GO 服务 QPS 上升 20%,耗时翻3倍案例分析
作者: | 更新日期:
涉及到几个GO的知识点。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
一、背景
最近线上遇到一个问题:监控显示,服务的 qps 上升了 20%,但是耗时直接翻了 3 倍。
简单分析后发现 go 定时器存在泄漏,修复泄漏问题后,问题就没有了。
当时在赶项目,想着这里面的具体原因以后再分析。
后来想了想,还是决定投入一些时间弄清楚比较好。
所以那天晚上,我先花了大量知识查询 go 语言的相关知识,之后去分析这个问题,最终找到答案,大概解释了所有疑问。
二、pprof 性能调优利器
golang 官方自带性能调优分析工具 pprof 。
作为一个服务,我们只需要在代码引入包 net/http/pprof,并开启任意一个 http 端口,pprof 包就会自动在 http 端口上绑定对应得 url path 以及处理函数。
import _ "net/http/pprof"
http.ListenAndServe("localhost:port", nil)
pprof 包支持 6 个参数。
profile 查看 N 秒内的CPU分析数据
block 查看导致阻塞同步的堆栈跟踪
goroutine 查看当前所有运行的协程堆栈跟踪
heap 查看活动对象的内存分配情况
mutex 查看导致互斥锁的竞争持有者的堆栈跟踪
threadcreate 查看创建新OS线程的堆栈跟踪
例如要分析性能,就是采集 profile,有下面两种形式。
go tool pprof http://localhost:6060/debug/pprof/profile?seconds=30
curl -o profile.out http://localhost:6060/debug/pprof/profile?seconds=30
go tool pprof -http=:8081 profile.out
其中第二种更实用。
一般我们程序是在 IDC 机器上运行,是没有 go 程序的。
先使用 curl 得到采集的信息,下载到本地,再使用 go 工具开放端口,在本地浏览器可视化的方式查看采集的信息。
参考地址: https://pkg.go.dev/net/http/pprof
三、查看定时器泄漏
