ComfyUI 学习 AI 生图原理,10秒一张
作者: | 更新日期:
10秒生成一张高质量图。
本文首发于公众号:天空的代码世界,微信号:tiankonguse

PS: 前文《AI生成动漫图片,国内比国外更懂动漫》分享了一个自拍相关的 prompt,使用本地 comfyUI 生成如上,国外的模型,生成的也是外国人。
零、背景
前文《3个免费AI 生成图片的方法》提到,我都是在网站上生成图片的。
后来在《comfyui 本地无限制高清文生图》提到,本地部署了文成图软件,可以无限制生成任何想要的图片。
本地生图的时候, Flux Schnell 模型的效果最佳,但是每次需要等待 5 分钟,时间太长了。
另外,有时候我想要对图片进行处理,比如换脸、换衣服等,由于不了解 AI 生图的原理,一直不知道怎么操作。
所以,我打算借着 ComfyUI 这个工具,来学习一下 AI 生图的原理。
目标是最终可以快速的生成任何自己想要的高清图片,以及可以在指定图片的基础上,按照自己的想法进行二次生成图片。

一、工具选择
在学习 ComfyUI 之前,我在思考:学习 AI 绘画使用 ComfyUI 正确高效吗?是否可以使用其他工具代替?
这就需要看下工具有哪些分类。
第一类是商业产品,类似于 Midjourney 与 ChapGPT 这样的产品。
固定的几个模型,我们只需要去想怎么写 prompt 就行了。
第二类是开源工具,类似于 SD Web UI、ComfyUI 这样的产品。
需要花费时间去被本地部署,需要电脑硬件支持,好处是可以使用很多大模型,以及图片没有任何限制。
对比优缺点如下:
学习成本
商业产品:学习成本低,一般针对用户做了大量的优化,并且有配套的详细的教程。
开源工具:学习成本高,一般是互联网上世界各地的人一起做的,属于恰好能用的产品,UI 没有做优化,BUG 较多,教程比较简单,新手不友好。
自由度
商业产品:低,功能比较单一,扩展性较低,只能使用提供的功能。
开源工具:高,可以自由修改产品功能,有很多开源模型可以切换,生成内容没有任何限制。
费用
商业产品:高,免费只能试用几次,之后需要付费。
开源工具:中,只需要电脑配置,之后就不需要额外费用。
基于学习成本、自由度、费用这三个维度的对比,我最终选择使用 开源工具 来文生图。
开源工具有 SD WebUI 和 ComfyUI,由于 ComfyUI 灵活性更高,可以自由制作工作流来实现各种功能。
所以这里选择 ComfyUI 是最优选择。

二、AI 生图原理
要理解 ComfyUI 的工作流,需要先对 AI 生图的原理有一个大概的了解。
目前的 AI 都使用一个叫做 Stable Diffusion(稳定扩散)的方法来生成图片。
例如,要生成“猫站在城堡”的图,对于用户的流程如下:
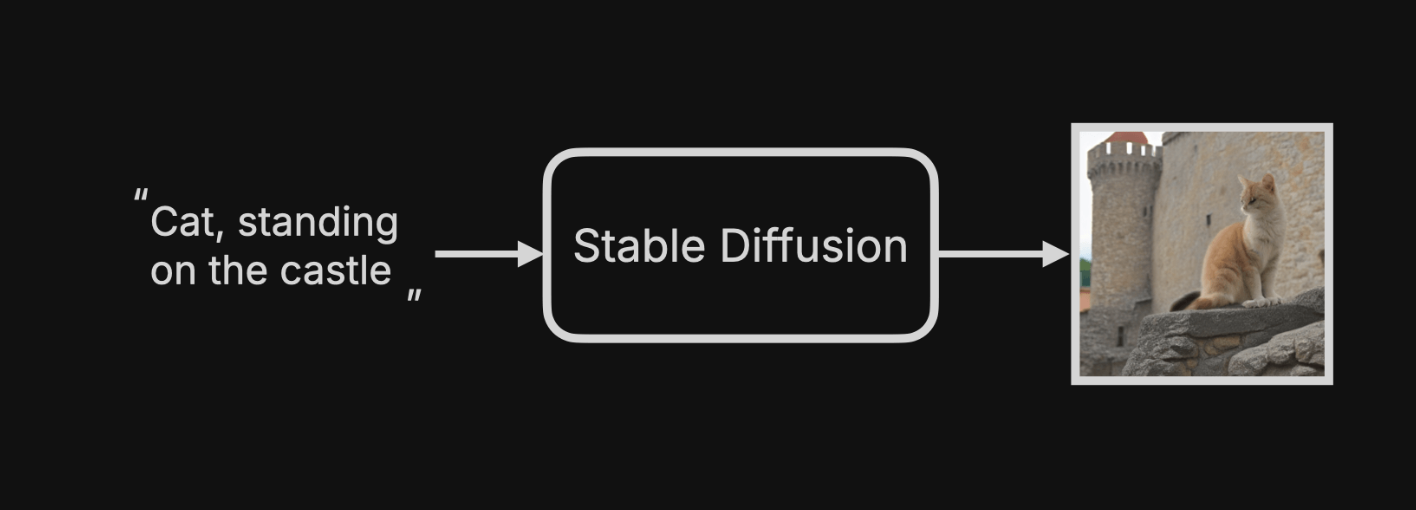
把 SD 展开,背后涉及到六个步骤。
第一、输入文本 prompt.
