CSP-J/S 2025年一等奖分数线预测复盘
作者: | 更新日期:
我写了一个评测程序来预估分数线,现在对预测结果进行复盘。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
零、背景
之前,我在文章《CSP-J/S 历年一等奖分数线与2025年预测》中,仅使用历史数据,通过纯算法来预测了 2025 年的分数线。
后来,在《CSP-J/S 2025年一等奖分数线预测(跑代码版)》一文中,我介绍了我写的一个评测程序,通过它跑出了一个更具体的预估分数线。
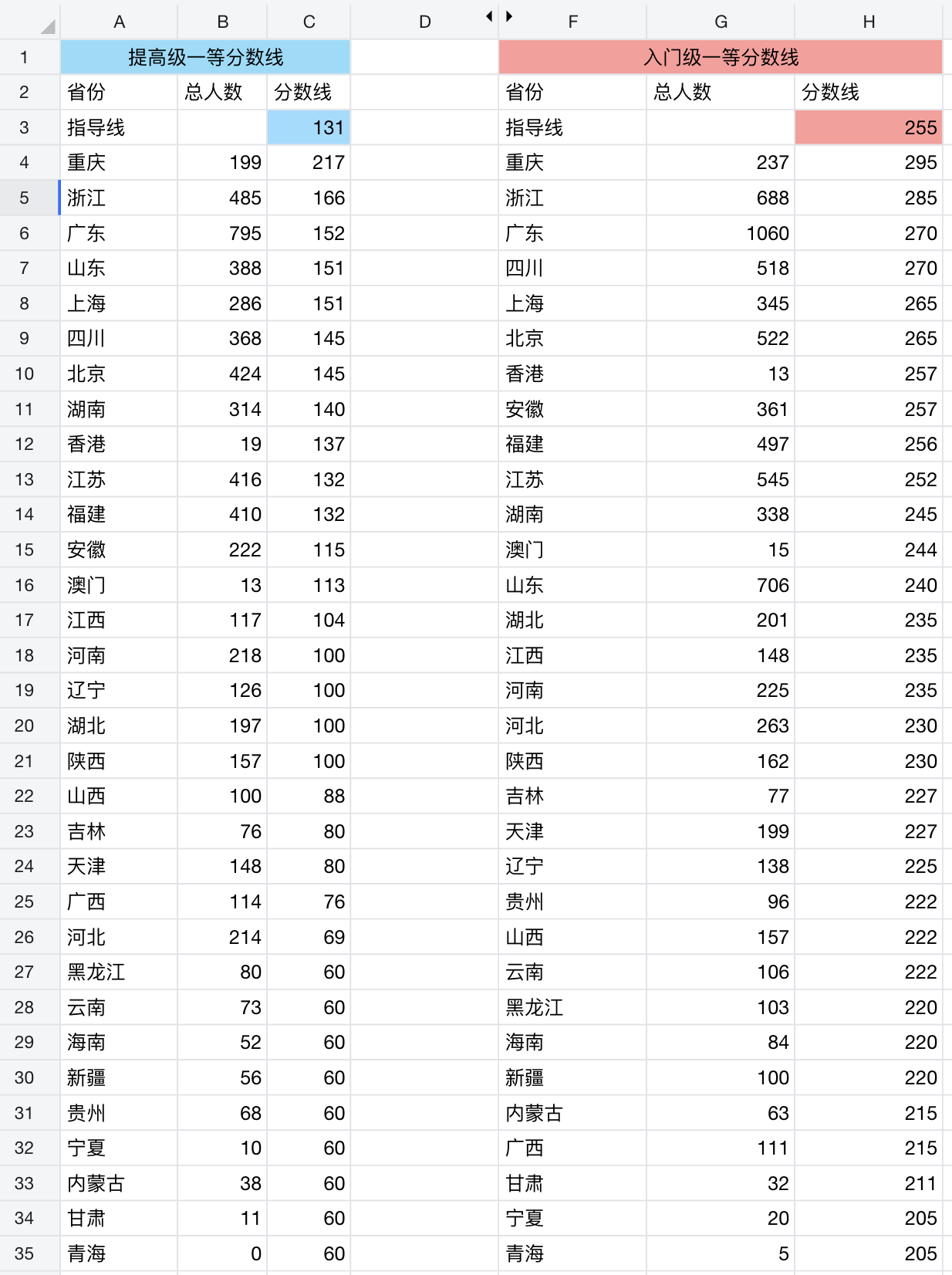
2025年11月14日,CSP-J/S 2025 的一等奖分数线公布了,指导线 J 级为 255 分,S 级为 131 分。
由于我通过代码跑出来的分数线与官方公布的实际分数线存在一定误差,因此,我写这篇文章来复盘一下。
