多核时代用好 NUMA 性能提升 20%
作者: | 更新日期:
时代在发展,我们需要去了解最新的特性。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
一、背景
最近我一直都在做性能优化。
之前在《源码阅读 gflags,发现设计缺陷》提到,相关同事让我调整 NUMA 参数再看下性能。
关闭与打开性能一对比,发现性能差异至少 20%。
那么问题就来了:NUMA 是什么,为什么会有这个性能差异?
二、CPU 与内存的关系
要介绍 NUMA,就需要一些电脑的硬件知识了。
最早的时候,电脑只有一个 CPU,通过总线连接内存。
后来到达多核时代后,多个 CPU 会通过总线先连接北桥,然后通过北桥再连接内存。
这种架构称为对称多处理器系统(Symmetric Multi-Processor),简称为 SMP 。
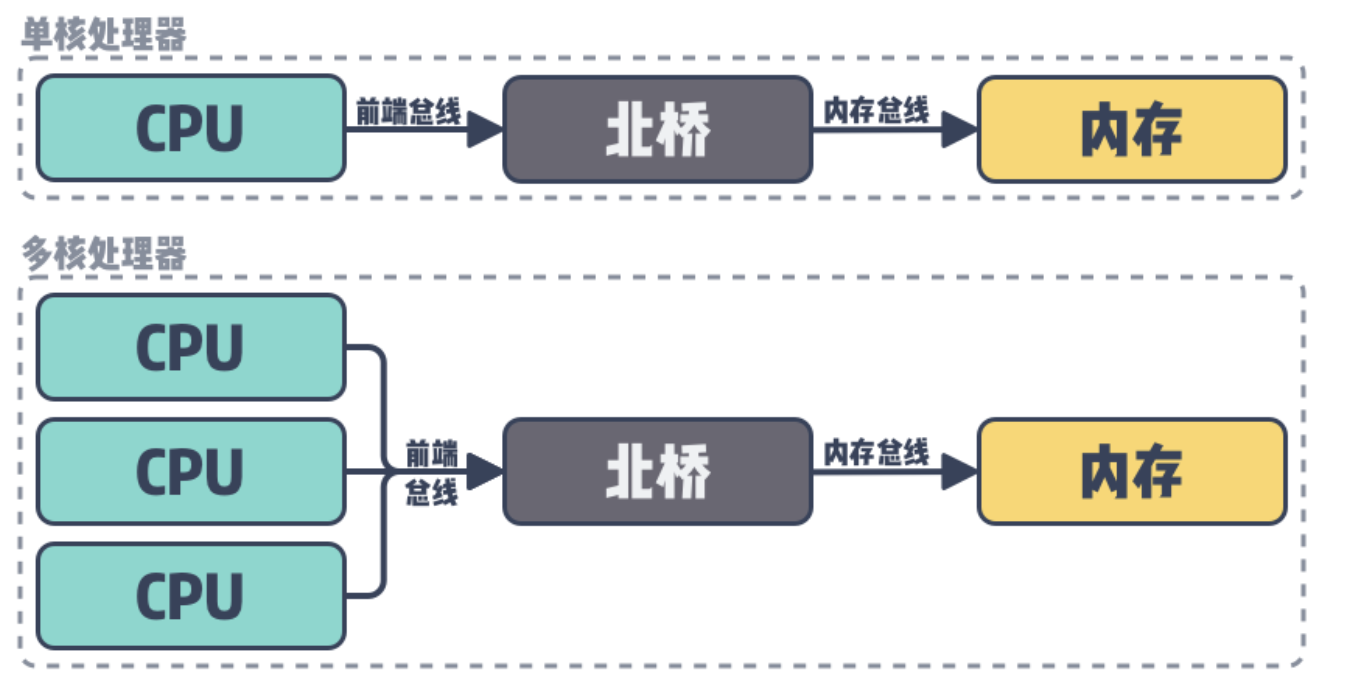
所有核读写内存,都需要经过北桥。
核数越多越多后,会发现北桥这里就是瓶颈点了。
所以后来人们就发明了一个新的架构,称为非一致性内存访问(Non-Uniform Memory Access),简称就是 NUMA。
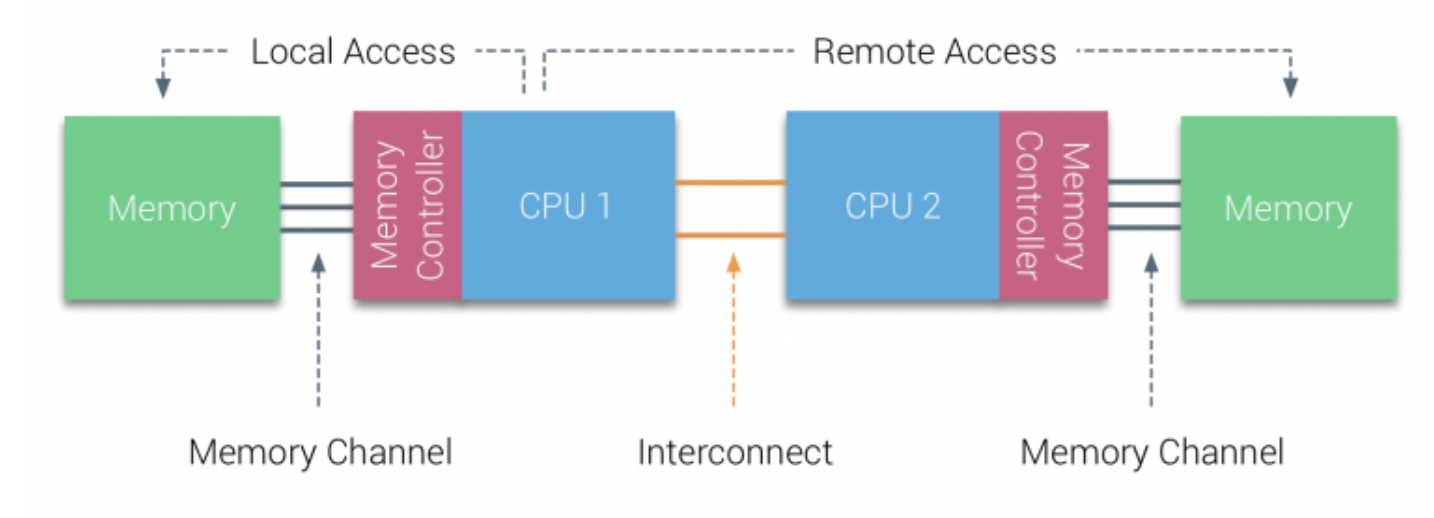
如上图,有两个 CPU,每个 CPU 连自己附近的内存,访问速度非常快。 同时,CPU 也可以访问其他 CPU 附近的内存,不过速度慢点。
正是由于 NUMA 这种不同 CPU 访问不同距离的内存,速度不一致的特性,引出了 NUMA 使用的方式不同,性能也会差异很大。
三、深入了解 CPU
上面举的例子是一个 CPU 直连一个 内存,现实的关系并不是一比一的。
一般是多个 CPU 一组 直连一块内存。
这样的一组,我们称为 CPU Node。
一组 CPU 上的每个 CPU 称为一个 Core。
由于 CPU 太快,为了防止内存操作时造成 CPU 因等待而浪费时间,
现在的 CPU 都支持超线性,即 Hyper-Threading。