第二、文本 prompt 通过 Text Encoder 转化为词特征向量。
第三、生成一个指定大小的布满电子雪花的随机噪音图。
第四、prompt 向量 与 噪音图向量转化到 Latent Space(潜空间),不断的计算扩散降噪,生成目标图向量。
第五、目标图向量通过 Image Decoder 转化为图片。
第六、保存或显示图片。
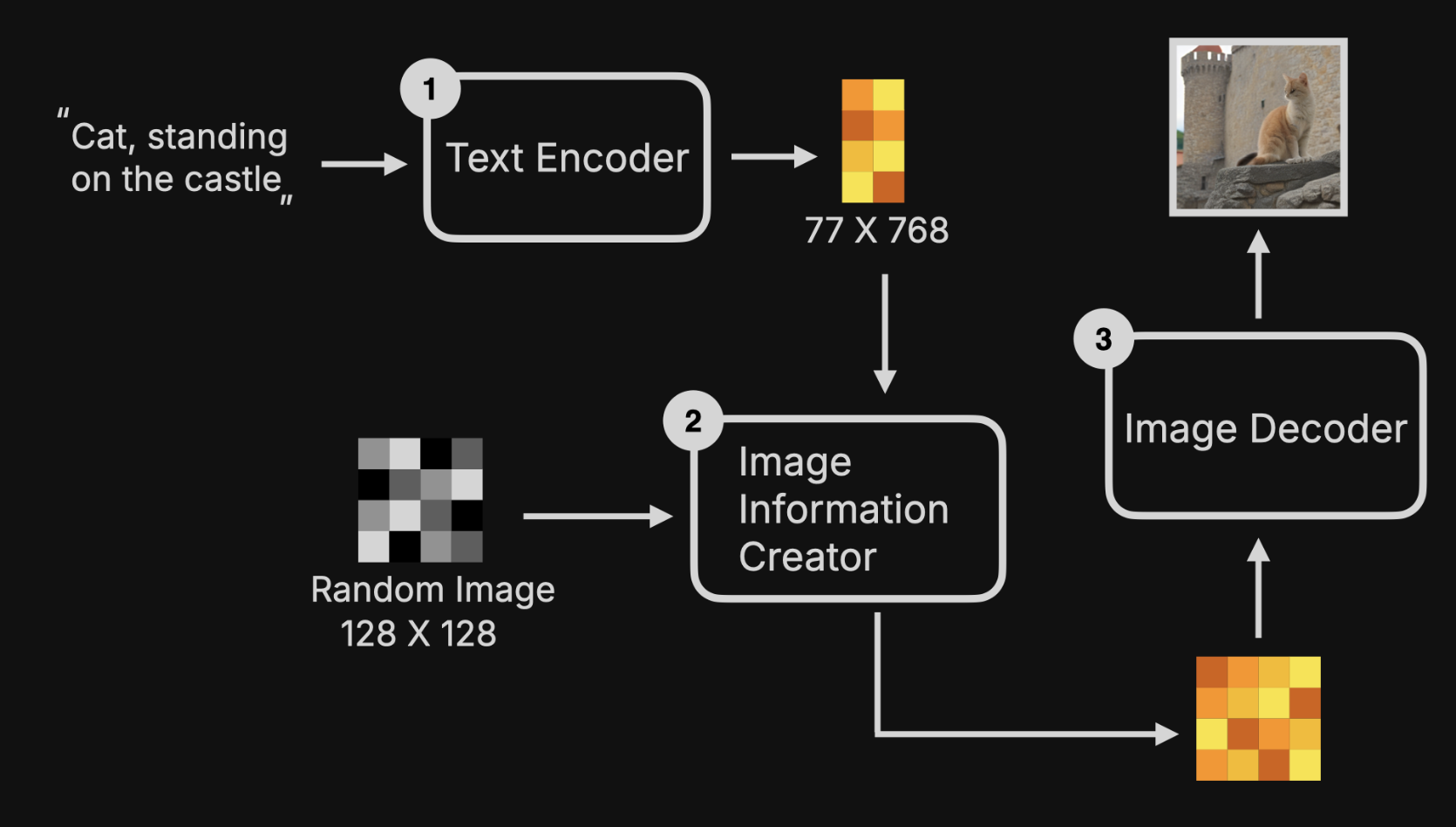
可以发现,最关键的是第四步骤降噪计算。
AI 生成画图片的过程,其实是降噪的过程。
这也是 Midjourney 为何可以看到图片由模糊逐步清晰的缘故。
降噪 Denoise
降噪分为多个步骤,一般步骤越多,图片质量越好。
四步降噪如下图,其中每一步降噪的操作是类似的。
可以发现,前一步降噪的输出当做下一步降噪的输入,就这样不断地循环,最终就可以生成目标图了。
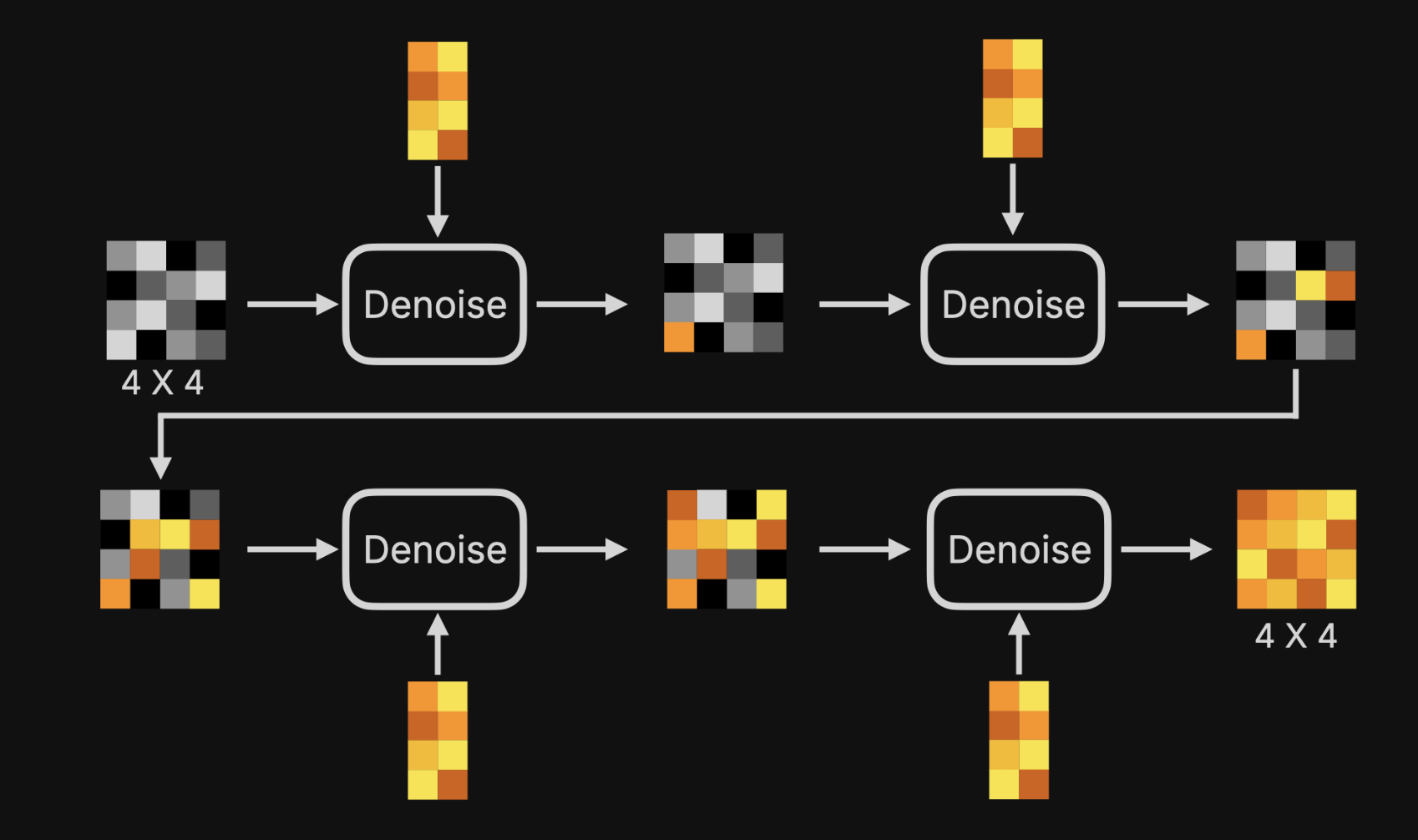
