缓存服务中通知模块的演化
作者: | 更新日期:
面对一个问题,引入一个解决方案,就会引入另外一系列问题。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
零、背景
我一直负责一个缓存系统。
缓存系统有一个特点:数据更新时,缓存模块需要尽快感知到数据有变更,然后给读业务方返回最新数据。
面对这个问题,实现方案也只有一个:通知。
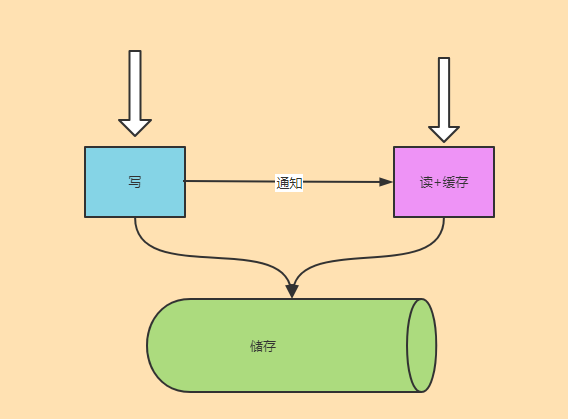
面对通知这个话题,业界经常对写储存、写缓存、删除缓存三者的选择与先后顺序进行争论。
由于我们的系统是批量系统,通知的维度与具体缓存数据的维度不在一个层次。
所以,我们的通知是无法带数据,也无法删除缓存的。
通知只能下发一个可比较的唯一标示,然后通过读触发来比较这个唯一标示来判断数据是否有更新。
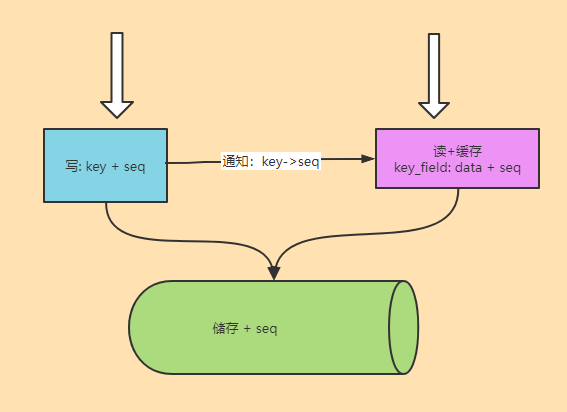
如上图,一个key的某个字段有更新时,写服务需要先得到这个 Key 唯一的递增 seq。
数据写入到储存时,需要把 seq 也写进去。
缓存系统缓存数据时,也需要把 Seq 储存起来。
数据有更新时,通知把一个 key 的最新 seq 下发到缓存服务储存起来。
当有请求来的时候,就可以通过通知的 Seq 与缓存的 seq 来判断数据是否有变更。
我们这里系统最大的特点是:更新的是key下的某些字段,通知的 seq 是在 key 上。
一、旧系统简单实现
面对上面介绍的方案,实现的时候有两个问题:怎么生成 seq,seq 怎么下发到下缓存服务。
早在 2016 年,我们就上线了这样一套通知机制。
我们遵循着简单实现的原则,分别采用了下面的方案。
生成 Seq: zookeeper 来生成。
Seq 下发:生成 seq 模块三读三写储存下来。缓存模块主动轮训去拉最新的 Seq。
