定位高性能服务耗时抖动
作者: | 更新日期:
分享一个真实案例。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
一、背景
大概这周一(3月30日)的时候,有业务反馈拉我的服务失败率升高了。
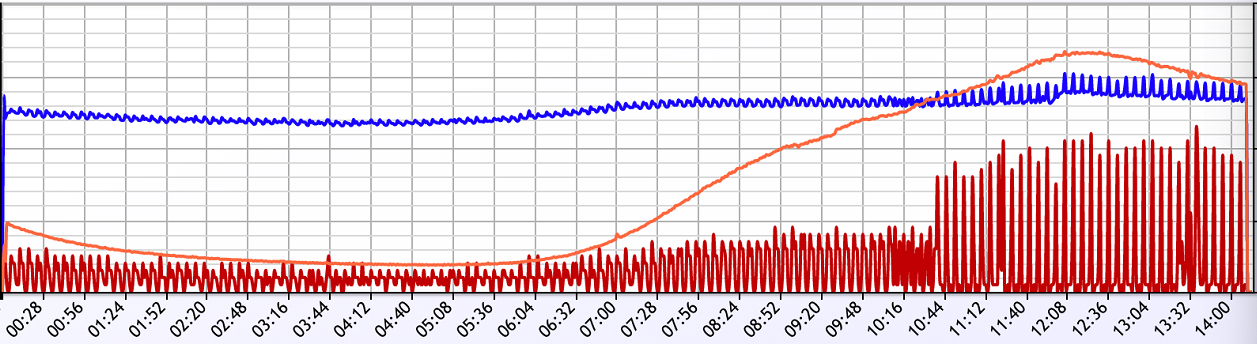
一看这个曲线,明显服务隔一段时间抖动一下,具体来说是 6 分钟抖动一下。
我便开始研究这个问题。
二、异地问题
业务问的是上午有什么操作,失败率比之前更高了。
我上午实际上正在发布服务,难道是我发布导致的?
最近在做中台,搞EP,上云,目前阶段服务不支持回滚,只好通过监控分析问题。
分析监控后发现平均耗时涨了几毫秒,这个是多城部署服务导致的。
于是我想起来了,最近支持了多个城市部署服务但是没上线,发布会使这个功能生效。
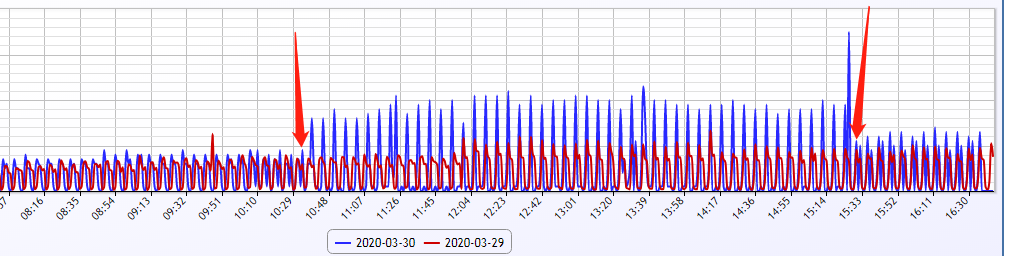
于是将其他城市的服务下线,耗时恢复到了上午发布之前的状态。
但是这个状态也是不正常的,所以还需要找时间定位一下。
三、排除发布变更
由于我还在忙其他项目,将问题恢复至和以前一样后,就没继续定位了。
而周三(4月1日)业务再次反馈问题,我只好挤出时间来看看这个到底是什么导致的。
上面提到我周一有发布,难道是发布导致的?
对比一下 git 的变更记录,我只做了一个操作,切换旧监控系统至最新的监控系统。
难道监控系统有问题?
恰好我的服务有一个开关,支持一键关闭监控系统。
关闭监控系统后,发现问题依旧存在,于是排除发布导致的问题。
定位了一个小时后,有其他事情只好放弃定位。
四、分析架构与监控
周四(4月2日)给老板申请集中时间定位这个问题。
这个问题很诡异,很容易猜想是依赖的下游抖动导致的。
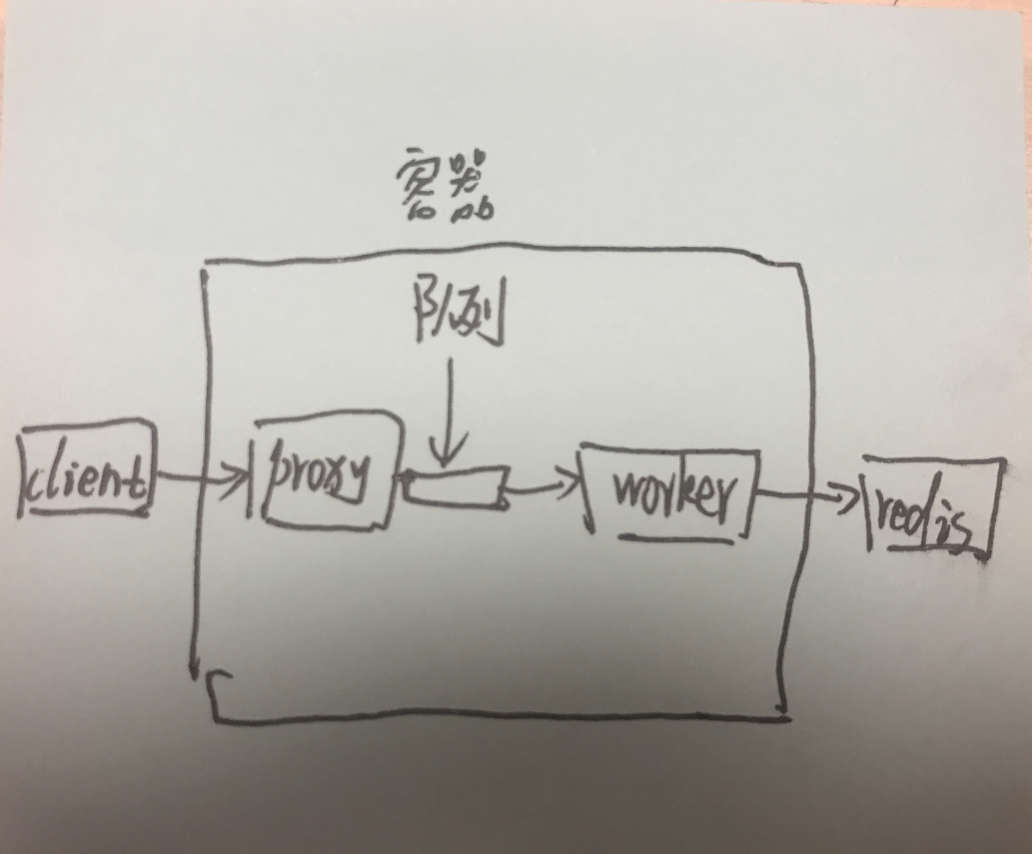
服务架构简化后如上图。
所有 client 的请求会先到一个 proxy,proxy 把请求写入到队列中。
我的服务就是 worker 会从队列中读数据。
逻辑也很简单,一个异步的网络操作去下游读数据,读完简单计算回包。
看我的服务平均耗时,确实和业务一样 6 分钟抖动一次,确认我的服务有问题。
看读下游服务的平均耗时,一样是 6 分钟抖动一次,很容易怀疑下游服务有抖动。
此时我有另外一个压箱底的监控,队列平均等待时间。