降噪的具体操作如下图。
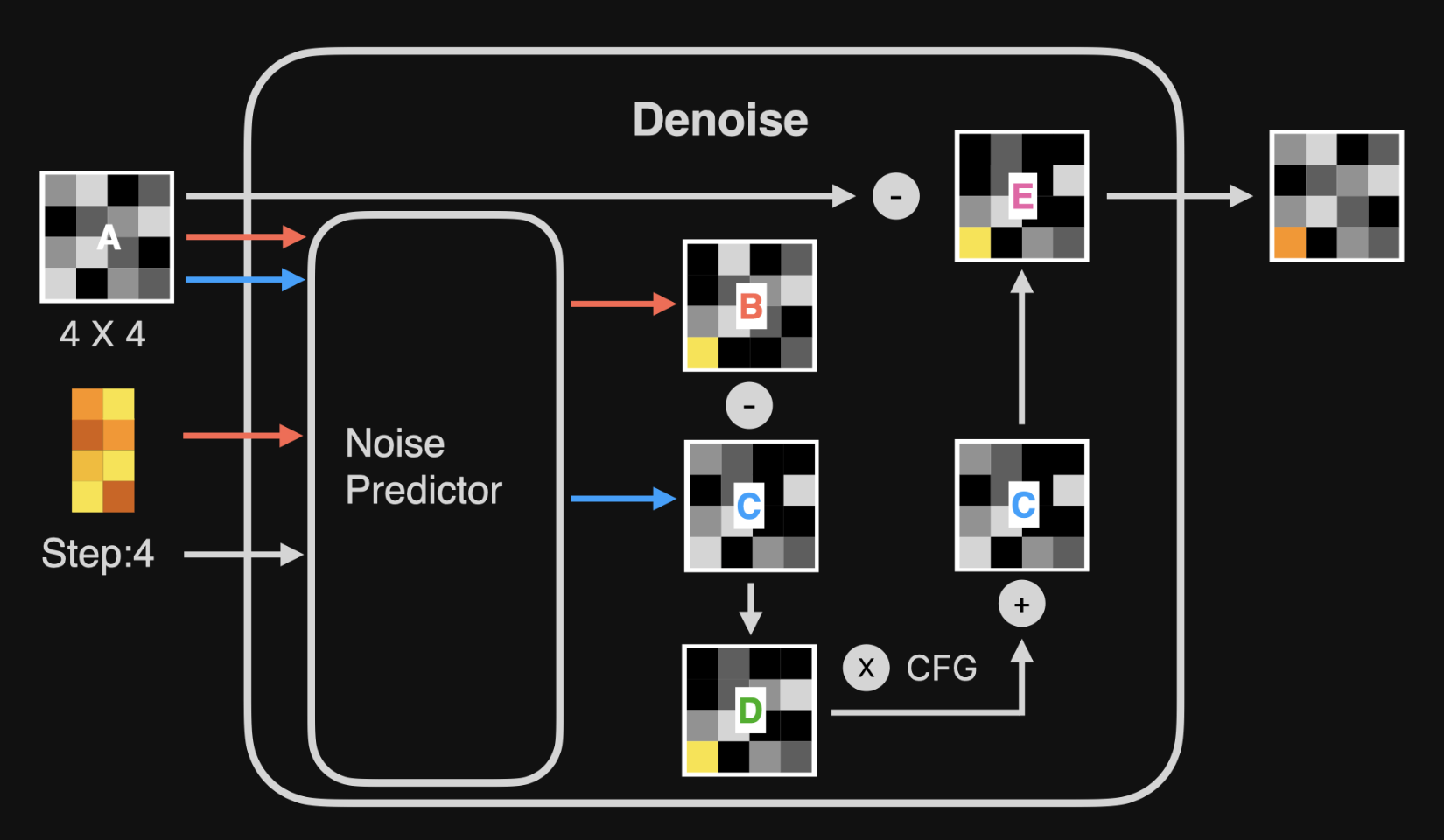
图中可以看到一个 Noise Predictor(噪音预测器)的模块,他能能预测出随机图里包含什么噪音的模型。
先介绍下输入。
图A 是前一步骤输出的噪音图,第一次是随机的噪音图。
黄色马赛克是文本的 prompt向量。
然后来看下降噪过程。
第一步,看橙色的线,Noise Predictor 使用一个固定尺寸大小的图片和 prompt 的向量生成一张噪音图 B。
第二步,看蓝色的线,Noise Predictor 还会在不包含 Prompt 向量的数据的情况下,生成一个噪音图 C。
第三步,将噪音图 B 和 C 相减,生成一个噪音图 D(含有 prompt 的信息)。
第四步,通过放大系数 CFG(Classifier Free Guidance) 将噪音图 D 放大,之后再与噪音图 C 相加,得到噪音图 E。