架构图与流程大概如下:
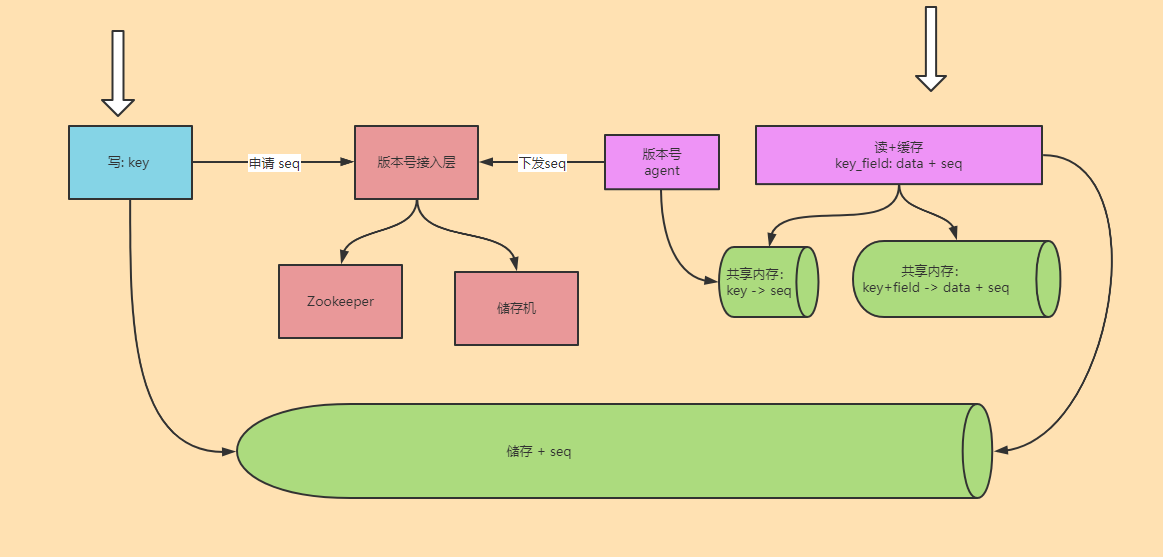
这样设计有几个问题。
1、生成 seq 后,数据和 Seq 还没写入储存,缓存模块可能就得到最新的 seq,从而提前回源数据。
理论上确实存在这个问题。
实际上,这个架构上线了四五年,只有偶尔几次遇到这种情况导致数据大量回源,随后也自动恢复。
仔细分析,原因有四。
第一,下发 Seq 到储存写入 seq 的间隔是毫秒级别的,不同缓存机器的 Seq 下发时间也有差异。
第二,只有某个 key 生成 Seq 但写储存失败时,才会导致大量回源。
不过失败的概率是很小的。
第三,即使某个 key 写储存失败,业务会进行失败重试,随后的更新会马上再次生成更大的Seq。
第四,业务没有重试,大部分 key 的请求量不大,与大盘回源量相比,单个 Key 的量可以忽略。
2、zookeeper 进行放号存在瓶颈,三读三写存在写量的瓶颈。
这个写量瓶颈确实一个问题。
但是我们的场景都是写少读多。
所以,四五年来也没因为这个导致啥问题。
3、zookeeper 放号时,每个数据表对应一个 zookeeper 的 path。
path 的版本号是 32 位整数,可能会用完。
这个问题在前几年没遇到。
近几年,由于开始做短视频,视频表马上就遇到版本号用完的问题了。
在调整服务架构之前,只能手动通过映射新的 path 来解决。
于是,重构之前,每个几个月就遇到一次问题,然后手动修复一次。
二、新系统复杂实现
近两年,我们整个系统进行了全面升级改造。
那自然需要解决放号模块面临的历史问题。
首先,我们自研了一个放号器,最大支持 64 位。
其次,我们自研了一个事务组件,保证储存与通知模块的数据是同时成功与失败的。
最后,seq 下发的时机进行了调整,之前是生成时就开发下发到缓存模块。现在是储存写完数据后,才开始下发 seq。