利用上面的采集的 profile 信息,很容易就可以发现 CPU 最高的是 runtime.siftdownTimer。
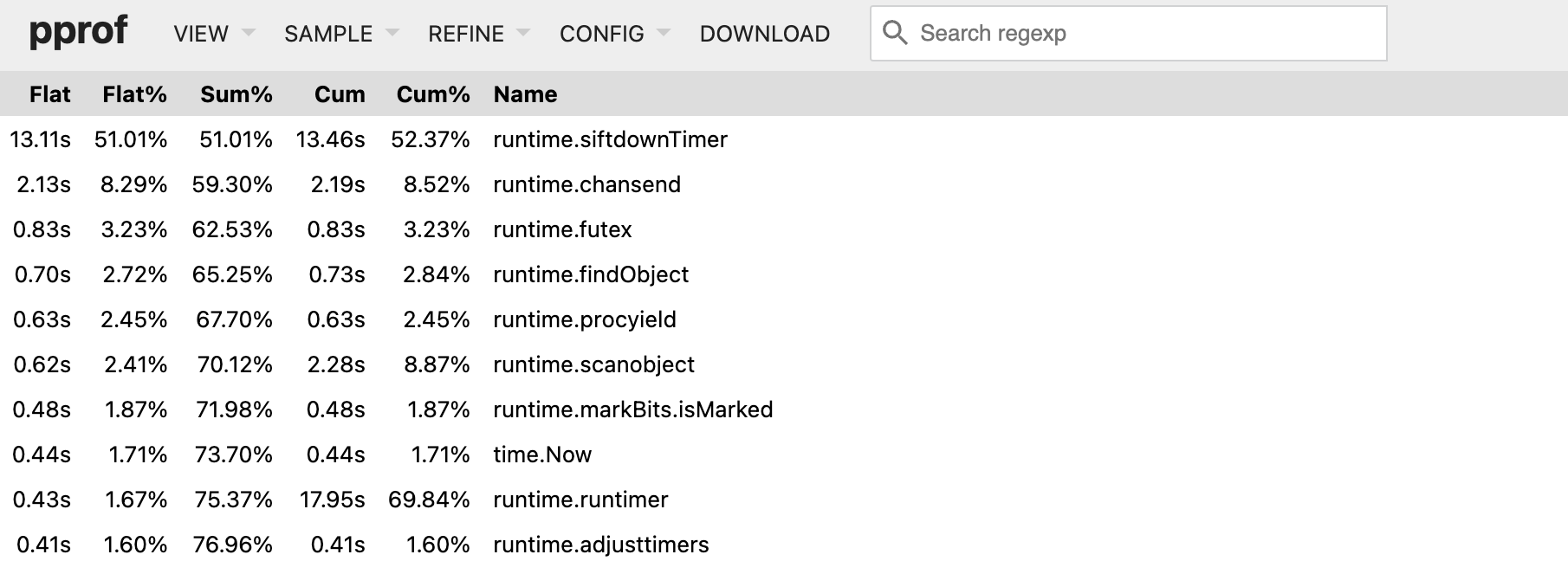
看火焰图,同样是这个函数最占 CPU 时间。
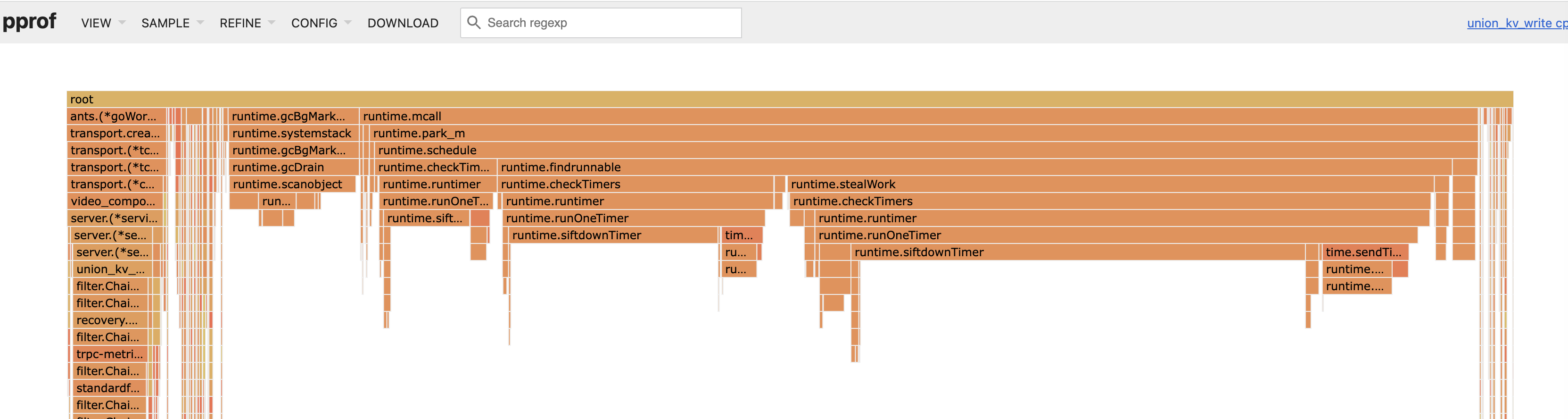
网上搜索关键字 runtime.siftdownTimer,会发现是 go 的定时器用的不对,存在泄漏。
所以我们需要分析出是哪个包或代码引入这个定时器泄漏的。
定时器也会对应一片内存。
如果定时器泄漏,自然也会在内存上体现出来。
所以我们可以通过采集 heap 信息来查找泄漏来源。
curl http://ip:port/debug/pprof/heap > heap.out
go tool pprof -http=:8082 heap.out
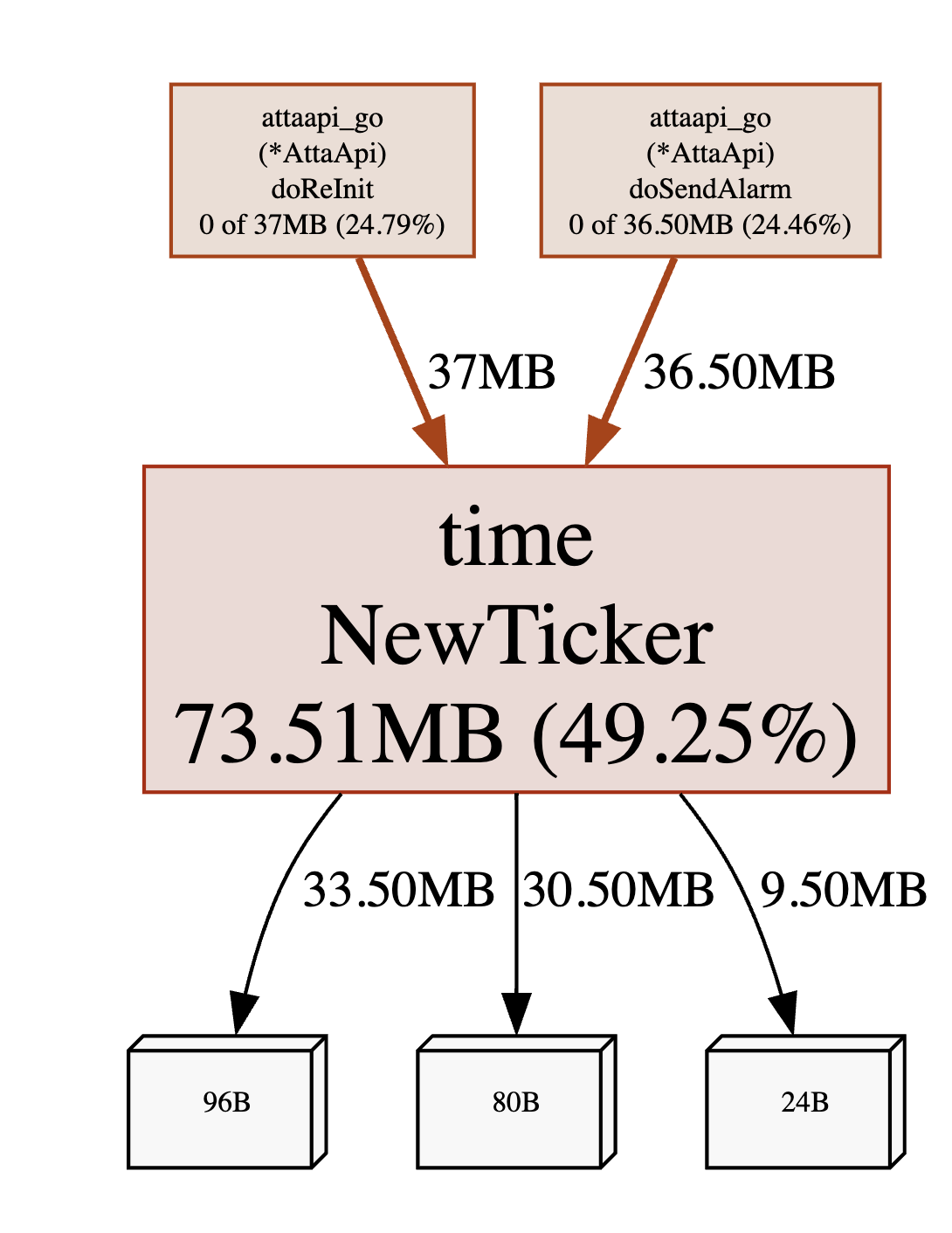
这个内存信息可视化后,直接就可以看到分配内存最多的函数 time.NewTicker
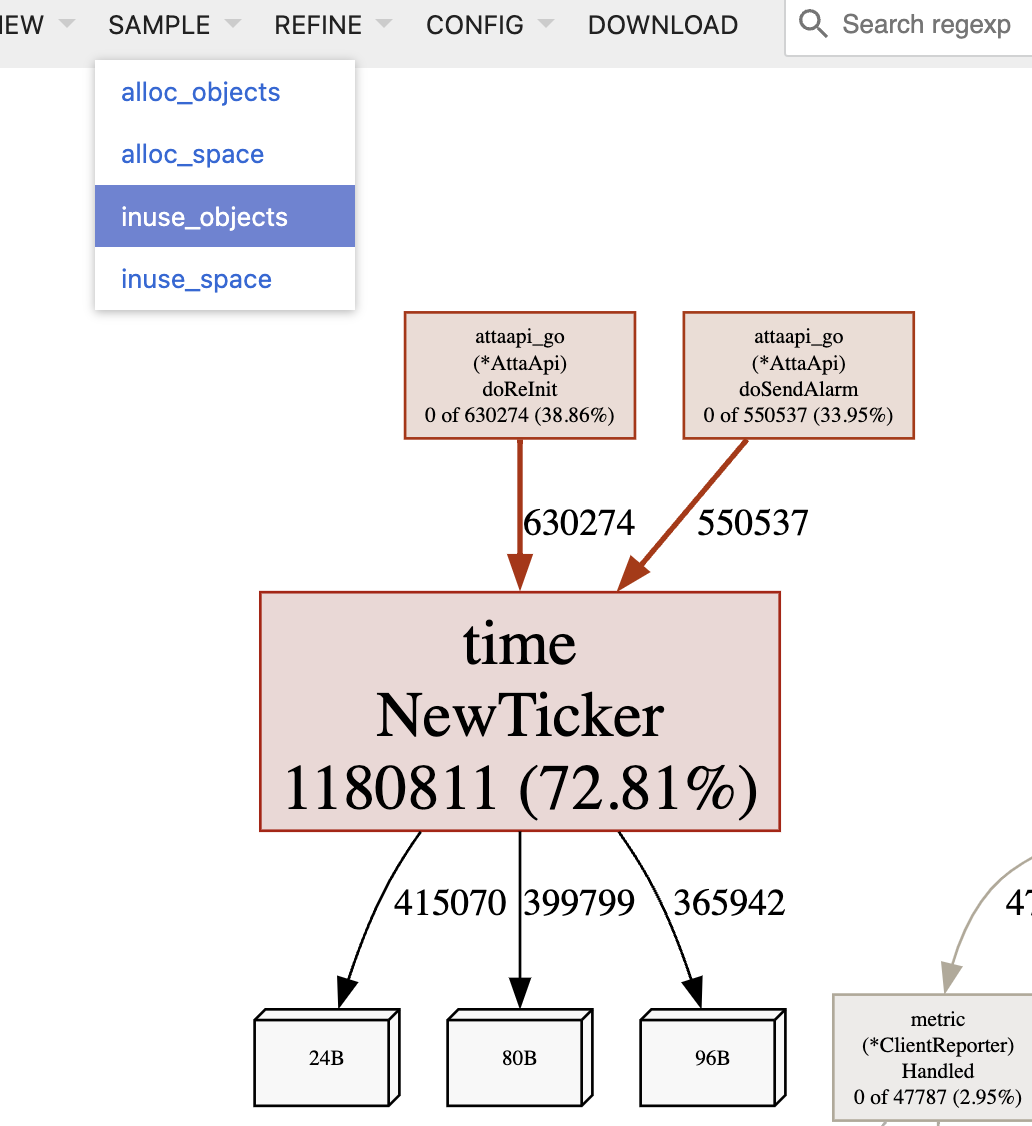
