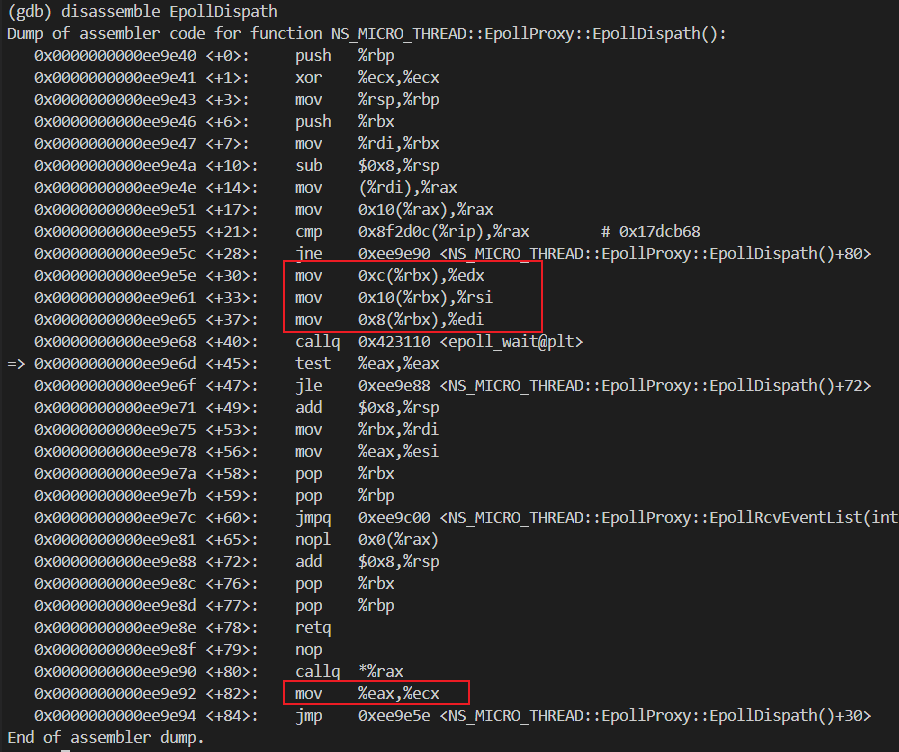
武艺17:打印寄存器的值
既然反汇编发现参数存入到寄存器中了,那自然需要打印出寄存器的值,核对一下。
寄存器的值打印出来后,可以发现前三个寄存器的值没问题,与 p 出来的一致。
但是最后一个关键参数的值,是个无穷大值。
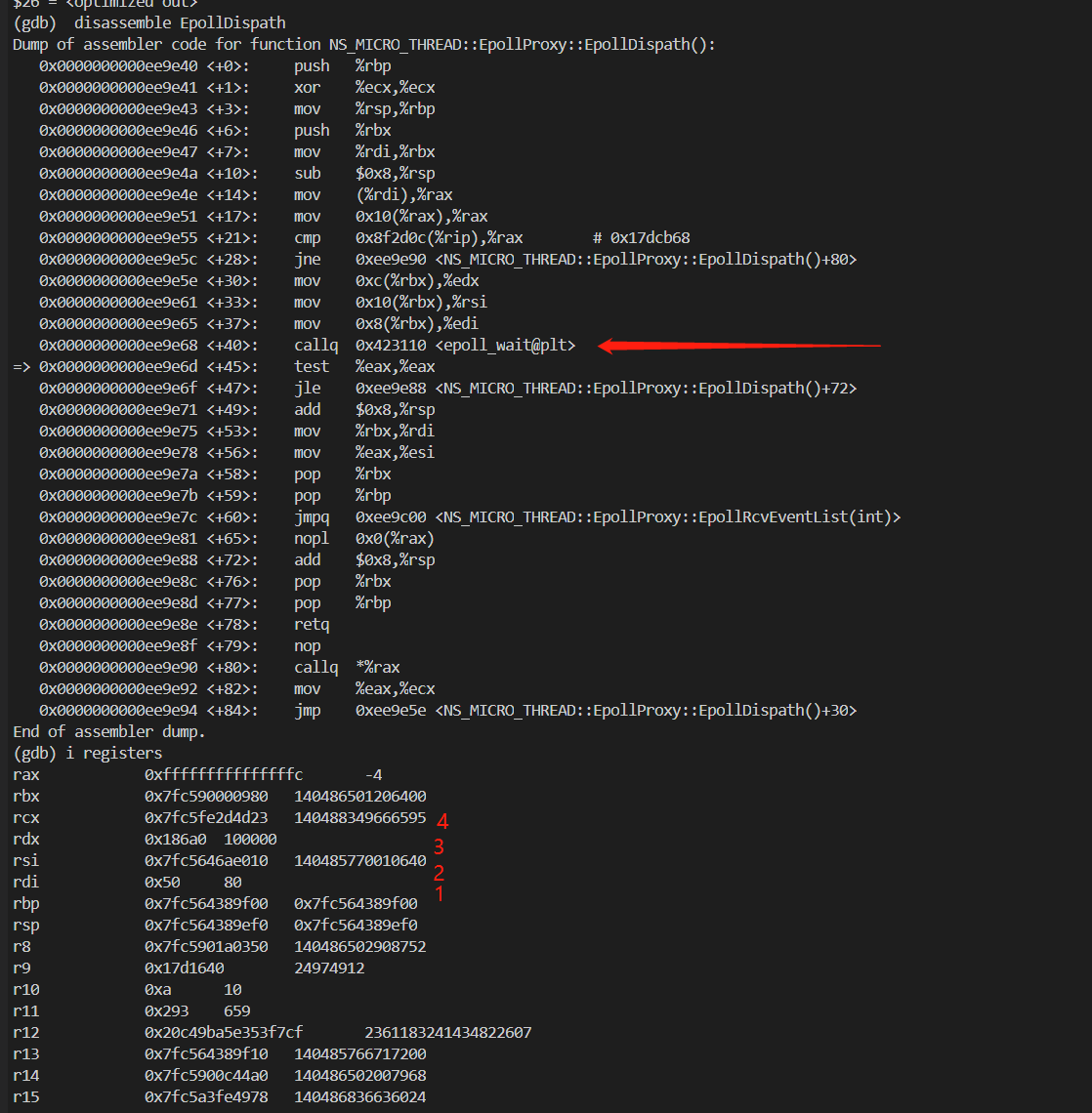
到这里,有两种可能:要么是传参就是这个无穷大值,要么是 epoll_wait 函数使用到了这个寄存器,修改了值。
所以还需要反汇编查看 epoll_wait 的代码。
武艺18:查看epoll_wait源码与反汇编
