春节期间我的服务出了三次故障
作者: | 更新日期:
两次命中墨菲定律,一次命中黑天鹅事件。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
零、背景
近一年我们成立了一个团队,一起重构了我之前负责的服务。
在服务上线的第一年,经历的第一个春节,一下就出现三次故障。
进行回顾与思考,从重构的角度来看,有两个故障算是与重构有关(重构后发生),一个故障与没有重构有关(未重构发生)。
而从上帝视角来看,其中两个故障命中墨菲定律(人为可以避免),一个故障命中黑天鹅事件(无法避免)。
下面来看下这三个故障吧。
一、流量暴涨故障
春节回家之前,我心中就在担心直播流量暴涨服务是否可以支撑住的问题。
如果是往年,我不会担心这个事情。
因为往年运行的是旧服务,性能我已经进行了全方位优化,每年都可以支撑住,已经稳定运行四五年了。
而今年,服务重构全部切换到最新的框架。
虽然新服务已经运行差不都一年了,也经历不少大流量直播。
但是最后一个春节直播还没经历,我心中依旧没底。
我们的服务支持区分SET物理来隔离各个业务的流量的。
另外,还支持关键时候,快速把一个 SET 的机器加入到另外一个SET,从而起到快速扩容均摊与导流的目的。
所以,为了保险,我决定在回家的前一晚,把其他SET的机器加入到直播SET。
那一晚上我还规划了其他几个事情,比如阅卷,计划一起处理了。
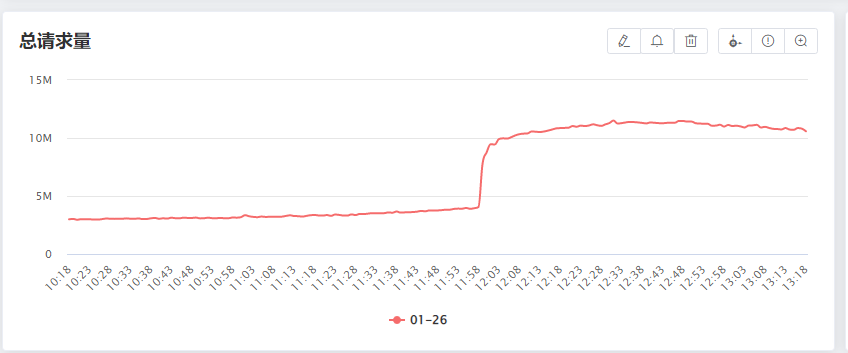
结果那天出现一个意外事件,有个业务流量突然暴涨,沟通后得知突然上线了新功能,年前要全量。
目前他们这个功能正在灰度,流量已经翻了 1 倍。
预计全量后,流量会翻 8 倍。
于是那一晚各种 SET 调整与申请资源扩容,直播的事情和阅卷的事情都没时间处理,给遗漏了。
担心的事情还是发生了,假期第一天,直播的流量暴涨,服务扛不住了。
虽然新服务接入了最新的 devops 技术体系,但是容器平台过年前就通知没资源了。
PS:这也是为啥我规划的是均摊流量,而不是扩容。
还好,直播的时候项目的人盯着这个事情。
收到反馈后,第一时间使用备用资源池给服务扩容。
运维扩容了一批机器,项目的同事也扩容了一批机器。
同一时间,我不在电脑上,电话指导同事加入其他SET的机器,进行均摊流量。
结果同事没权限,于是我手机 VPN 亲自操作,也成功加入其他机器。
事后,发现这几个操作时间点很接近。
运维扩容了第一批机器后,问题就得到解决。
我操作完成时,晚了几分钟。
如果我指导同事时没遇到权限问题,可能就是这一步提前解决问题了。
事后思考,有下面几个总结。
1、TODO LIST 继续使用起来,记录下要做的事情,以及标记重要性。隔段时间需要检查一遍。
2、权限梳理:梳理所有服务的权限,需要加上项目组所有人。
3、容量规划:告知所有业务,流量会上涨时,提前同步给我们,我们好提前扩容,否则我们不做保证。
4、过载保护:旧服务做了各维度全方位的过载保护,而新服务不具备任何过载保护功能。需要补上。
二、数据不更新故障
假期中间的时候,某天晚上我正在外面逛商场,老婆还在买东西。
突然收到同事的一个电话,问我:有个问题,你知道吗?