关于放号器和事务组件,我们之后的文章再展开细讲。
这里重点还是介绍 seq 是如何下发到缓存模块的。
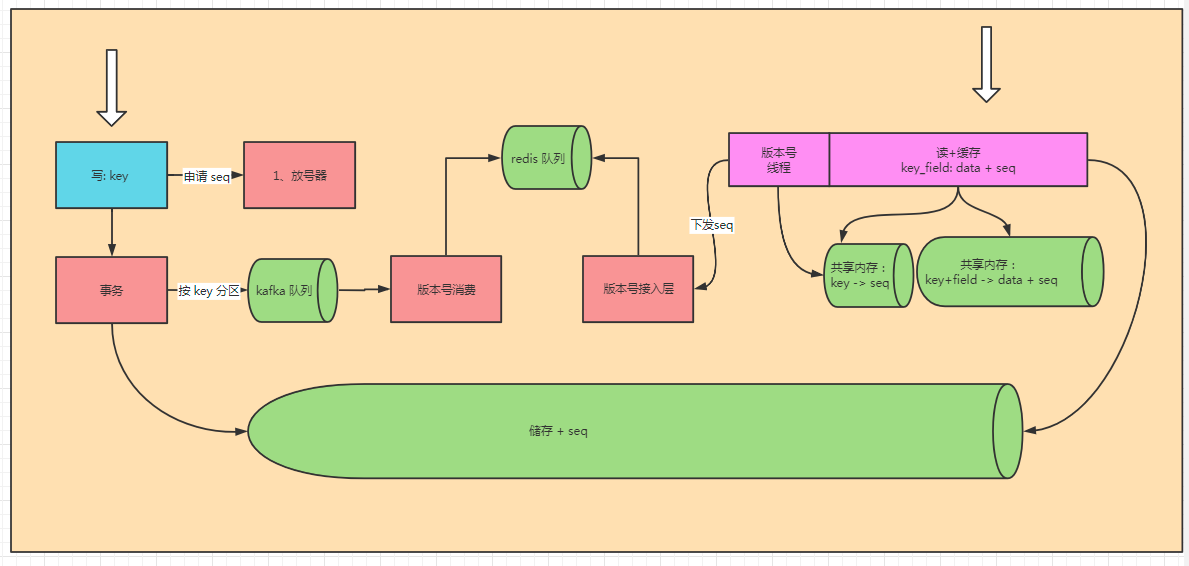
架构图如上。
其实,本质上这个与旧架构只有一个区别:新架构保证版本号下发到缓存层时,储存一定写版本号了。
这个是通过事务解决的,并引入了 kafka 这个消息队列。
面对 kafka,版本号的下发就变得复杂了。
旧架构里,版本号可以理解为单机架构。
全部储存在一个 自研的 zset 里面,保证一个表的 Key 是单调递增的。
这样,对于每个表,只需要记录一个当前下发的Seq 偏移量,不断的按顺序下发版本号流水即可。
新架构里,版本号在 kafka 中称为分布式架构了。
同一个表的数据,会分布在 kafka 的不同分区中。
虽然发 kafka 的时候,可以保证同一个 Key 固定发到同一个分区。
但是一个表的版本号流水依旧分布在不同的分区中。
不同分区的 Seq 消费速度是无法保证的,这就导致没法只记录一个 seq 偏移量了。
是的,问题即解决方案。
既然 kafka 的不同分区的顺序无法保证,那每个分区的 seq 独立下发到缓存模块就行了。
方案确定了,实现就简单了。
每个 kafka 分区单独写到一个 redis 的 zset 中。
缓存模块储存每个表每个分区的偏移量,按顺序拉取数据即可。
当然,每个表的每个kafka分区都是一个 redis Key,可能会导致 redis 连接数特别多。
如果加一层缓存,应该可以大大缓解这个问题的。
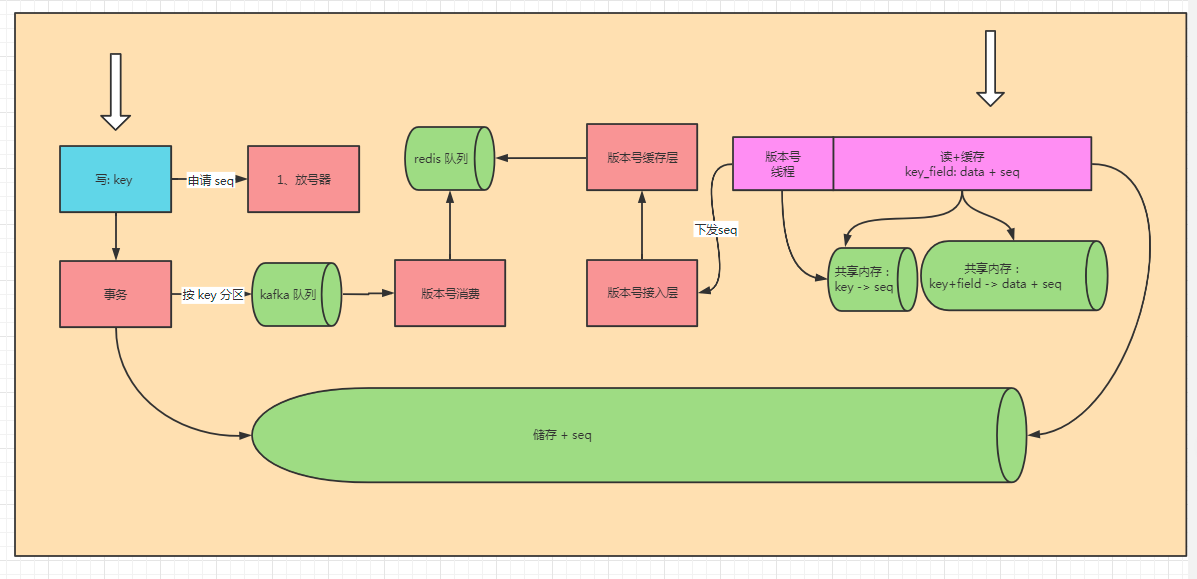
所有,我们的 版本号接入层下面有增加了一个版本号缓存层,用于缓存数据。
三、解耦
如果你了解过高内聚低耦合这个概念的话,就会发现,新系统的版本号模块与 kafka 的分区严重耦合在一起了。
那想要解耦该怎么做呢?