一、评测程序简介
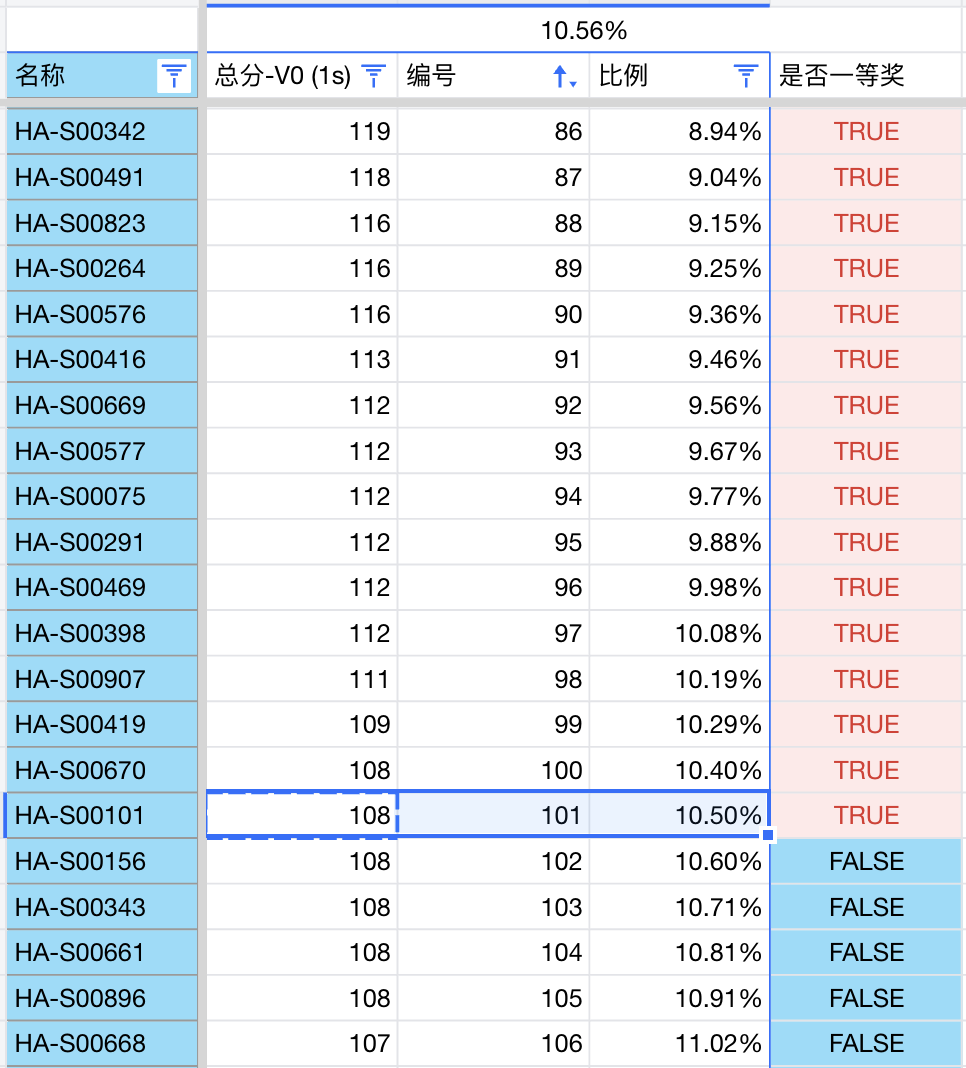
后来得知河南省的考生代码在网上有公开公示,于是我便下载了全部代码,重新跑了一遍评测程序。

在评测过程中,我遇到了各种问题,例如:
1)部分考生没有按要求创建题目目录。
2)部分考生没有将输出写入到文件。
3)部分考生使用 cerr 输出调试信息,导致输出混乱。
另外,在反复运行评测程序时,我也遇到了虚拟机磁盘被打满的情况。
原因是每个考生的代码都需要编译,编译后会生成大量的中间文件,而之前的程序没有自动清理机制。
基于这些问题,我对评测程序做了一些改进:
1)兼容考生未创建题目目录导致的报错问题。
2)删除测试生成的临时文件,避免磁盘空间被过度占用。
3)新增调试信息开关,可以选择性输出。
4)改进参数解析,使程序更便于使用。
5)优化批量评测模式,可以控制任意批次的评测。
6)兼容考生未将输出写入文件的问题,避免日志刷屏。