Core 开启超线程后,在操作系统看来就是两个 Core ,所以超线程的核称为逻辑核。
而之前的 Core 则称为物理核。
这样,我们就了解了 CPU Node 与 核的关系。
四、如何提高性能
上面只是介绍了 CPU 与内存的知识,那具体是怎么影响到业务进程的性能呢?
默认情况下,进程会随机的调度到一个 CPU 逻辑核。
当进程需要在堆上分配新内存时,就会在 CPU 附近的内存上映射物理内存,这样在这个调度周期内时,性能非常高。
后来,这个进程调度到其他 CPU 上时,之前的数据依旧在之前 CPU 附近的内存上。
对于当前 CPU 来说,内存就比较远了,所以使用性能就会变低。
那我们该如何防止这种 CPU 调度导致的性能问题呢?
大家应该都听说过 CPU 亲和性的概念,俗称绑核。
是的,就是通过绑核来解决。
我们提前通过分析 /proc/cpuinfo 了解 CPU Node 与 Cpu 逻辑核数的关系,把我们的进程都绑在一个 Cpu Node 上就行了。
五、最后
当然,指定核数来绑定在云时代不太靠谱。
因为会造成 CPU 严重不均匀,甚至不同容器间绑了相同的核数,而互相影响。
所以这个事情还是需要容器平台来做。
常见容器的时候,根据申请的核数个数,提前分配宿主机上相同 CPU Node 的 CPU,然后进行绑核,这样就可以打造一个高性能的容器了。
当然,我们内部还不支持这个,我已经给容器平台提出这个建议了,但什么时候就不好说了。
回到现实,容器平台不支持,我们的程序自己改如何解决这个问题呢?
幸运的是,我们的RPC 框架支持调度组的概念。
假设机器有 2 个 CPU Node,我们就分配两个调度组,每组分配一般的进程。
每个调度组绑在其中一个 CPU Node 下的所有核数上。
就这样,服务还是使用了宿主机的所有 CPU 资源,而且利用上了 NUMA 特性,一举两得。
加油,算法人。
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号:tiankonguse
公众号ID:tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