仔细分析旧架构,为啥要求 key 的 seq 顺序下发呢?
第一:相同 key 顺序下发才能保证数据可以更新。
第二:seq 顺序下发,才能不断轮训拉取所有 seq。
面对第一个问题,kafka 依旧保证了相同 key 在相同分区里,这里自然就可以保证顺序。
面对第二个问题,其实也算是一种耦合:数据下发的顺序与 Seq 耦合了。
所以这里的解决方案就是需要增加一层 下发 offset 来与 数据通知 seq 解耦。
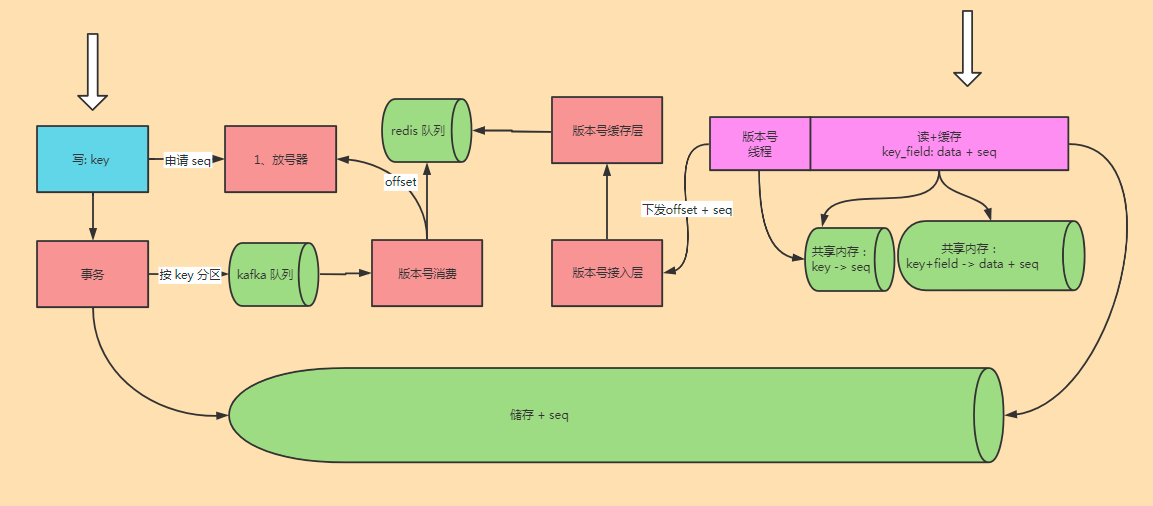
虽然不同 kafka 分区的 seq 下发的时候会乱序,但是这个无所谓,毕竟是不同 key 的。
通过下发 offset,我们只需要保证不丢数据把所有 key 下发下去就行了。
四、最后
缓存模块其实还有一个优化:版本号按需下发。
不过这个按需是放在版本号模块做(按需下发),还是放在缓存层模块做(全量下发再过滤)还是需要斟酌讨论的。
你怎么看这个版本号模块?
你们的缓存服务是怎么下发通知的?
加油,职业人。
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号:tiankonguse
公众号ID:tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