7)支持设置程序运行超时时间,避免因机器性能差异导致的分数过低。
8)兼容考生使用 cerr 输出调试信息,避免日志刷屏。

现在运行程序,可以看到更完整的参数说明,使用起来更加友好。

PS: 评测程序的源码已上传到网盘,有需要的朋友可以关注公众号,回复 CSP-2025 获取。
二、评测结果分析
我们先来看一下官方的评测结果。
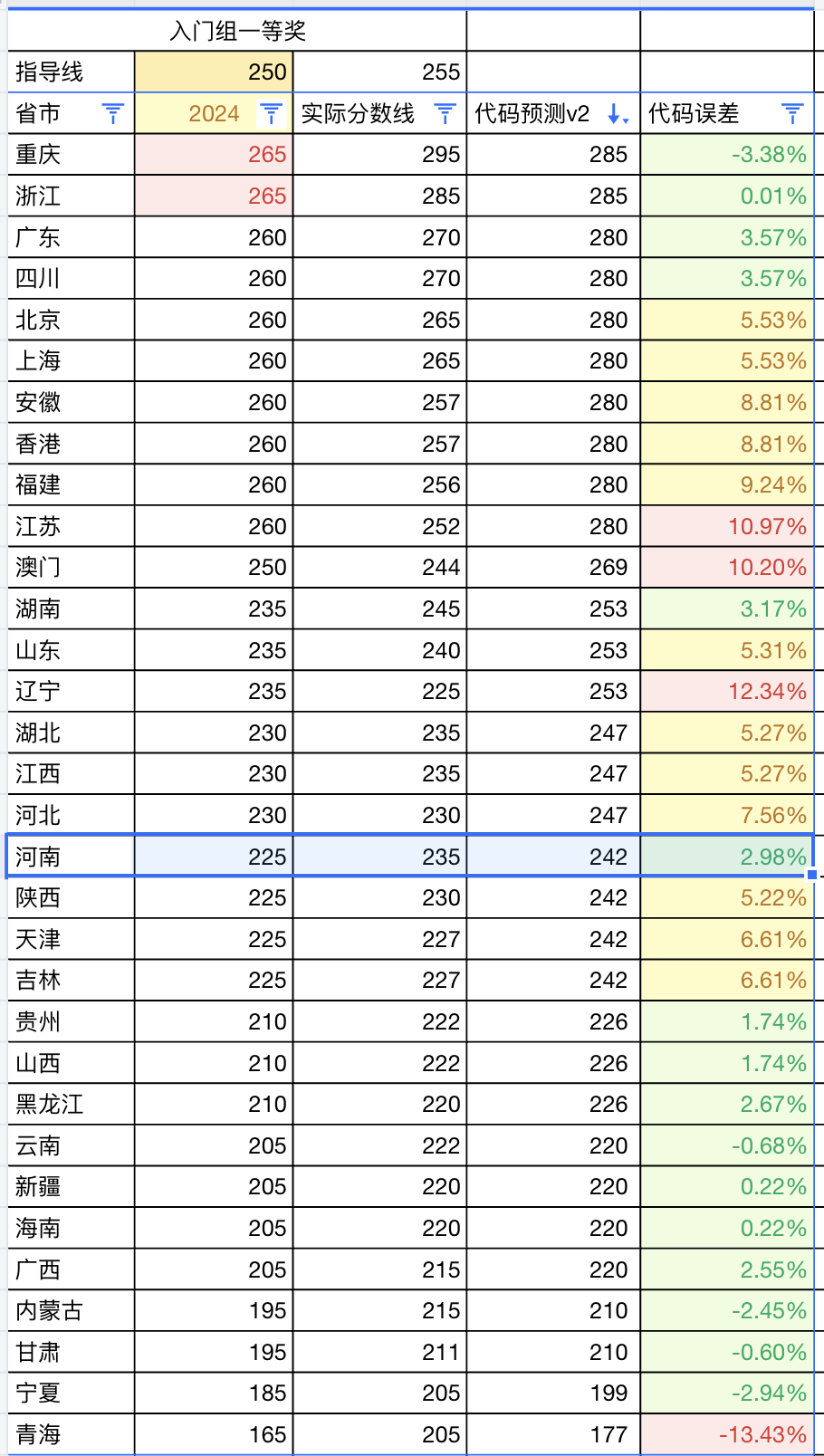
入门级(J组)分数线最高的是重庆,高达 295 分。
提高级(S组)分数线最高的依然是重庆,为 217 分。
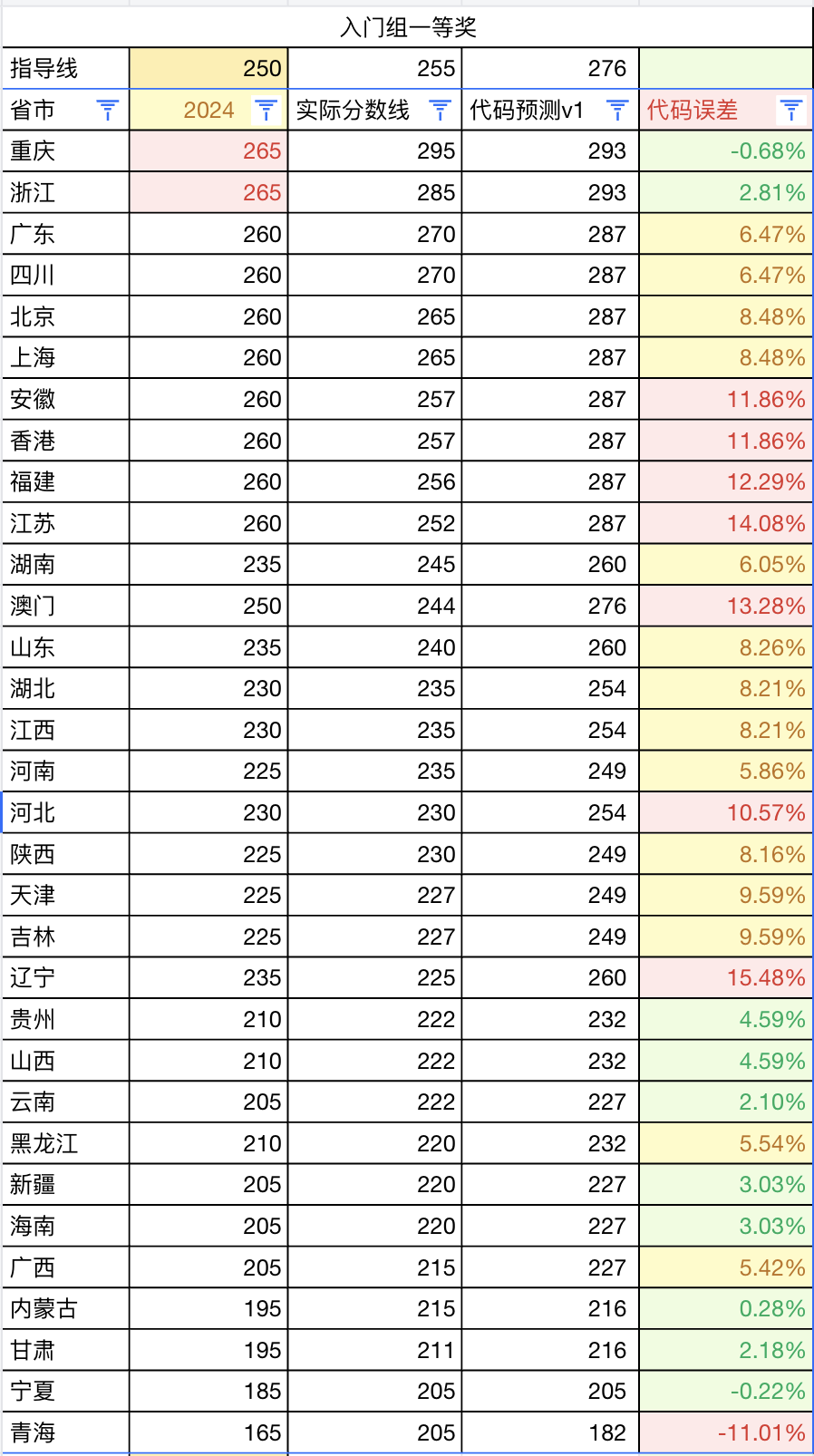
对于入门级,我的代码预测误差相对较小。
这里我将误差比例划分为三个等级:5%以内、5~10%、10%以上,数据如下:
- 误差在 5% 以内 的有 10 个省份:宁夏、内蒙古、重庆、云南、甘肃、浙江、新疆、海南、贵州、山西。