看到epoll_wait反汇编与源码,我们可以发现寄存器 ecx 的值赋值到了寄存器 r10,值是 10 没问题。
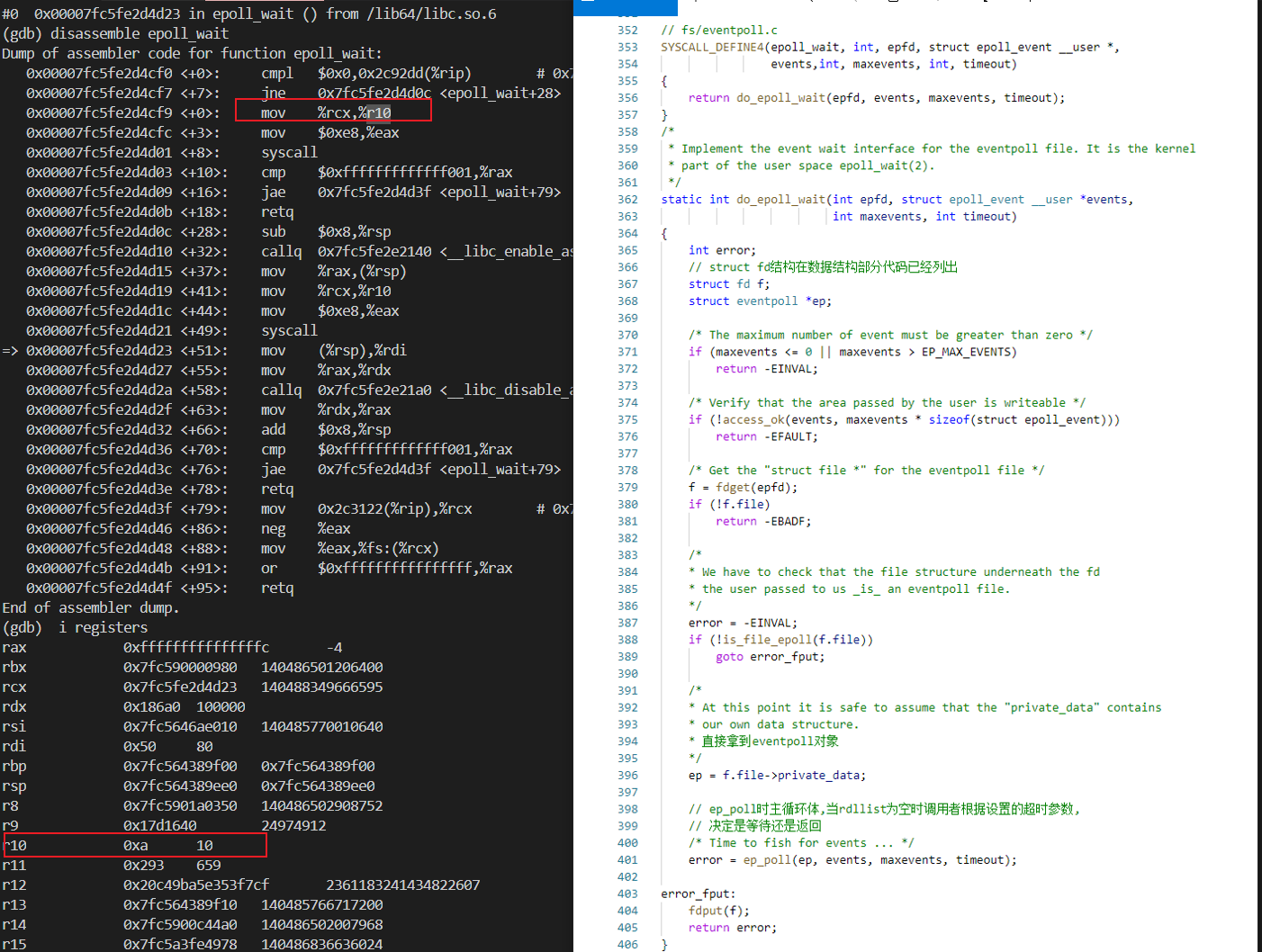
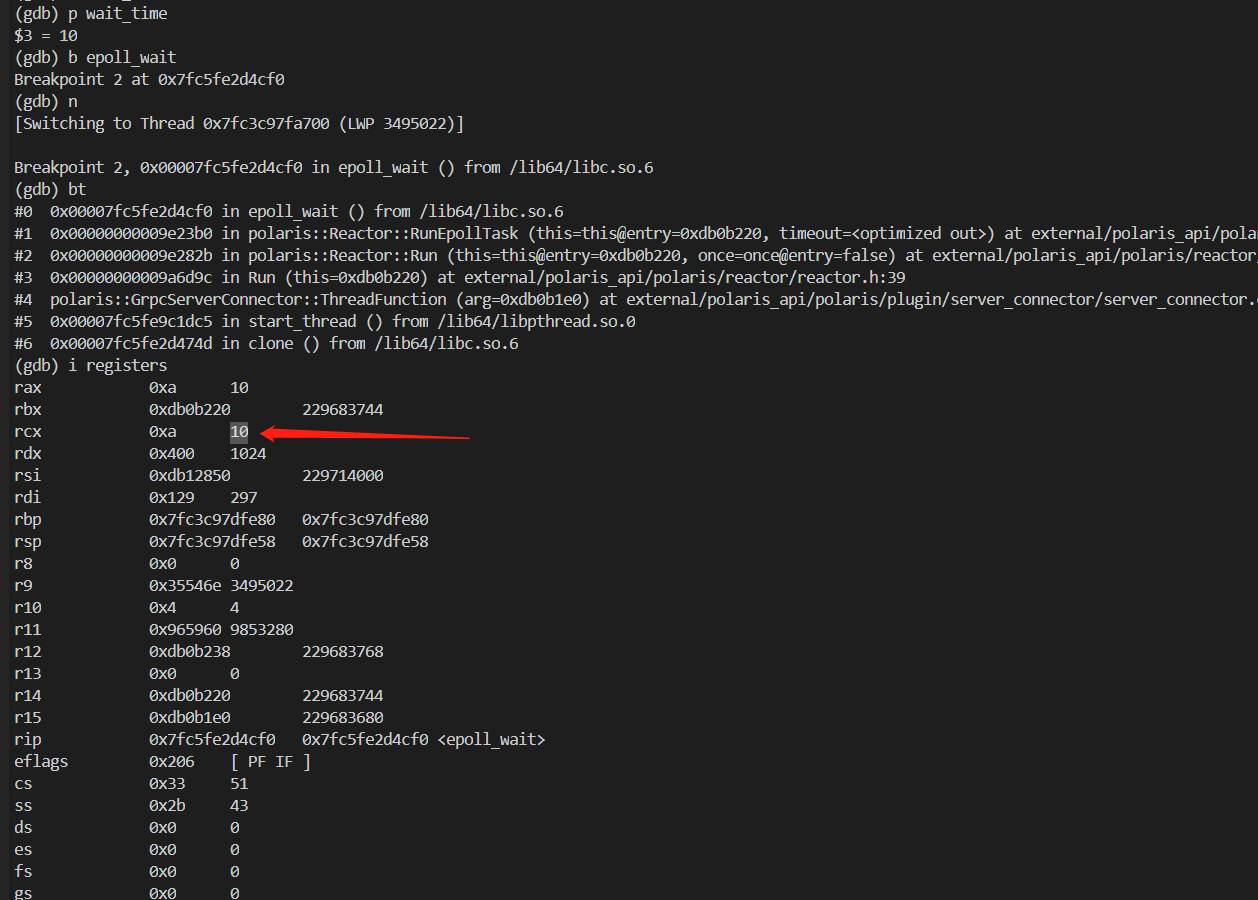
武艺EX:正常流量打断点
既然认为这里的寄存器没问题,那使用正常流量确认下寄存器的值。
b external/trpc_cpp/trpc/common/coroutine/spp_mt/epoll_proxy.cpp:359
r
b epoll_wait
i registers
p wait_time
通过执行上面的命令,发现正常情况下,wait_time的值果然是 10,此时 wait_time的值也可以打印出来。
五、最后
此刻我突然意识到我最初的目标是找 RPC 框架的同学,了解队列的设计架构。
现在方向突然偏航了,转向去研究为啥卡在 epoll_wait了。
但是堆栈在 epoll_wait 并不代表就是在这里卡住了。
后面还是找时间看一下 RPC 框架的源码,先了解下 RPC 框架是怎么设计这个队列的话。
方向错了,即使使出十八般武艺,也是无效的。
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号:tiankonguse
公众号ID:tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