第五步,将噪音图A 与噪音图 E 相减,得到一个新的图,这个图就包含更多 prompts 相关的信息。
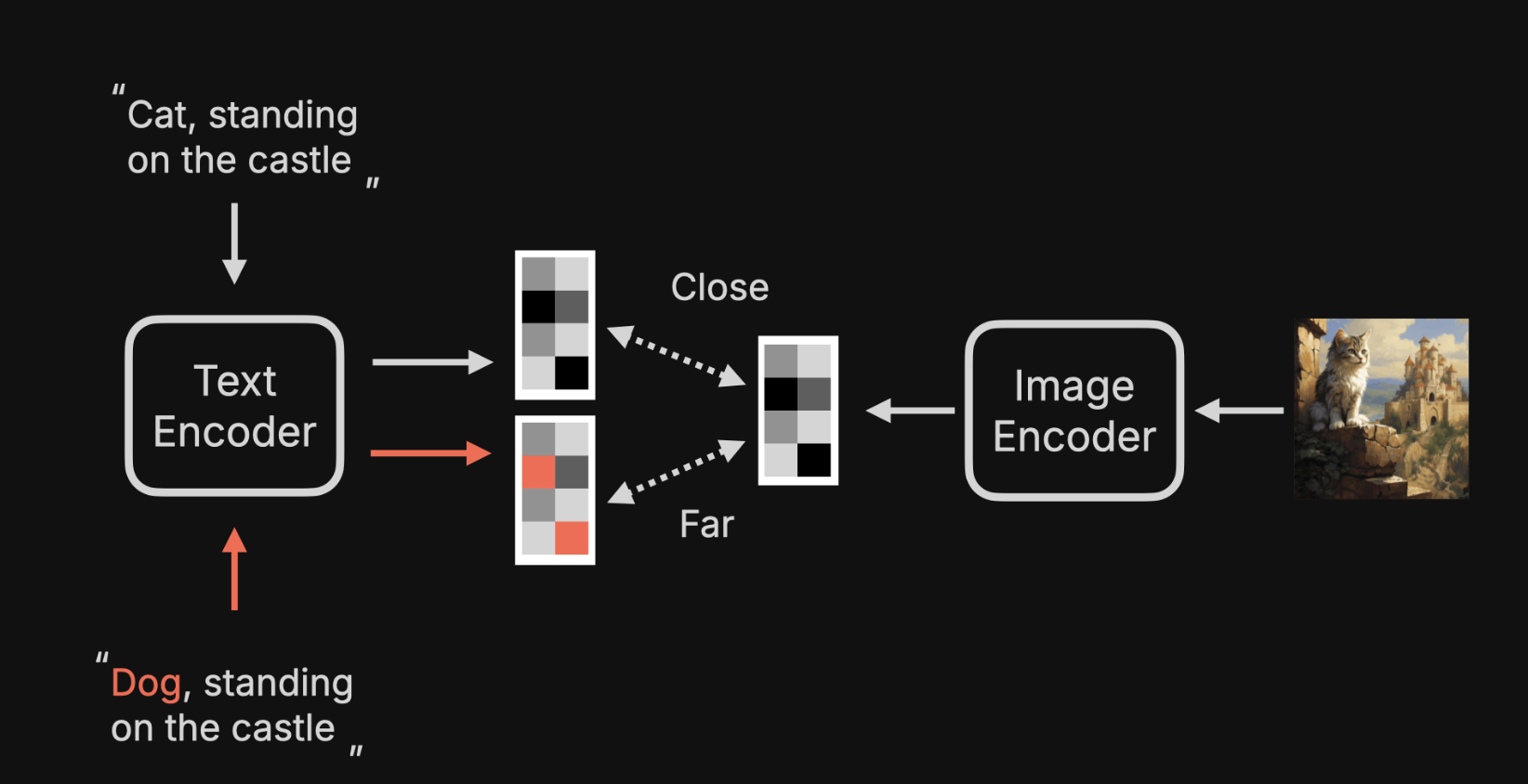
Text Encoder
最后回头再介绍下 Text Encoder。
不知道你有没有疑问:为啥输入一个 prompt 就可以生成相关的图片,甚至图片上还自动补充了没有提及的细节。
首先,有一个 CLIP Text Encoder,会将文本转化为一个特征向量。
然后, Image Encoder 会将图片也转成特征向量。
如果这两个向量越近,意味着这个描述,越接近图片的内容;反之越远,则越不相关。
模型会使用大量的带有文本标注的图片进行训练。
使用模型生成图片时,就可以根剧文本匹配上类似的图片信息了。
三、ComfyUI 工作流
打开 ComfyUI 后,可以看到这样一个图,第一眼完全看不懂这个是什么。