- 误差在 5~10% 之间 的有 14 个省份:广西、黑龙江、河南、湖南、广东、四川、陕西、湖北、江西、山东、北京、上海、天津、吉林。
- 误差在 10% 以上 的有 8 个省份:河北、青海、安徽、香港、福建、澳门、江苏、辽宁。
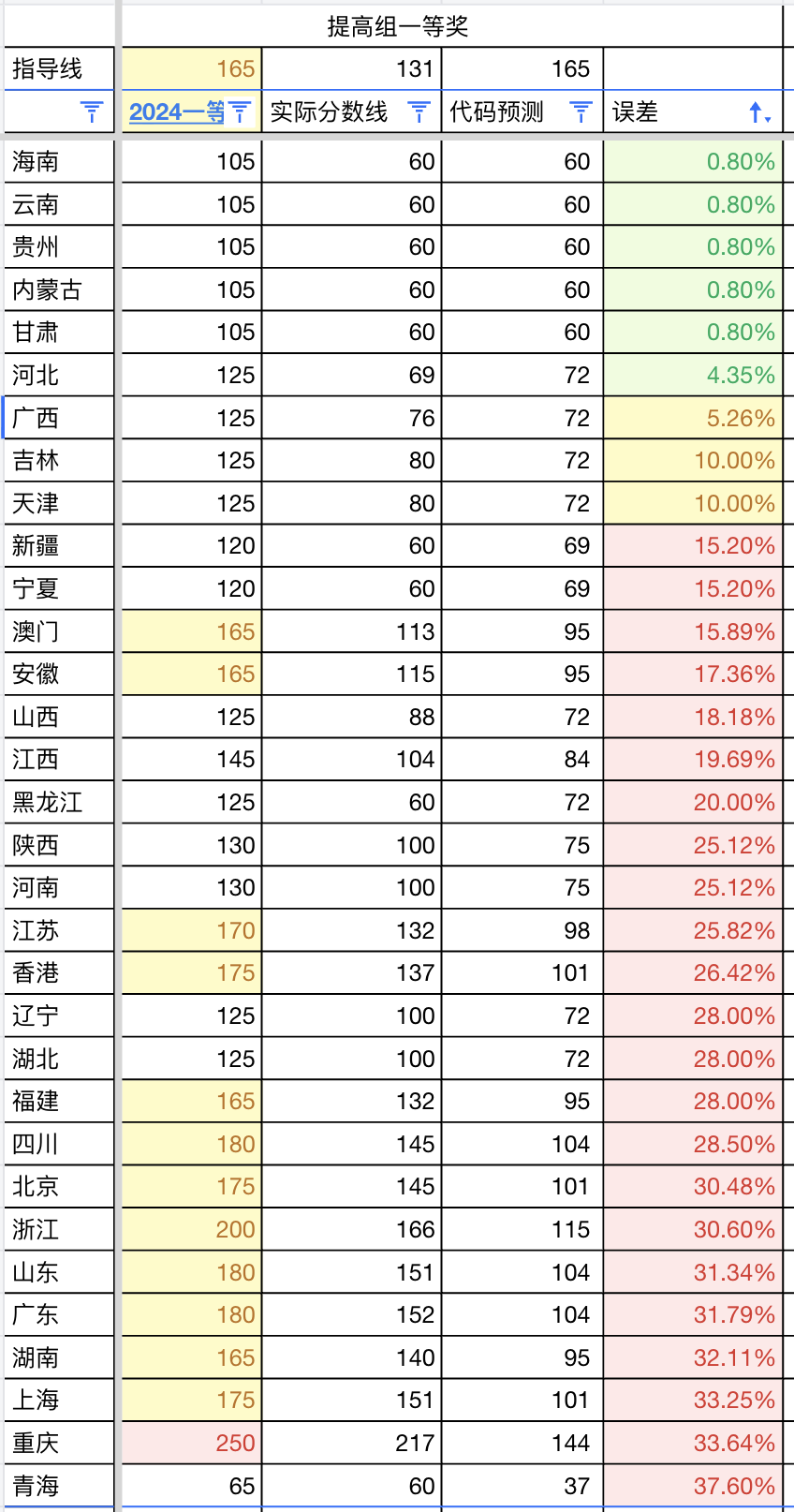
而对于提高级,误差则显著增大。
误差在 5% 以内的只有 6 个:海南、云南、贵州、内蒙古、甘肃、河北。
误差在 5~10% 之间的有 3 个:广西、吉林、天津。
其余 23 个省份的误差都在 10% 以上,其中 17 个省份的误差甚至超过 20%,更有 8 个省份的误差超过 30%。
三、误差原因分析
针对这个巨大的误差,我分析了以下几个原因:
1)评测性能限制:我的评测是在单机上进行的,一次同时评测 10 位考生,机器性能有限,可能导致部分考生的代码因超时而被大幅扣分。
