减少磁盘IO,减少数据COPY,性能提升5倍
作者: | 更新日期:
review 代码,发现一些问题。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
零、背景
最近团队的一个服务偶尔 coredump,都是 coredump 在固定的位置。
固定的位置出问题,显然是这块代码有 BUG。
相关同学说 review 了那块代码,没发现问题。
于是我就好奇起来,去看了下相关模块的代码。
看之后没找到原因,不过发现一个重大问题:代码的架构设计存在很大的性能问题。
当然,这块代码是多年前其他人写的,现在 review 后发现不合理,后面肯定需要进行优化的。
一、 文件协议
根据 core 文件的堆栈,可以确定在读取文件数据时异常了。
具体来说,文件有一定的组织结构。
文件数据没问题,但是代码不知什么原因,没有正确的解析文件,错位了,导致解析出的数据是错误,从而导致 coredump。
文件的协议如下:
文件分为 N 个 Block。
每个 Block 分为两部分:
第一部分固定 20 字节,内容是数据的长度 len。
第二部分是 len 个字符,代表多个item 通过 protobuf 数组编码后的内容。
对于这个协议,其实我有两个疑问。
第一:为啥文件中没有储存 Block 的个数?
第二:为啥 Block 的第一部分是 20字节明文字符串,而不是4字节储存数字(21亿足够了)。
当然,这些设计问题,也不是那么致命,也不是本文的重点,这里就继续吧。
二、coredump 位置
针对这个文件协议结构,当前的代码是循环尝试读取 Bloick 信息。
具体是先 fread 读取 Block 的第一部分得到长度,然后 fread 读取 block 的第二部分数据,扔到队列中。
代码大概如下:
FILE* pFile = fopen(file_name.c_str(), "r+");
while (!feof(pFile)) {
// 读当前DataBlock字节数
int ret = fread(line, 1, headerSize, pFile);
if ( ret < headerSize) break;
int bufSize = atoi(line);
int ret = fread(tmpBuf, 1, bufSize, pFile);
if (ret == 0) break;
// 将当前DataBlock(序列化后)放到队列
std::string tmpLine(tmpBuf, bufSize);
data_stream_.push(tmpLine);
if (ret < bufSize) break;
