服务都异步化了,为啥批量请求耗时这么高?
作者: | 更新日期:
一个很多人不知道的知识点
本文首发于公众号:天空的代码世界,微信号:tiankonguse
一、背景
作为后台开发,大家都知道异步化的服务可以同步化服务处理更多的请求。
慢慢的,异步被神化。
低延迟、高并发、高性能等头衔成了异步化的优点。
可以异步到底解决了什么问题呢?
…
最近几年,不少产品都在做推荐,这就涉及到实时拉取大量的数据。
因此每隔一段时间,就会有业务反馈,自己的服务已经异步化了,为啥批量几百网络包拉数据耗时比较高。
这样的反馈者中不仅有职场新手,还有工作五六年的老司机。
所以还是有必要来聊聊这个话题。
二、同步服务
举两个实际例子,大家就可以知道同步服务的问题了。
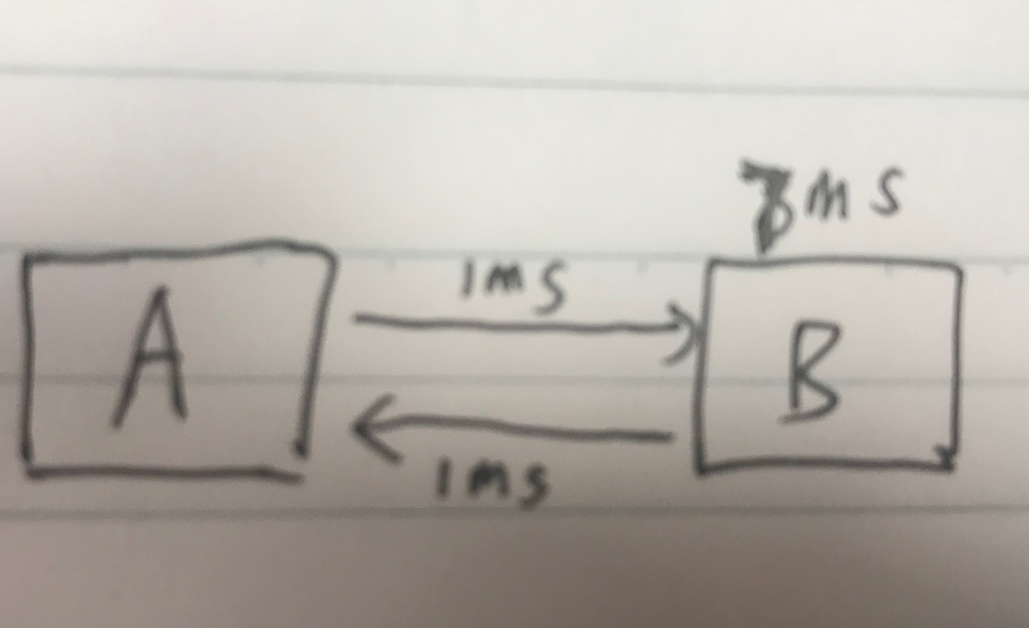
假设有一个客户端 A 和 服务端 B,A 调用 B 服务。
A 服务网络一次 1ms。
B 服务计算 7 ms。
A 服务拉倒 A 的数据后计算 1ms。
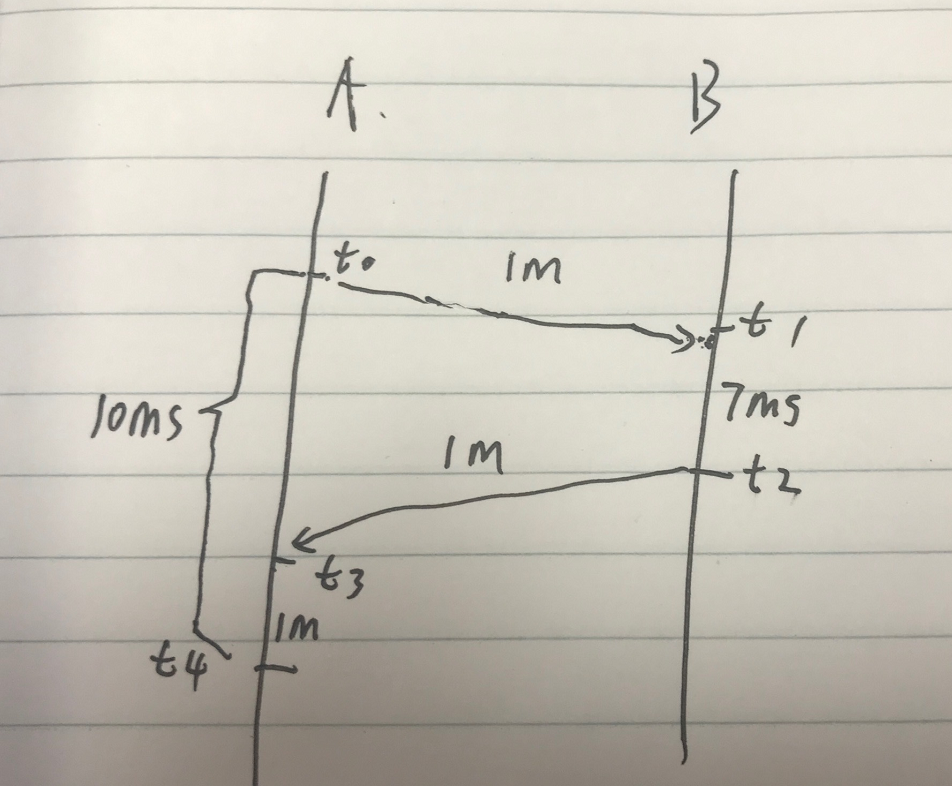
时序图如下,A 需要花费 10ms 才能处理一次完整的流程。
对于 A 服务,如果同步调用B服务的话,一秒最多可以调用 B 服务 100 次。
也就是说,A服务对外服务的话,不考虑其他损耗,每秒也是最多处理 100 个请求。
下面我们来分析一下 A 服务调用 B 服务的耗时。
假设 A 服务是均匀分布的请求 B服务,那就是每个 10ms 发一次请求。
这样的话,每个请求耗时都是 9ms,平均耗时 9ms。