2)分数线规则简化:我之前直接按省内考生排名 20% 来划定分数线,这个模型过于简化,是导致误差的主要原因。
尤其是第二点,官方的一等奖分数线计算规则非常复杂,它主要由三部分构成。
前提条件:官方会先制定一个全国认证基准线。
规则A:基于省平均分和参赛人数
规则A的名额计算公式为:((各省第二轮平均分 - 全国一等认证基准线) × 0.1% + 20%) × 各省第二轮提高级人数。
可以看到,我的预测模型忽略了“省平均分”与“全国一等认证基准线”的差值影响,只使用了 20% 这个固定的基数。
如果一个省的平均分低于全国基准线,那么该省的名额比例将会低于 20%,导致分数线被动提升。
规则B:基于第一轮参赛总人数
规则B的名额与各省第一轮的参赛人数 P 相关,分为两段计算。
- P < 10000 人时:名额为
(7843 - 全国规则A名额总和) × 各省第一轮人数 / 全国第一轮总人数。 - P >= 10000 人时:每增加 1000 人,额外增加 1 个名额。
由于我没有各省第一轮的参赛人数和全国总人数等数据,所以之前的预测也忽略了这部分。
现在反思,这部分数据其实可以使用上一年度的获奖人数来近似估算。
全国规则A的总名额也可以用类似方法近似估算。
这样,就可以将规则B也纳入模型中。
理论上,考虑规则B后,名额会增多,从而使预测的分数线降低。
规则C:基于第一轮晋级第二轮的比例
假设某省第一轮晋级第二轮的比例为 M,规则C同样分段计算:
- 0 < M < 20%:名额为 0。
- 20% ≤ M ≤ 80%:名额为
((M - 20%) / 5%) + 1。
简单来说,省晋级比例 M 每比全国最低的 20% 基线高出 5%,就会获得一个奖励名额。
PS:官方的文字介绍是每高 10% 奖励 1 个名额,但公式里是每高 5% 奖励 1 个,不知道最终是按哪个来计算的。
但无论哪种情况,规则C都会增加名额,使分数线降低。

综上,总名额的计算公式为 A + B + C。