没想到队列平均等待时间也有相同的抖动,6分钟一次。
我们的服务都是协程异步实现的,CPU负载也不高,理论上队列等待时间应该是平滑的。
队列等待时间较高,说明协程中有个计算很好性能,卡主CPU了。
那卡在哪里了?
这就需要另外一个压箱底的监控了。
五、函数执行耗时
上面提到,我的服务是异步的。
异步是什么意思呢?
就是根据网络操作,将一段完整的处理流程切分为几段。
每一段是业务计算代码,属于纯CPU计算。
计算后会异步的进行网络操作(此时可以处理其他请求),网络操作后再进行CPU计算。
那我就实现了一个打桩函数,统计了很一段CPU计算逻辑的执行耗时。
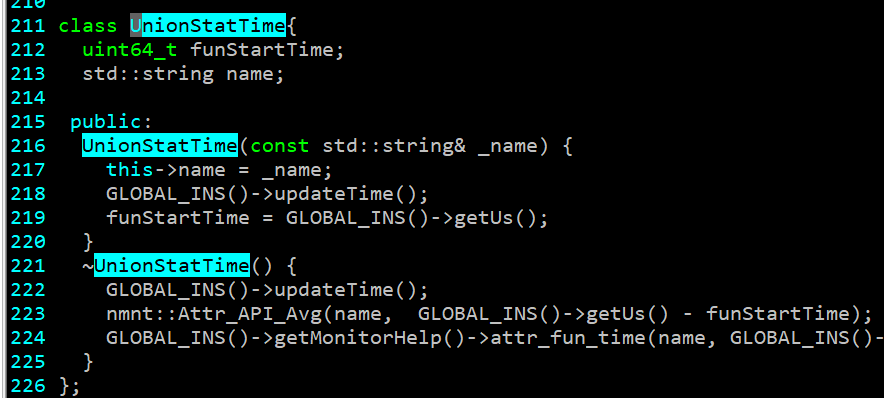
代码大概如上,然后在每个函数入口定义一个对象的变量,就会自动统计每个函数的耗时。
经过这样的监控,我大概找到了具体的函数。
然后在函数中再使用二分的方法分别进行代码段打桩统计,最终发现是一个配置服务的锅。
六、配置服务
说起来,年前上云的时候,我切换了配置服务中台。
而定位到配置服务有问题后,只好找来源码进行阅读。
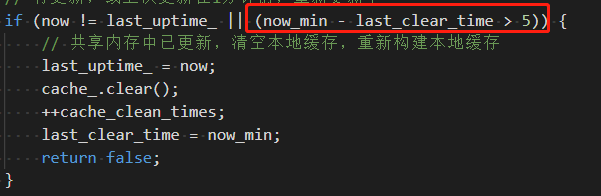
然后终于找到神奇的数字 6 了。
大于 5 分钟情况一次全量配置,那就是 6 分钟了。
原来配置中心做了内存级别的缓存,为了防止数据不更新,强制的隔一段时间清空一次全量缓存数据。
我的配置数据比较多,清空数据的时候就会非常消耗性能,此时 CPU 会被卡主,从而异步网络与队列的数据会被延迟处理甚至超时。
七、最后
这次定位问题用了不少时间,复盘一下是由于在做中台、上云、接入EP导致的。
之前实体机的年代,修改个地方,编译后就传到线上机器去了,可以两分钟验证猜想。
现在,修改个代码,要走分支流水线,10分钟过去了,再走个发布流水线,半个小时过去了。
这样反复修改结果地方,一天就过去了。
这次定位问题能够找到原因,是因为监控立大功了,队列耗时监控确定自身服务问题,函数或代码段执行耗时统计确定具体的问题。
这个方法应该很有用,分享给你们。
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号:tiankonguse
公众号ID:tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