我们把可视化切换为 inuse_objects后,也可以看到分配的次数,可以理解为定时器泄漏的次数。
我们找到对应的包,搜索 NewTicker 即可看到是对应的代码,然后分析什么场景没回收定时器即可。
当然,我这个场景,定时器泄漏的是第三方库。
所以找到对方后,对方说修复版本换了一个包,然后对方给我发了一个新的包地址。
这个就有点坑了,当前包的最新版本有定时泄漏,即使运行 go get 也没法主动升级库到最新版本。
四、耗时上涨猜想
正常来看,定时器泄漏,内存还有很多,CPU 也没有跑满,qps上升20%,耗时翻 3 倍还是解释不通的。
针对耗时问题,根据我的经验,只有两种情况。
第一种是同一时刻来了很多请求。
第二种是服务卡住了,对应的请求的耗时都需要加上卡住的时间,另外卡顿恢复后,CPU还需要处理卡主期间的所有请求,耗时上涨的逻辑就要与第一种类似了。
这个我之前写过一篇文章《服务都异步化了,为啥批量请求耗时这么高?》,道理是类似的。
文章中的内容浓缩概况下,就是服务一个请求处理 1ms,1 秒则能处理 1000 个请求。
假设每秒有 500 个请求平均的到达,则 CPU 为 50%, 平均耗时为 1ms,P99 耗时也为 1ms。