由于 A 服务最高只能发出 100 个请求,所以 A 服务的 CPU 最高是 10%。
三、异步服务
前面可以看到,A 服务同步的调用 B 服务,每秒只能调用 B 服务 100 次。
如果我们把服务改造成异步化呢,即网络等待的时候,继续做其他事情。
这里的其他事情是发起其他请求。
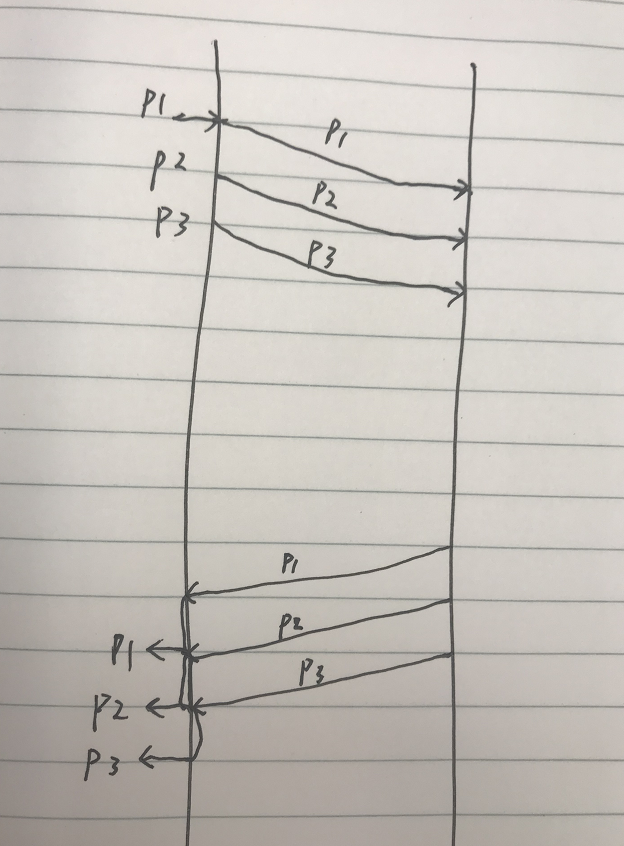
这里依旧假设请求的均匀分布的,即每1ms发出一个请求。
则异步化后的 A 服务最高可以发出 1000 个请求,即 qps 提高到 1000。
CPU 利用率也提高到 100%。
由此,可以看出来异步化的优点:对于同一个核,异步化可以提高服务的 qps 和 CPU 利用率。
…
有人会说,通过多线程或者多进程也可以提高 qps 或者 CPU 利用率。
是的,多进程或者多线程确实可以做到,但是有代价的。
还是当前文章的例子,同步的 利用率是 10%,那把 CPU 全部利用起来就需要开 10 倍的线程或进程。
而进程或者线程过多就会导致另外一个问题:进程调度问题。
当进程过多的时候,系统内核就会占用 CPU 资源,这使得 A 服务可用的 CPU 资源大大降低。
而异步化则没这个问题。
四、异步遇到批量
上面计算耗时的时候,是理想情况下,即请求的平均的。
而批量请求,则会是的请求分布极不均匀。
我们就以极端的场景来看看批量耗时会导致的问题吧。
假设 A 服务已经做到了异步化,每次是在一秒的同一时刻发出所有请求。
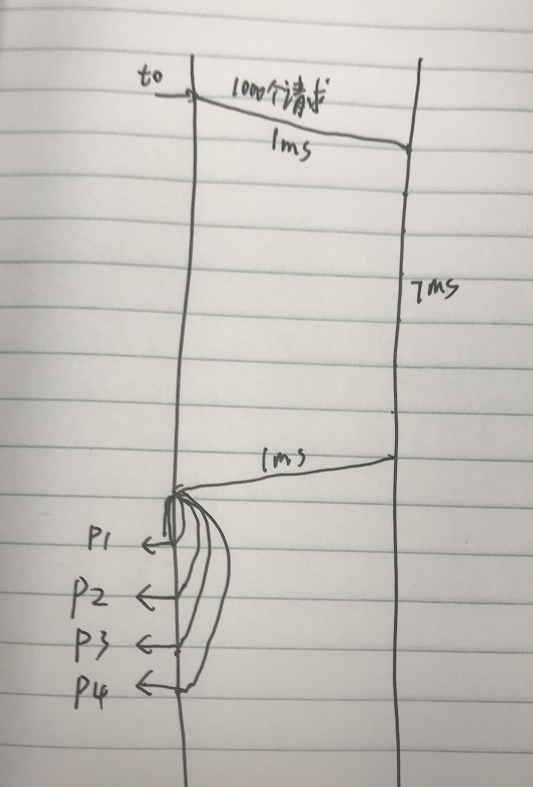
假设 B 服务很强悍,依旧是 7ms 返回了数据,也就是所有请求在同一时间都返回给了 A 服务。