如果只考虑规则A,当省平均分较低时,名额会减少,分数线会提升。
如果再考虑规则B、C,名额大概率会增加,分数线会相应降低。
对于规则B和C所需的数据,后续我会尝试收集历年数据。如果当年数据缺失,就使用前一年的数据来近似计算。
四、重新预测与分析
现在,我仅考虑规则A,并以河南省的数据为例,重新进行评测。河南省入门组(J组)的预测获奖比例约为 15%,对应的分数线为 242 分。
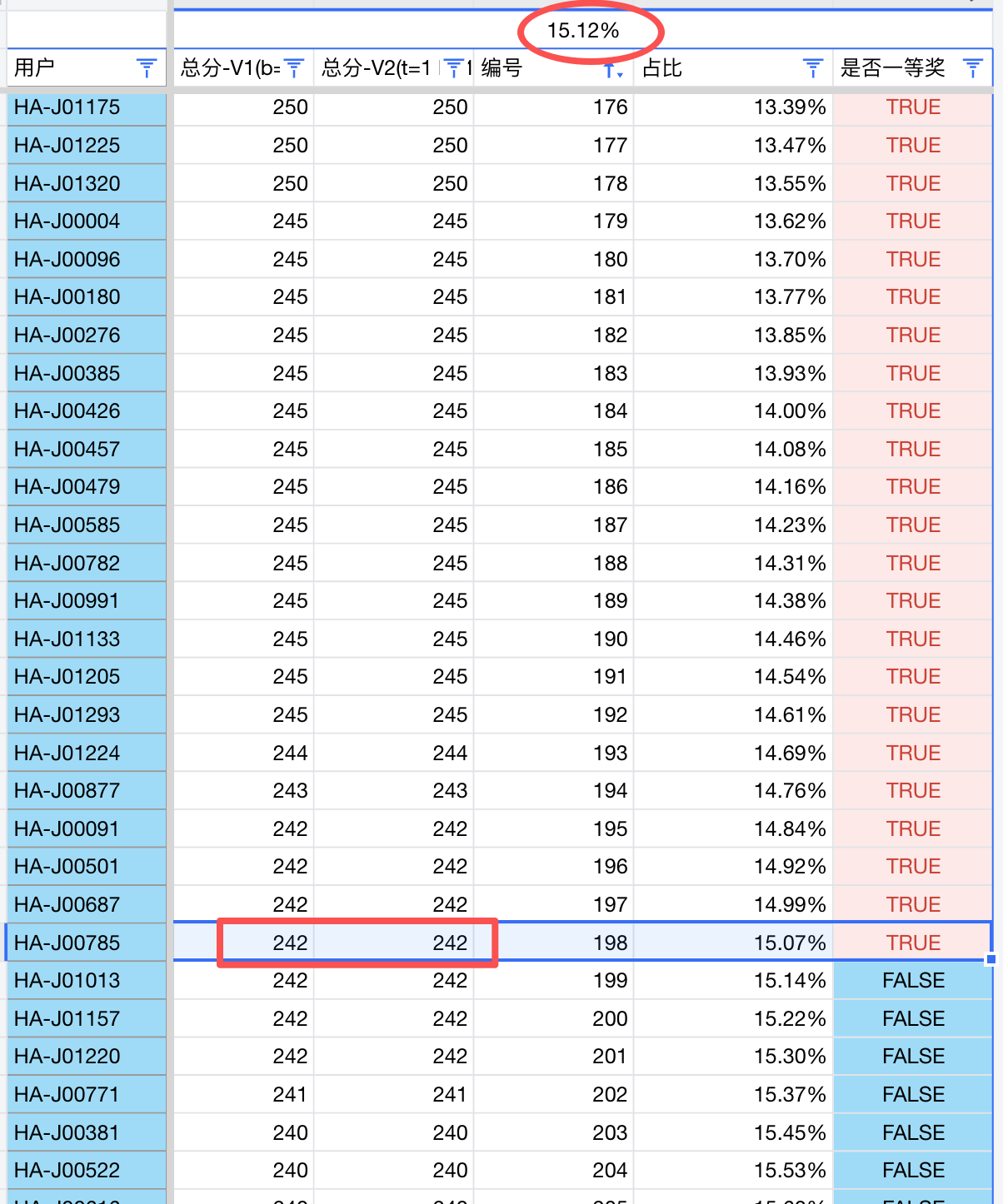
基于河南省的这个预测分数,再结合 2024 年各省一等奖的历史分数线,我推导出了 2025 年各省的新预测分数线,结果如下:
这次预测的准确度有了显著提升。
对于河南省提高组(S组),预测的获奖比例约为 10%,对应的分数线为 108 分。
从结果来看,分数线排名靠前的 8 个省份,误差基本在 5% 以内;而排名靠后的省份,误差则逐渐增大。