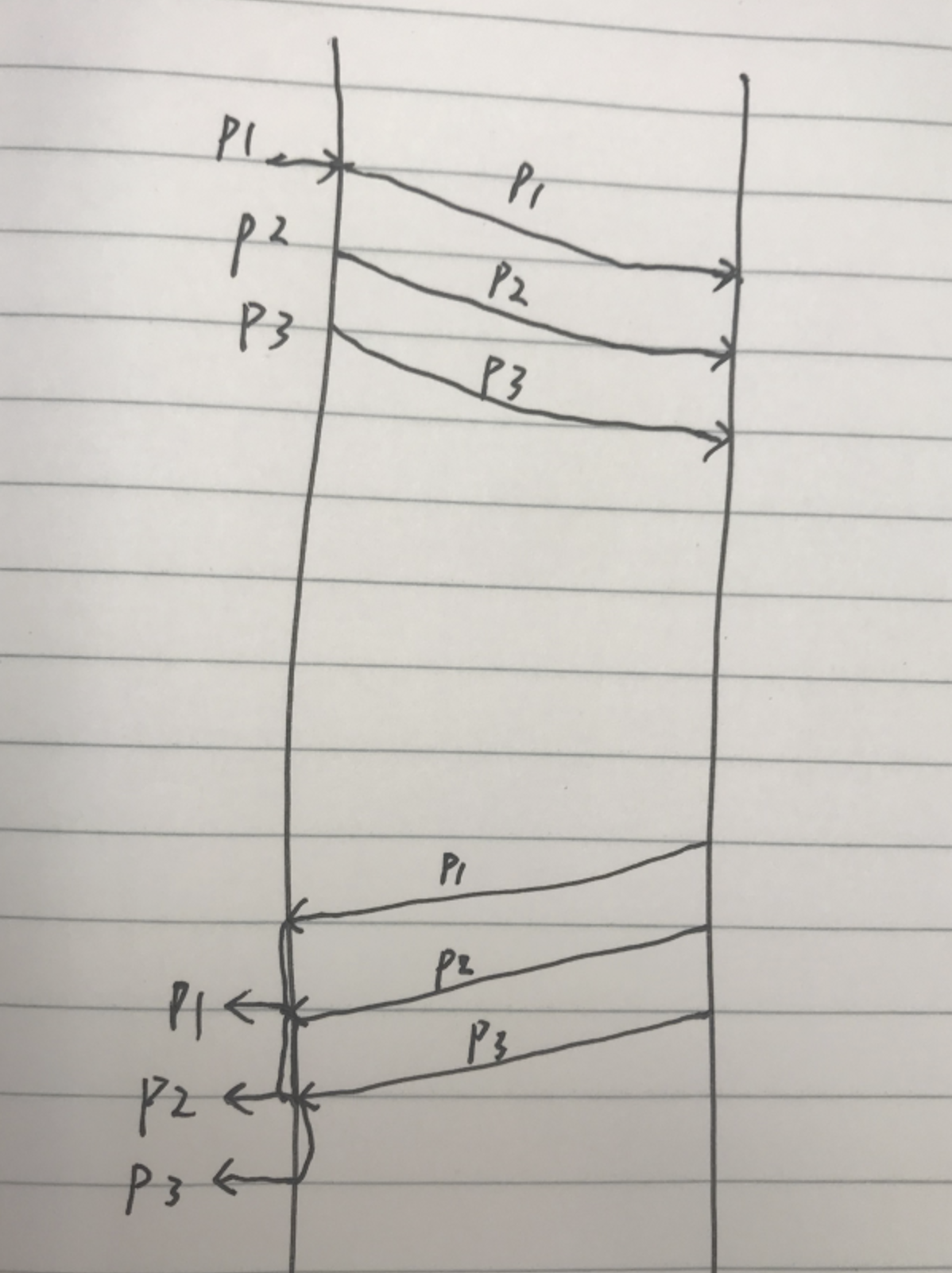
假设还是每秒来 500 个请求,都是每秒的第 1 毫秒到达,秒级 cpu 还是 50%,而平均耗时则升高为 250.5ms, p99 耗时高达 495ms。
四、定时器泄漏会导致什么问题?
针对这个,我先咨询 chatGPT 定时器泄漏的问题。
第一个问题是定时器自身的性能是否会受影响。
原来,定时器泄漏,自身性能不受影响,但是 goroutines 和内存会间接被泄露。

第二个问题是定时器泄漏,为啥会影响性能。
答案的第一部分,解答了为啥 profile 中 CPU 最高的是 runtime.siftdownTimer。
理由是泄漏的 goroutines 依旧都会执行,这些会消化 CPU,所以 CPU 占比较高。
答案的第二部分是导致内存泄漏,从而触发垃圾回收,进而影响性能。

针对这个垃圾回收,我继续问:go 的垃圾回收机制会影响性能吗?
答案中看到了一个 “低暂停时间” 关键词,后面再问 chatGPT 没有给出清晰的答案。
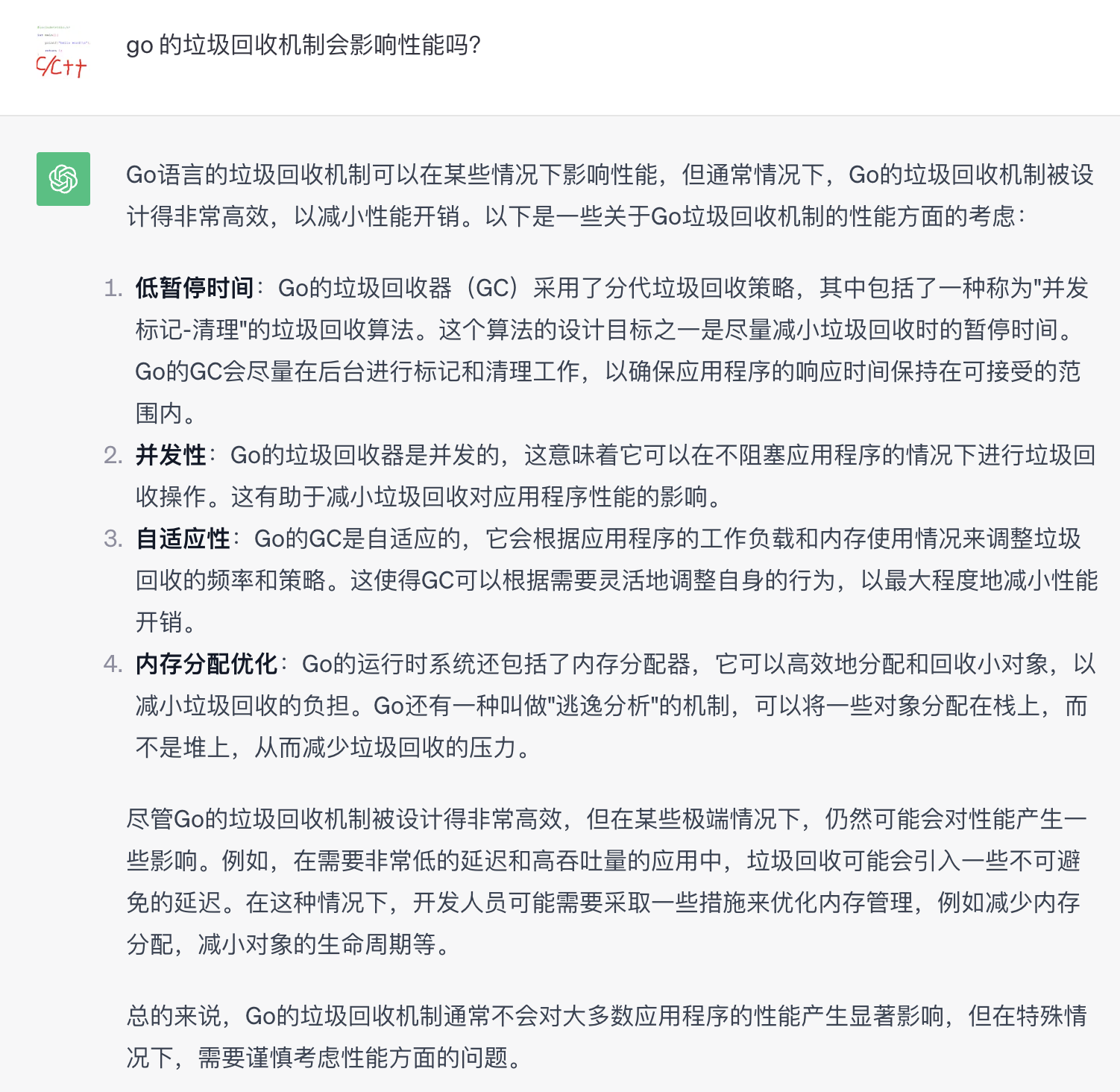