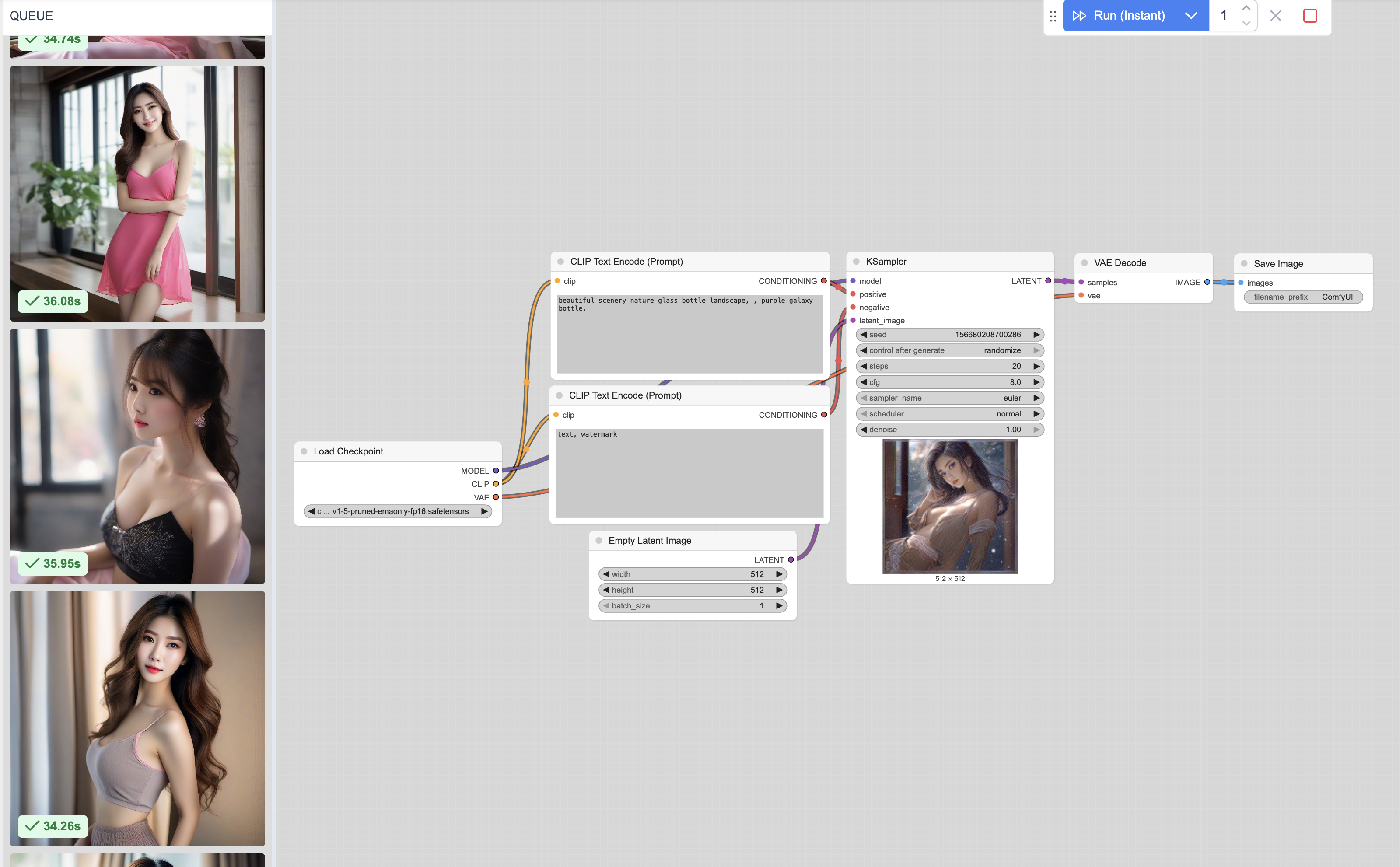
接下里我会介绍一下,这些方块与连线是什么,工作流是什么,这样有什么好处。
还记得上一小节介绍的 Ai 生图原理步骤吗?
之前曾提到过模型、prompt、初始噪音图片、噪音扩散、Image Decoder、图片显示等,就对应这些一个个方块。
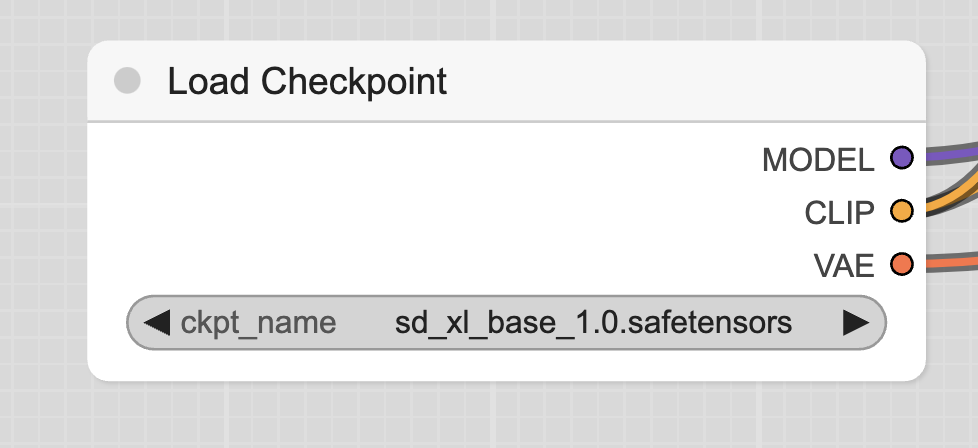
Load Checkpoint 用于加载模型。
两个CLIP Text Encode (Prompt),一个填写正向 prompt,一个填写负向 prompt。

Empty Latent Image 模块用于设置图片大小,不同模型有自己最适合的图片大小。

KSampler 是主要用于扩散计算的模块,输入是模型、正向prompt、负向prompt、Latent Image,剩余的都可以在这个模块内配置。