A 服务拉到数据后,需要 1ms 的 CPU 资源来计算数据,使得其他数据需要排队处理。
等待时间依次是 1ms、2ms、。。。、999ms。
我们不妨设 qps 是 500,此时 CPU 利用率是 50%。
通过计算,就可以得到令很多人震撼的结论了。
10 + 0 +
10 + 1 +
10 + 2 +
...
10 + 499
= 259.5
服务异步化了,A 服务批量 500 个数据包拉 B 服务,平均耗时竟然变成了 259.5ms。
这也是为什么很多人会发出这样的疑问:我的 CPU 利用率不高,为什么耗时变得这么高?
五、最后
到这里同步、异步、批量应该都很清晰了。
同步会导致服务的 qps 上不去,CPU 利用率低。
同步+多线程强行提高 qps,会因为系统调度浪费掉很多资源,实际上还是 CPU 利用率并不高。
异步服务可以轻松的提高 qps,充分提高 CPU 利用率。
异步服务里批量请求时,如果请求后对数据包做了 CPU 密集计算,则会影响批量请求的网络耗时。
当然,聪明的你肯定发现了,这里服务调用耗时的计算方式不合理。
回包后的数据计算耗时不应该当做 B 服务的耗时。
不过现在的 RPC 框架都是这样干的,普通开发不知道这件事罢了。
思考题:你怎么看待这个问题呢?
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号:tiankonguse
公众号ID:tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