通过与 chatGPT 对话,我明白了定时器自身不会有性能问题。
这里只会导致两个其他问题。
第一是协程泄漏,协程不断运行会消化 CPU,导致 CPU 浪费。
qps 上涨前,CPU 也一直在浪费,耗时也没上涨,所以与这个泄漏关系不大。
第二是内存泄漏,这个涉及到垃圾回收的知识,需要进一步研究。
五、GO 垃圾回收的机制
ChatGPT 关于 go 垃圾回收的回答,我一直不满意。
所以我只好去 google 查资料,看下 go 垃圾回收的介绍文章。
随便看下 TOP 5 的文章,我了解到 go 的垃圾回收有一个 STW 的机制。
是的,我并不关心 GO 垃圾回收的具体算法,我只关心这套算法设计有啥问题。
而最大的问题就是 STW,全称是 Stop The Word,用大白话就是进程会卡主。
这不就是我苦苦寻找的卡顿吗?
于是查看 go 卡顿的监控指标 go_gc_pause_ms,果然卡顿的很厉害。
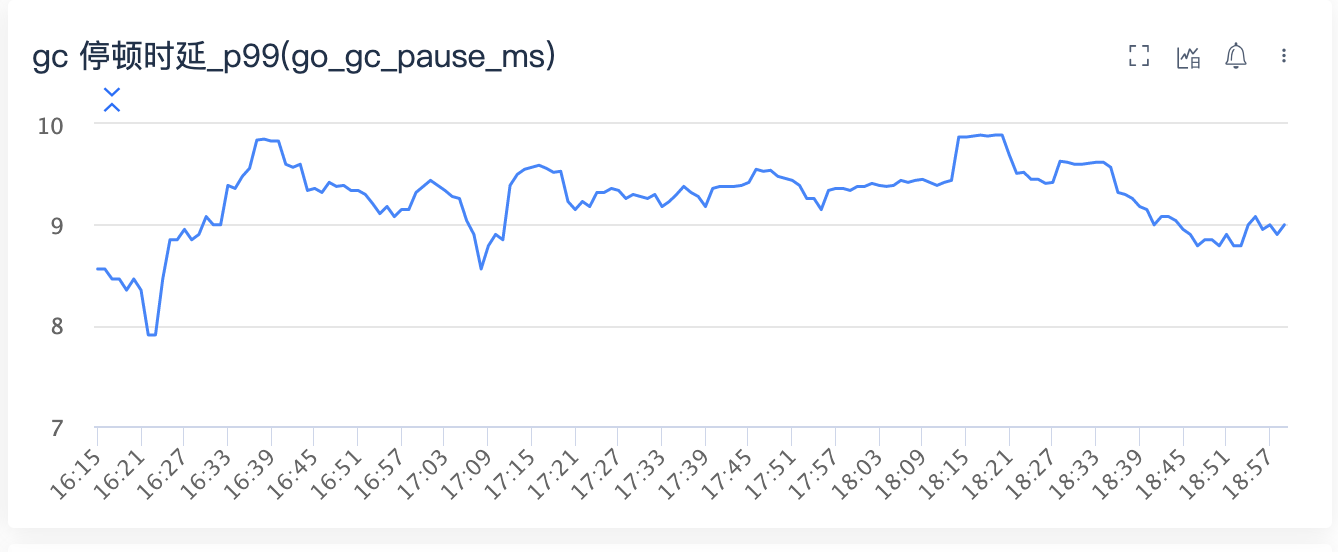
这样一切行为都解释通顺了。
六、耗时为啥翻 3 倍
卡顿会导致耗时上升,但是为啥流量上涨 20%, 耗时就翻 3 倍呢?