}
fclose(pFile);
// 删除当前处理完的文件
remove(file_name.c_str());
针对上面的代码,读取 block 的第二部分数据时,返回码判断其实是有问题的。
理论上,应该判断返回值与 bufSize 是否相等,不等代表读取异常。
不过这个问题不会导致 coredump,顶多是向队列塞了一个脏数据。
毕竟这个判断放在了最后,即最后依旧会判断读取是否符合预期,不符合预期就会结束文件读取。
当前的问题是 coredump 在 tmpLine 的定义上。
原因是 bufSize 的值很大很大,导致申请内存失败。
为啥 bufSize 的值很大呢?
因为读取 Block 第一部分后, line 中的值不正确。
为啥 line 中的值不正确呢?
这就需要分析代码的架构设计了。
分析完架构后,发现架构有很大的性能问题,但是不应该导致 coredump。
所以,为啥 coredump 没有找到原因。
负责人提的建议是先对第二个 block 的返回值做正确的检查,这样至少不会 coredump 了。
我则提出直接一步到位的要求:架构明显不合理,不应该写文件的。
问题出在读文件上,直接把文件的逻辑都干掉,以及进行性能优化。
三、架构分析
分析这个模块的架构,发现要做的事情很简单,但是架构设计的有点奇怪。
根据架构图可以得到这个模块的功能:从 COS 中拉取到数据,解析后写入到共享内存。
架构图如下
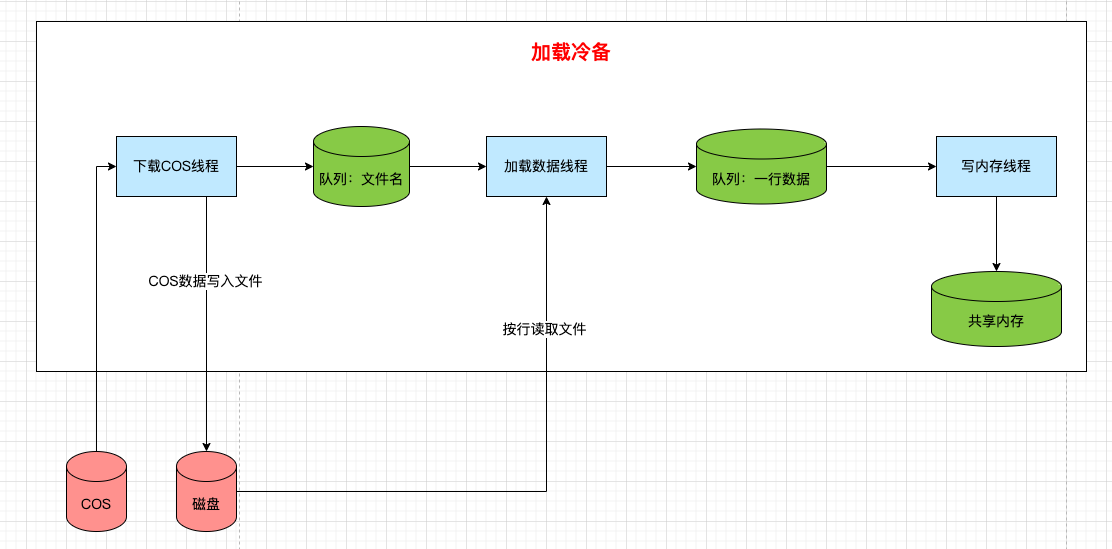
流程也文本描述一下。
1)下载线程从 COS 下载文件数据
2)下载线程把下载的文件数据写入到磁盘
3)下载线程把磁盘文件名扔到文件名队列
4)加载数据线程从文件读取每一个Block,数据扔到数据队列。
5)写内存线程消费数据,解析出数据列表,然后列表的每个数据解析出业务数据,业务数据写入到共享内存。
四、架构问题
问题1:磁盘
这里的 COS 数据根本没有写文件的必要。
一般数据写磁盘用于备份数据,即服务重启时,加载磁盘快速恢复数据。
但是这里使用磁盘,仅仅是当做一个消息队列。
服务重启后,这份数据永远不会再使用了。
问题2:频繁IO
如果一个文件只写一次磁盘,读一次磁盘,勉强也可以接受。
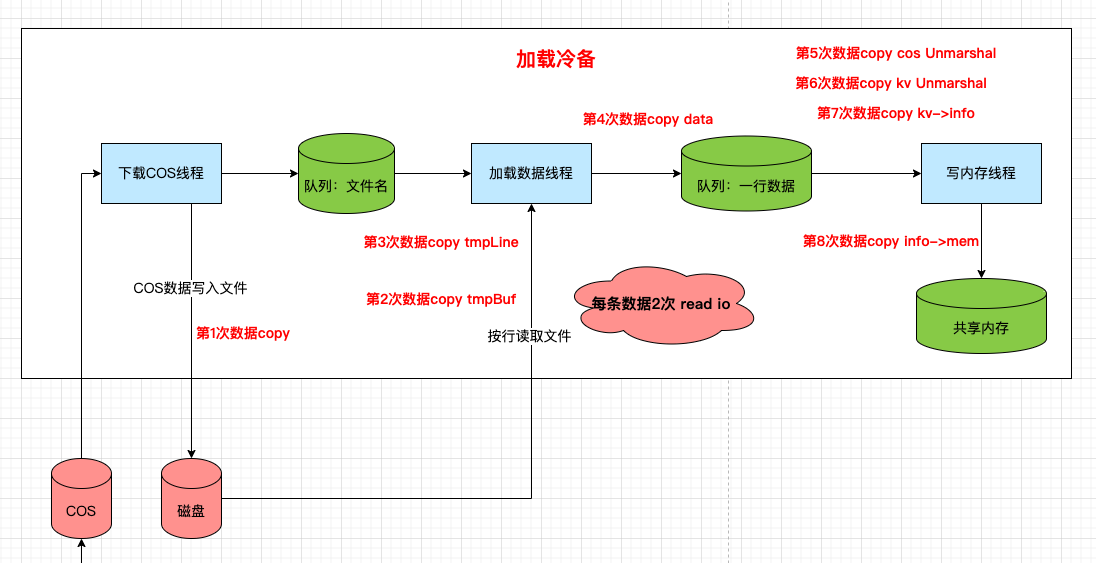
但是这里是写一次磁盘,读 2N 次磁盘, N 是文件里的 block 个数。
我线上跑了下 Block 的个数,一共需要读取 12338880 个 Block,即一千万个 Block,即有两千万次 fread io 操作。
问题3:8次数据copy
0)从 COS 读取数据,一次数据 COPY.