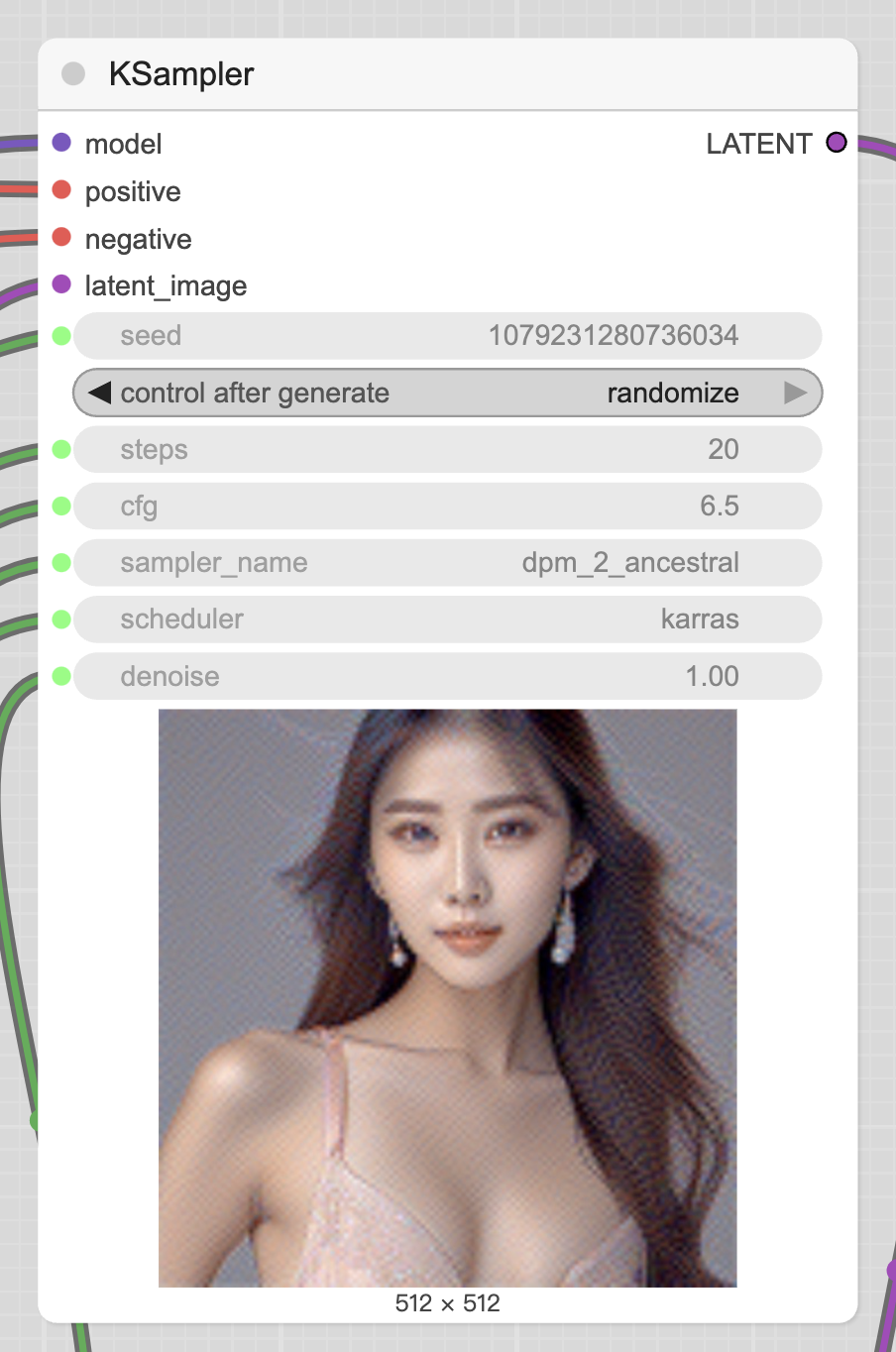
seed 是随机种子,用于控制初始噪音。如果 seed 保持不变,生成的图也会一模一样。
control_after_generate 用于控制每次生成图片后,seed 如何变化,氛围四种:randomize(随机)、increment(递增 1)、decrement(递减 1)、fixed(固定)。
step,控制步数,一般步数越大,效果越好。但也与模型与采样器有关,以后有时间我会分析具体该如何设置。
cfg,全称 Classifier Free Guidance,这个值设置一般设置为 6~8 之间会比较好。
sampler_name:采样器,可以理解为一种去噪算法,以后有时间了单独分享。
scheduler,也可以理解为去噪算法。
denoise 标识要增加杜少初始噪音,一般默认为1。
对于 sampler 和 scheduler 可能会有人有疑问,都是去噪算法,有什么区别呢?