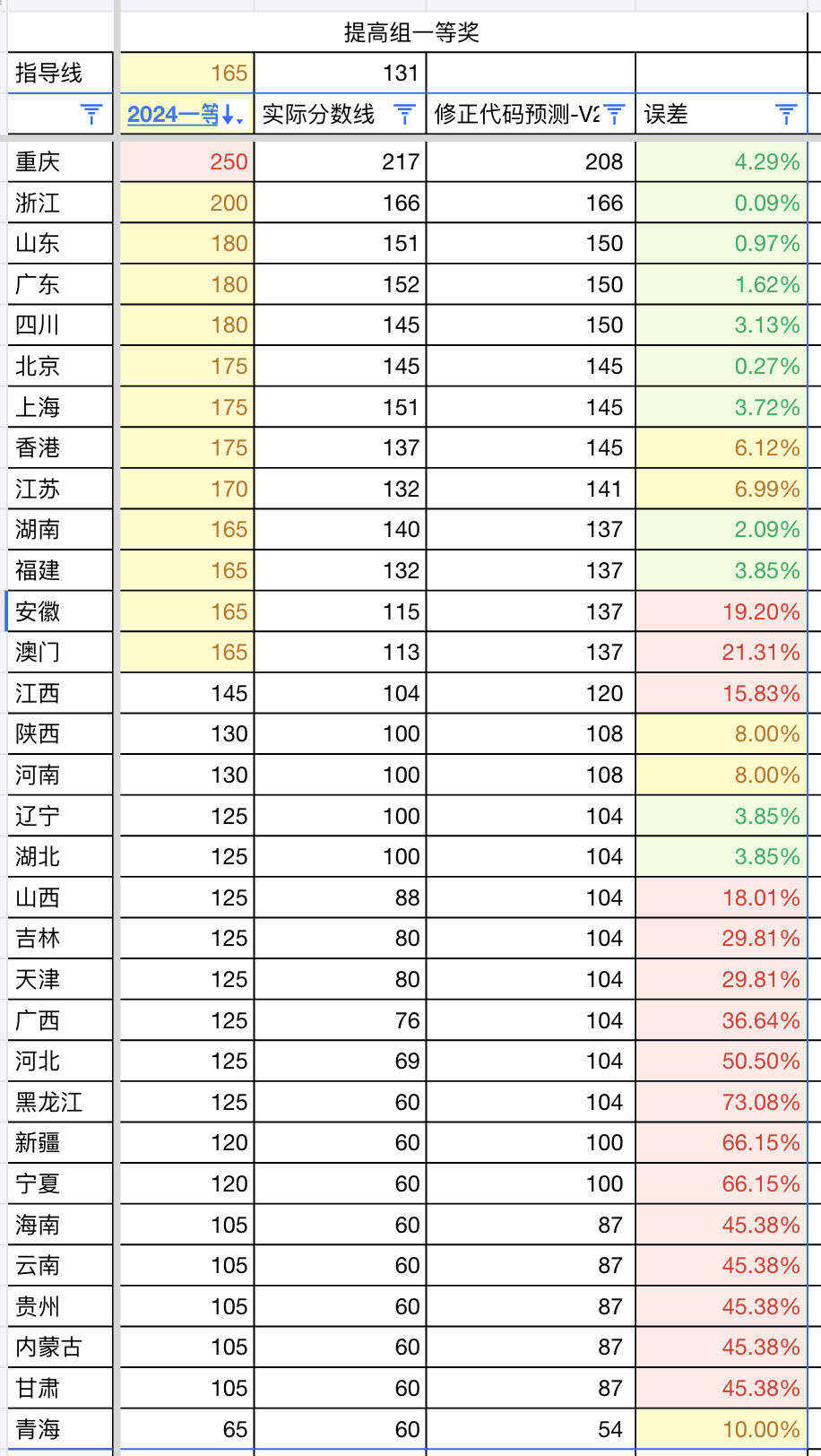
总的来看,仅增加了规则A的考量,误差在 10% 以内的省份数量就从 9 个提升到了 16 个,模型的准确性有了很大改善。
五、总结与展望
最初,我的预测模型固定使用 20% 的比例来计算名额,导致预测的分数线普遍偏低。
在本次复盘中,我加入了官方的规则A,模型的准确度得到了显著提升。
但我们也能看到,依然有不少省份的预测误差较大。
我认为,这部分误差主要是由于尚未考虑规则B和规则C所致。
下一步,我将研究如何获取更精确的第一轮和第二轮参赛人数等数据,从而构建一个更完善的预测模型。
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号:tiankonguse
公众号 ID:tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