我说:不知道。
同事说:系统的数据不会更新了。
于是,我就电话指导同事,进行一些简单的操作,来排查是什么原因。
之所以要进行这样排查,是因为我们这个系统在重构切换,只剩下一个缓存更新模块待重构切换了。
恰好这个缓存更新模块隔几个月就会出一次问题,需要时间重置来解决。
记得春节回来之前,让另外一个同事进行时间重置了,理论上几个月后才会发送问题的。
指导同事排查的结果竟然是:不是之前的问题,原因未知。
不管是不是这个问题,先拉个会议,问问那个同事春节前是否进行时间重置。
得到的答案是进行时间重置了。
此时,就处于僵局了。
线上的服务没有做任何操作,那只能采用万能的方法来试试:重启服务。
一个同事重启了一个机器,过了一会,说看监控貌似没恢复。
我一听,没办法了,先退出会议,收拾东西,赶紧往家里赶。
到家后,我打开电脑,第一件事就是无脑把所有服务重启一遍。
刚重启完,同事说之前他重启的那台机器正常了。
我说:所有机器我都重启了,那现在应该全部恢复正常了。
等了几分钟,看监控,果然都正常了。
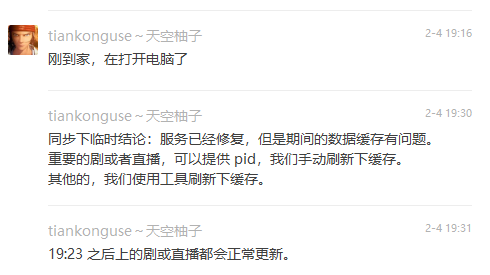
这个故障是缓存更新模块异常,所以数据已经写进来,只需要刷新缓存。
旧服务我负责的时候,我做了一个很有趣的功能。
大概是配一个时间戳,这个时间戳之前的数据强制当做缓存过期,进行强制回源。
另外为了防止一下回源量太大,强制回源还增加了秒级别的单机频控功能。
这个功能实现比较简单,但是非常有用。
四五年来线来,因为各种原因缓存数据有问题时,这个功能紧急救火了很多次。
新的缓存服务是另外一个同事重构的,问是否可以刷新下缓存。
回答刷缓存功能已经开发完了,但是后来有其他优先级更高的事情,就迟迟没有发布。
于是,只能临时想其他方法来刷新缓存。
可行的方案发现只有一个:根据写流水,导出更新的 id 列表,再次写入,触发数据更新。
由于是新想的方案,还需要去导数据、写代码、跑数据。
代码写完后跑数据的时候,那时晚上十点多,我才有空去吃晚饭。
等全部搞完的时候,已经是凌晨十二点多了。
之后,捞了下机器异常刚发生时候的错误日志,同事查阅了资料,发现是 zookeeper 整个集群在某个瞬间全部不可用了。
服务没有做重连操作,导致 zookeeper 全部不可用。
而之前的五六年里,这个事情重来没发生过。
于是,我也思考了下,分为下面几点。
1、缓存更新模块尽快重构。
这个服务在两年前就说要重构了,但是一直因为各种原因而迟迟没有重构。
现在其他服务全部重构了,找不到其他理由了,春节后,必须重构了(年前其实也讨论怎么重构)。
不然缓存通知模块随时可能还会爆发出其他未知问题,再次导致故障。
2、刷新缓存功能。
读服务尽快补上根据时间戳刷新缓存的功能。
写服务导流水刷缓存的功能,也需要补上,并可以尽量自动化,降低人工操作成本。
3、相信同事。
同事重启服务的时候,由于他不了解操作的服务,为了保险,他只重启一个机器来试探是否可以解决问题。
而我足够了解这些服务,回家打开电脑后,直接把所有服务的所有机器全部重启了。
我之所以敢这样操作也有两点原因。
第一,因为我足够了解这些服务,知道重启没有啥影响。
第二,认为即使重启引入新的问题,我在电脑前,现场去解决新问题就行了。
这里其实是足够相信自己。
如果我相信同事,让他们去大胆的重启所有服务,独自去面对可能出现的未知问题,那就可以大胆的让同事重启所有机器,从而更快的解决问题。
三、服务发现组件故障
春节的末期,很有规律的再次出现一个故障。
那天我还在睡觉,电话突然响了,接听后发现是服务失败率较高的电话告警。
看了眼微信群,发现不少人反馈我们的服务失败率很高。
于是边打开电脑,边回复正在解决问题。
结果发现这个问题比较简单。
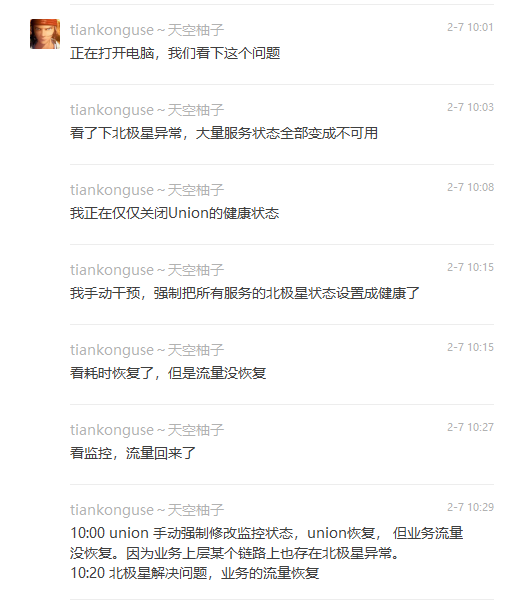
公司的基础设施服务发现组件异常,群里都在反馈各种服务都异常了。
具体是服务发现组件有个监控心跳的逻辑,这里心跳相关逻辑出问题了,把大部分机器判定为异常后不分发流量了,从而导致剩余的机器高负载了。
而解决方案很简单,手动关闭心跳检查,并把所有服务强制标记为健康即可。
所以这个问题我打开电脑,几分钟就解决问题了。
事后,思考这次故障该如何避免时,竟然没有发现好的解决方案。
基础设施有机房、物理机器、容器平台系统、监控系统、服务发现系统、日志系统等。
机房的物理机器面对光纤被挖断、城市断网断电等问题,可以通过多机房、多地部署来避免。
而剩余的系统,都是单点系统,一旦出故障就会影响公司的大量服务。
罗列的四个系统里面,监控系统与日志系统理论上应该归属旁路系统,故障不应该影响服务。
而容器平台与服务发现系统,一旦故障就是灾难性的。
面对这两个系统,你有什么好的解决方案来应对他们的故障吗?
四、最后
回去一个春节,连续出现三次故障,恰好又平均的分配在假期里,第一天一个故障、正中间一个故障、最后一天一个故障。
前两个故障属于系统内部的问题,也有点墨菲定律:认为可能会出问题最终确实发生了。
所以可以分别总结几点应对措施来。
而最后一个故障,就是黑天鹅事件了,完全无法预知。
加油,工程师。
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号:tiankonguse
公众号ID:tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