sampler 算法,决定每次怎么选择噪音来去噪。
scheduler 算法,用于决定每次选择多少噪音。
VAE Decode,用于将目标向量转化为目标图片。

Save Image,预览与保存图片。
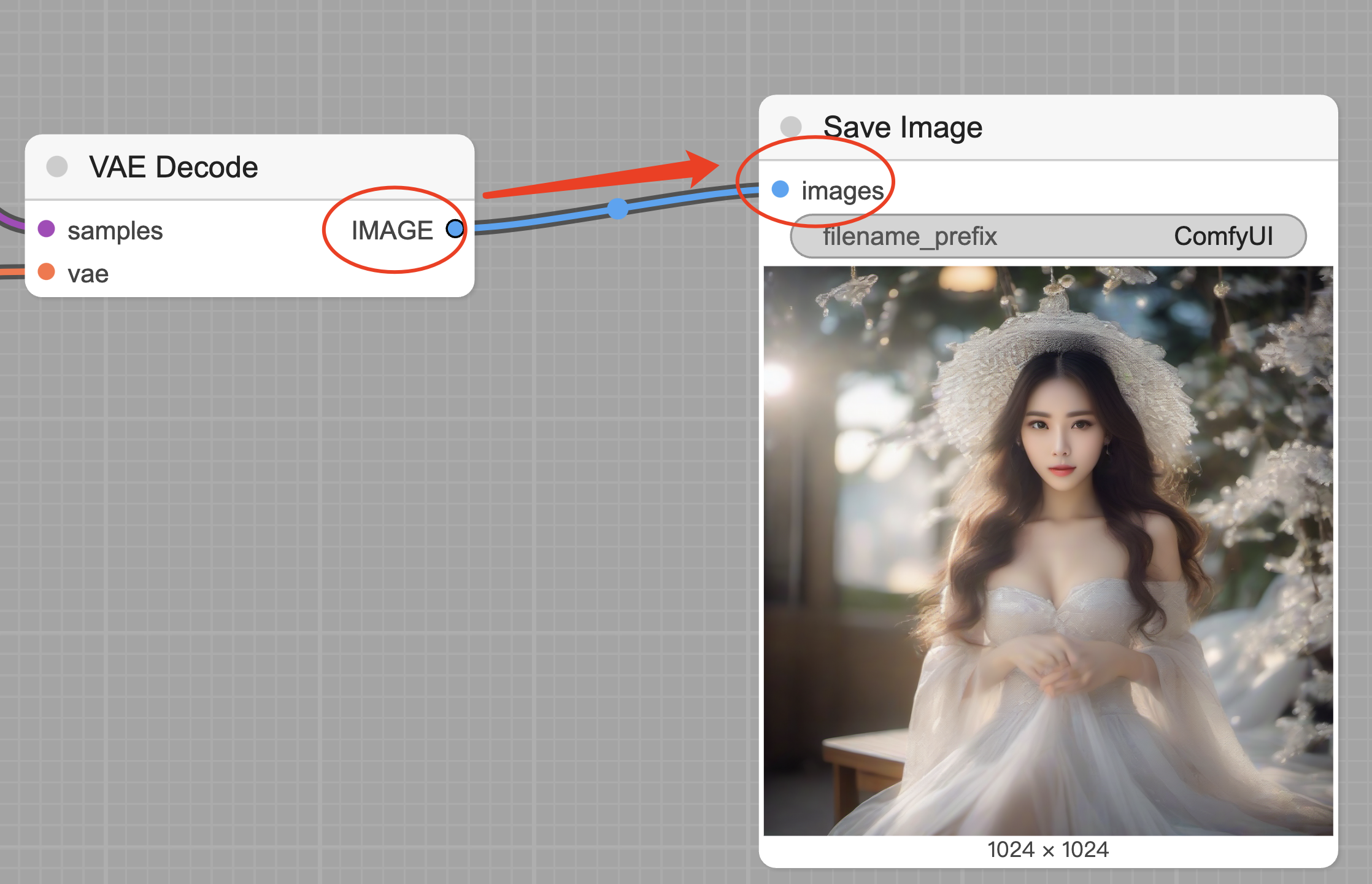
连线
如果你细心的话,会发现每个模块左侧和右侧都有连线,且连线是从左到右的。
这里连线有三个原则。
原则1:同类相连。
每个输入与输出是有类型的,只有相同类型的输出才能连到相同类型的输入上。
比如 Load Checkpoint 模块的第一个输出是 model,只能连到 KSampler 左侧的第一个 model 输入上,不能连到其他输入上,也不能连到输出上。
comfyUI 已经使用颜色来区分不同的类型了,而且连线时,只有可以连的地方才会高亮,所以大家不会误连的。
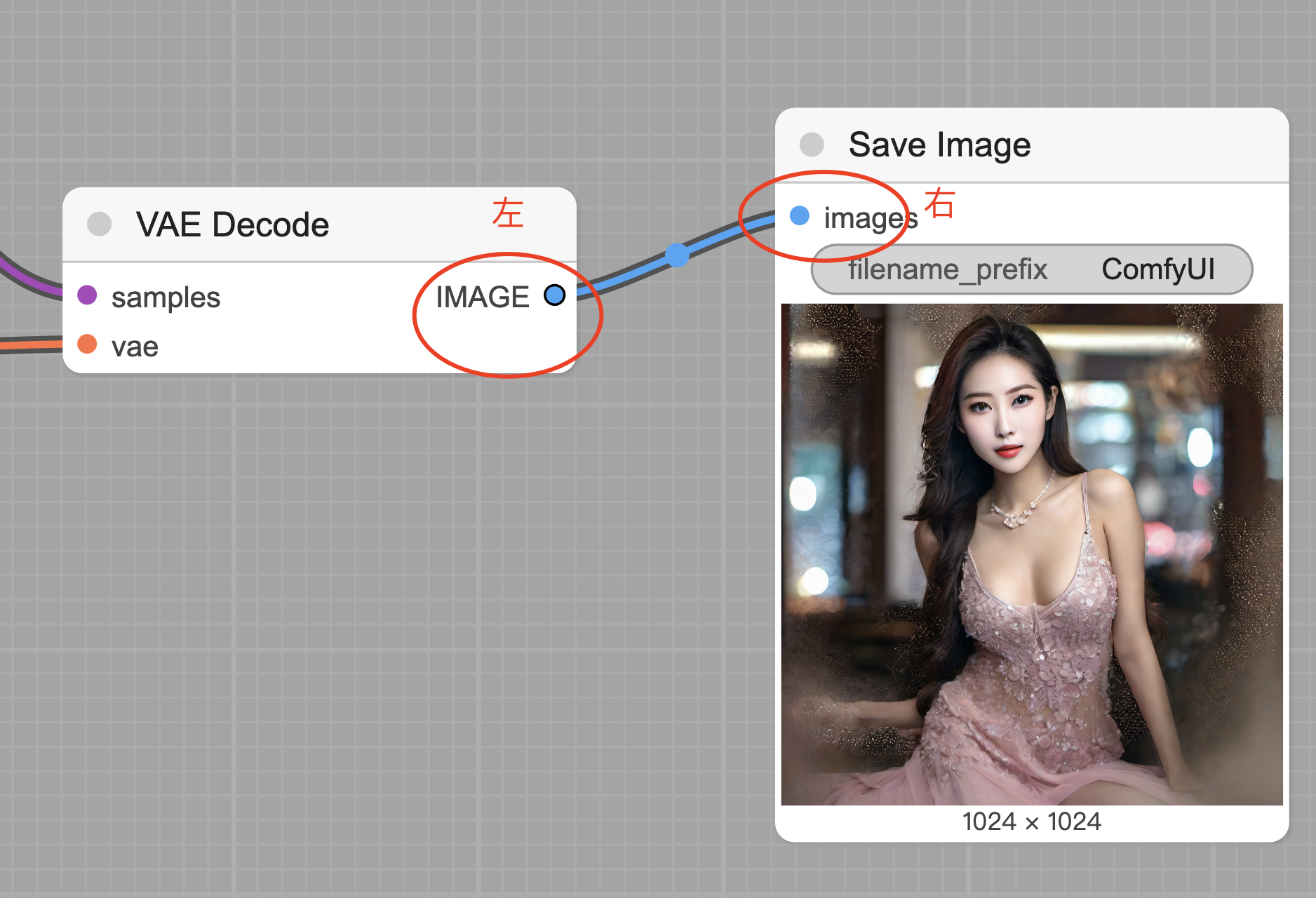
原则2:左进右出。
这个很容易理解,看图应该也能发现这个规律。