1)数据写入磁盘至少算一次数据 COPY。
2)从磁盘读取数据,又是一次数据 COPY。
3)磁盘的数据读到临时 buf,会组装为一个 string 放入队列,又一次数据COPY。
4)消费 block 队列,又一次数据 copy。
5) block 对象解包,又一次数据 COPY。
6) block 对象是一个数组,数组的每个 item 都需要解包,又一次数据COPY。
7) 每个 item 对象写内存前,会转化为临时对象,又一次 COPY。
8) 临时对象写入共享内存,又一次 COPY。
五、优化
架构优化很简单,把磁盘去掉,只保留一个消息队列,消息队列使用智能指针来储存数据。
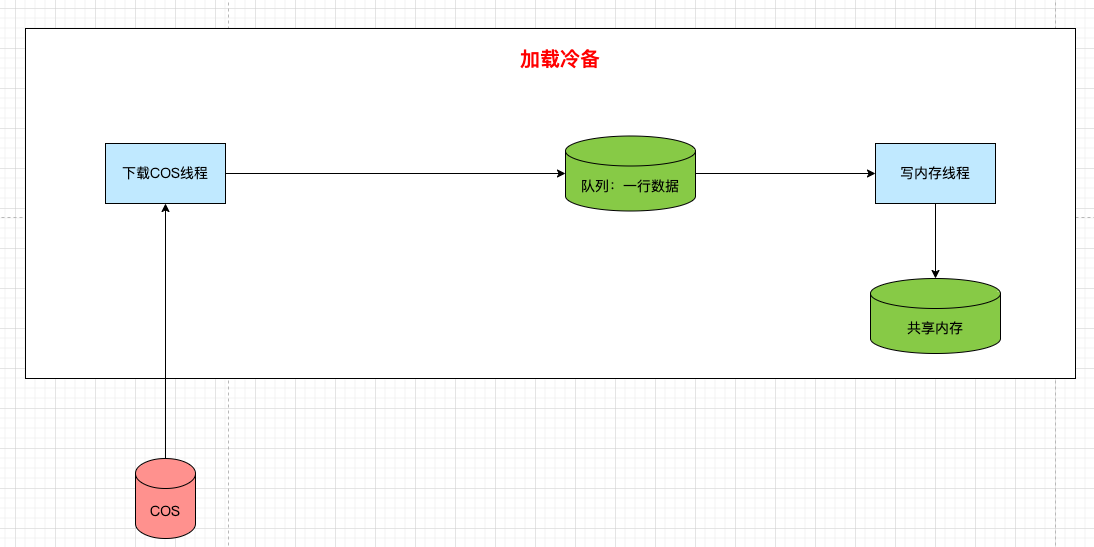
代码实现也很简单,拉取数据,组装智能指针,扔到队列里。
std::string content;
cosProxy->GetObject(ctx, content, cos_path);
std::shared_ptr<std::string> strPtr = std::make_shared<std::string>();
strPtr->swap(content); // 内存交换,zero copy
data_stream_.push(strPtr); // 放入队列
是的,文件的解析由写内存线程去理解。
这样的好处是全程都可以服用智能指针这一个字符串,只需要维护一个偏移量和长度即可,不需要进行频繁数据 COPY 了。
写内存线程消费到 COS 数据时,每解析出一个 Block 的位置,直接使用指针和长度去解包,得到具体的内容。
这样,就直接从第一步拉取的 COS 文件,解析出了 Block 对象,中间直接少了 4 次数据COPY。
Block 对象中是一批 item, 再次解包不可避免。
但是 item 的对象可以 swap 传递给下游,这样又减少一次COPY。
总的算下来,至少减少了 5 次 数据COPY。
六、性能数据
相关代码抠出来,下载COS 临时使用数据复制代替,写共享内存也使用数据复制代替,使用线上 COS 数据跑了一下,时间竟然提升了 5 倍。
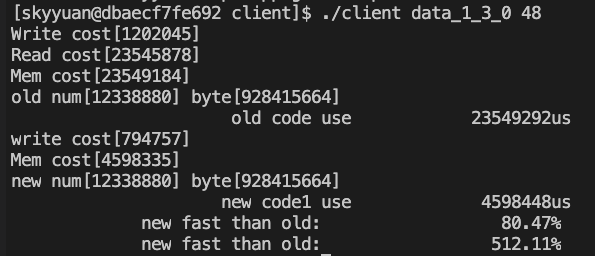
具体来说,共48个文件,每个文件1233个Block,单个文件24M。
根据图中的信息可以发现,优化前,总耗时 23.5秒。
读文件线程的耗时也是 23.5秒,说明磁盘IO操作,以及几次复制,很消耗性能。
而优化后,耗时降低到 4.6 毫秒,性能提升了 5 倍。
七、最后
一个 coredump 问题,意外发现模块设计不合理,优化后竟然可以提升 5 倍性能。
这么看来,后面有必要对核心链路代码进行代码走查,应该可以进一步提升不少性能。
对了,其实这里还可以进一步优化,后面有机会再单独介绍一下。
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号:tiankonguse
公众号ID:tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