难道 qps 到达一定数量,触发了 GC 的 STW 涌现(量变导致质变)?
由于监控是分钟级别的,我捞了所有写流水,按秒级聚合,发现流量是相当不均匀。
这是日常的流量,就有点不均匀。
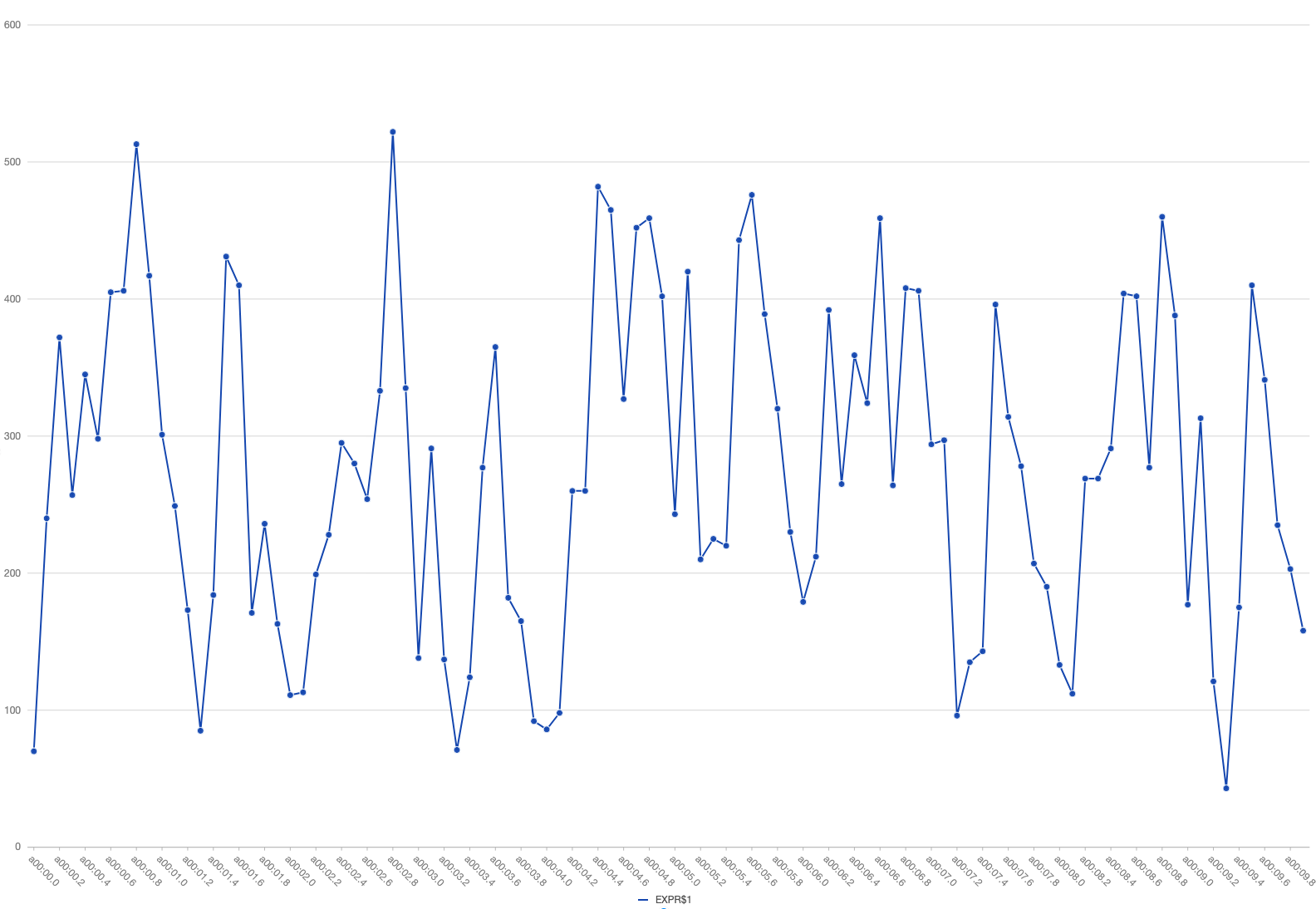
而下面是增长的 20% 的 qps。
有几秒 qps 未0,而有些秒 qps 是几千,这样 qps 就不会涨 20% 了,而是涨了 3~4倍。
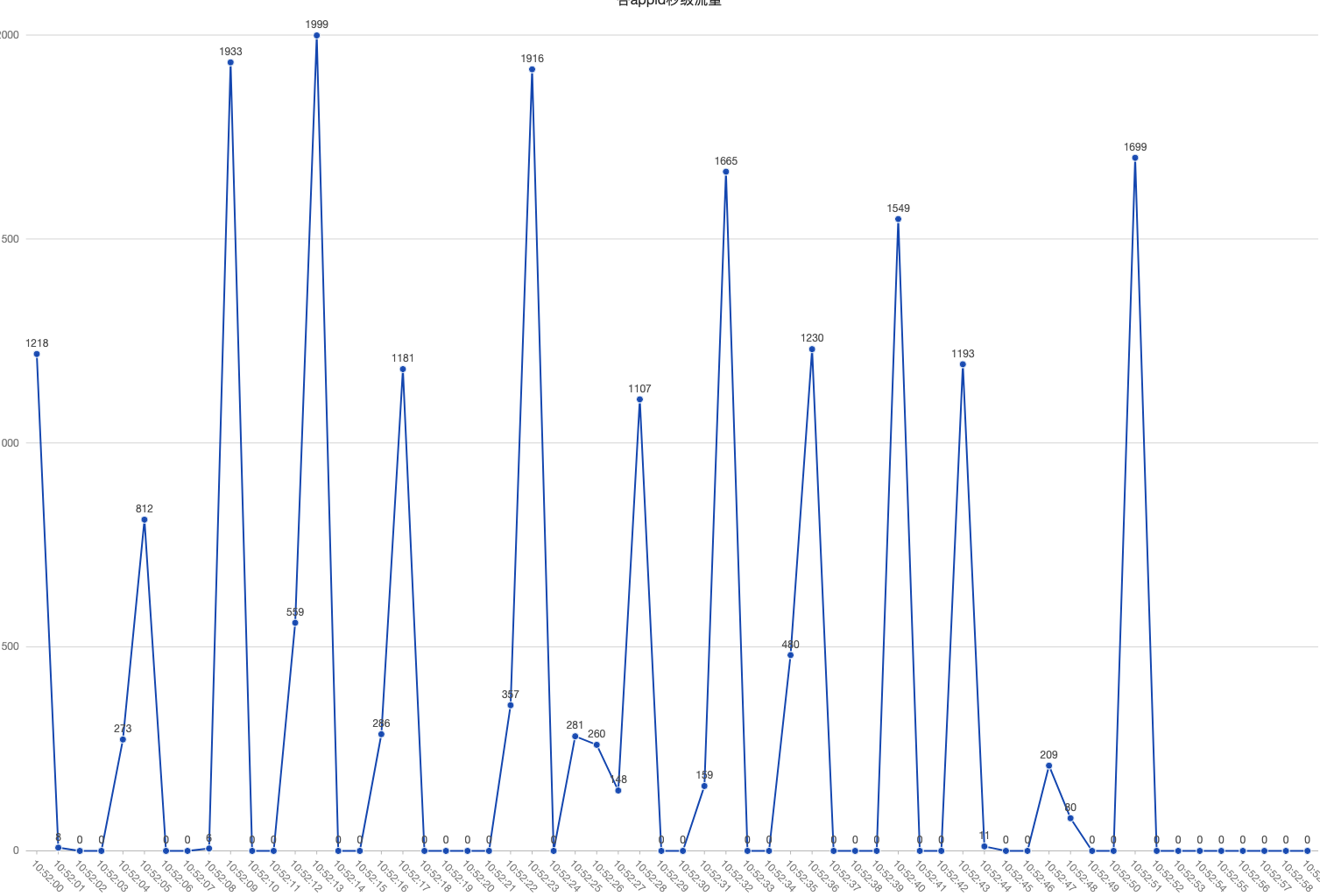
所以耗时上升的第二个原因是来源 qps 的极度不平衡,瞬间来了很多请求,局部 CPU 是跑满的,耗时上升也就得到解释了。
七、总结
总结下这个问题,是三个原因导致的。
一方面是定时器泄漏,协程增多,导致CPU调度负载升高,耗时会升高,这个属于调度层面的原因。
另一方面,定时器泄漏,进而内存泄漏,导致GC卡顿增长,这个属于垃圾回收层面的原因。
最后一方面,来源流量不平滑,时间点高度集中,导致局部时刻 CPU 跑满,等待排队,从而耗时升高,这个是业务层面的原因。
这是分析出了这个问题的原因,记录一下。
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号:tiankonguse
公众号ID:tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