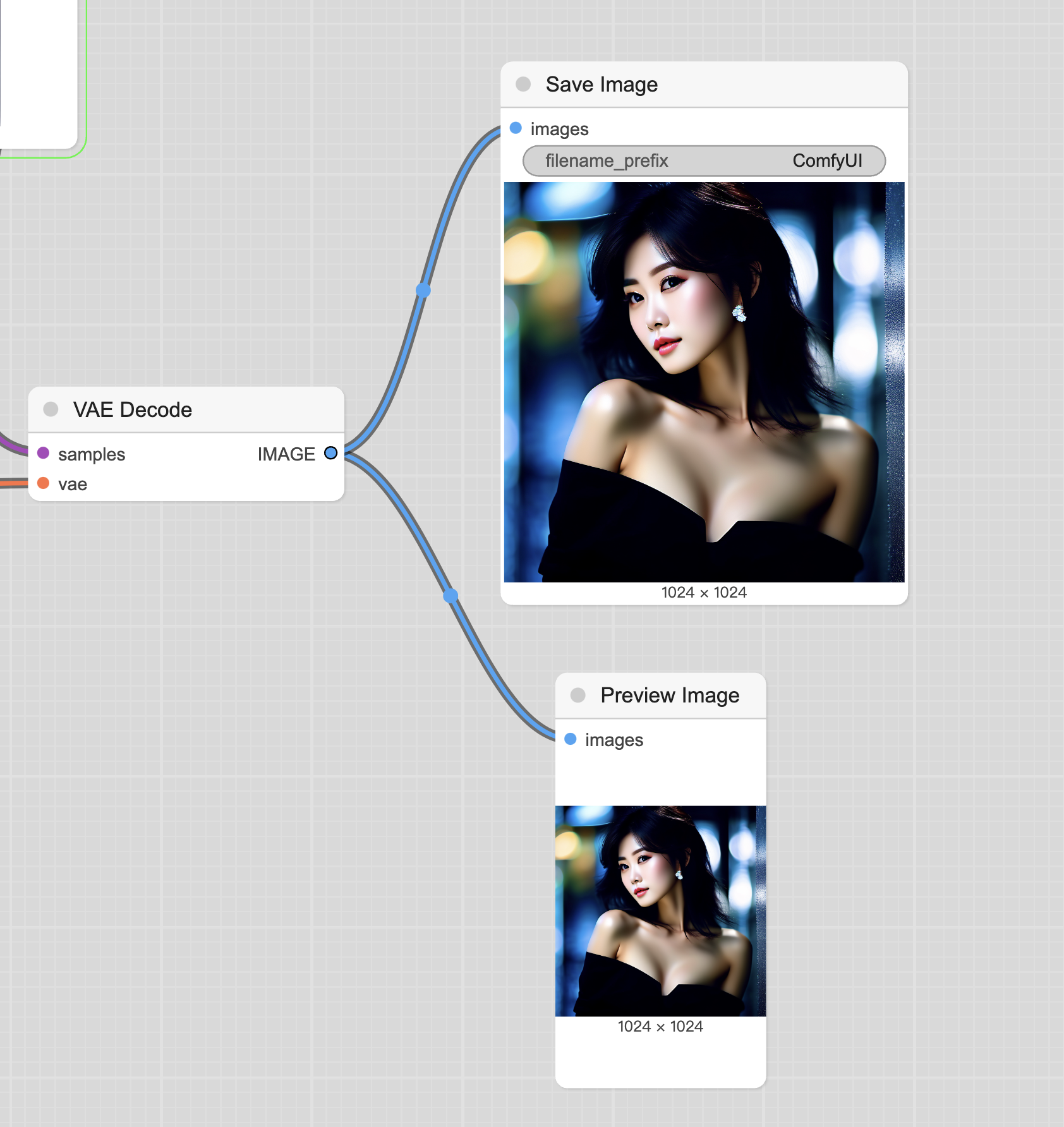
原则3:一进多出。
含义是每个输入点只能与另外一个节点的输出端相连,没法与多个输入相连。
这个也很容易理解,比如要输入宽和高,如果放在一起,怎么区分谁是宽谁是高呢?
每个输出端可以有多个线也很容易理解,比如图片生成了,一个线用于预览模块,一个线用于保存模块。
四、最后
了解 AI 生成图片的原理后,发现 comfyUI 就是生成原理的流程可视化,还是相当简单的。
接下来我还会学习 Embedding、LoRA、图生图、老图片修复(Upscale)、图片部分擦除、图片部分替换、图片扩充、ContorlNet 等等,到时候分享出来一起学习。
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号: tiankonguse
公众号ID: tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
