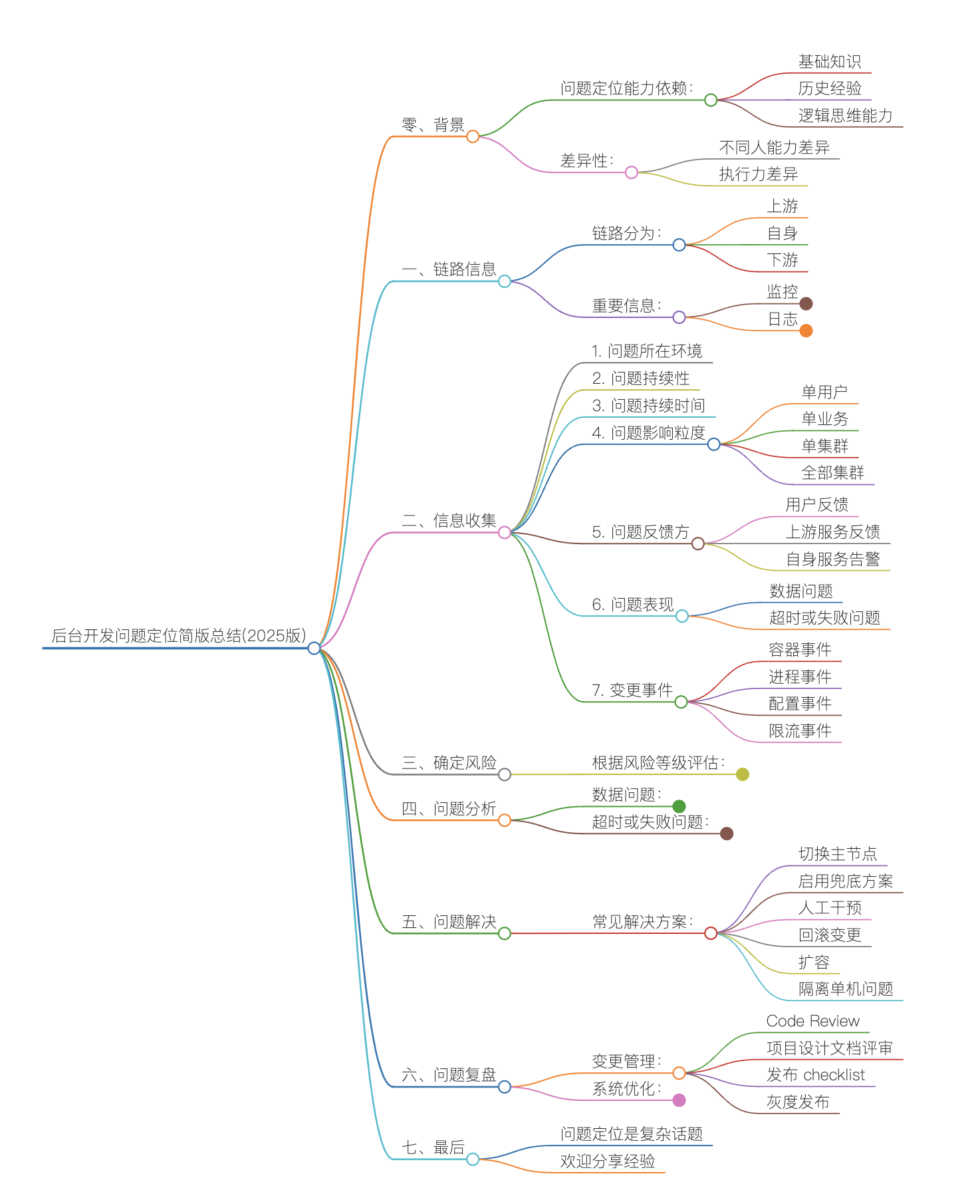
后台开发问题定位简版总结(2025版)
作者: | 更新日期:
后台开发问题比较复杂,简单总结下相关经验。
本文首发于公众号:天空的代码世界,微信号:tiankonguse
零、背景
做后台开发很多年了,期间处理过各种各样的问题。
有人问我一般是如何定位问题的,最近团队内恰好来了2个新成员,这里我就简单总结下相关经验。
问题定位能力,思考了下这个事情,其实挺复杂的。
首先,问题定位能力,是一个人能力的体现,不同人能力不一样。
这个能力很依赖个人的基础知识、历史经验、逻辑思维能力等,不同人差异很大。
其次,即使给出建议与资料,每个人执行力也不一样(根据近一年的管理经验看,大部分做不到),效果差异非常大。
所以这里我就屏蔽掉细节,从整体出发,来分析如何找到问题的根因。
一、链路信息
我们知道,一个问题的产生,可能是因为上游服务的问题,或者是下游服务的问题,或者是自身服务的问题。
问题定位,首先要需要理解链路的概念,即链路上各个服务之间的关系,以及各个服务具备的信息。
因此只有理解了链路的关系,才能高效的找到问题的根因。
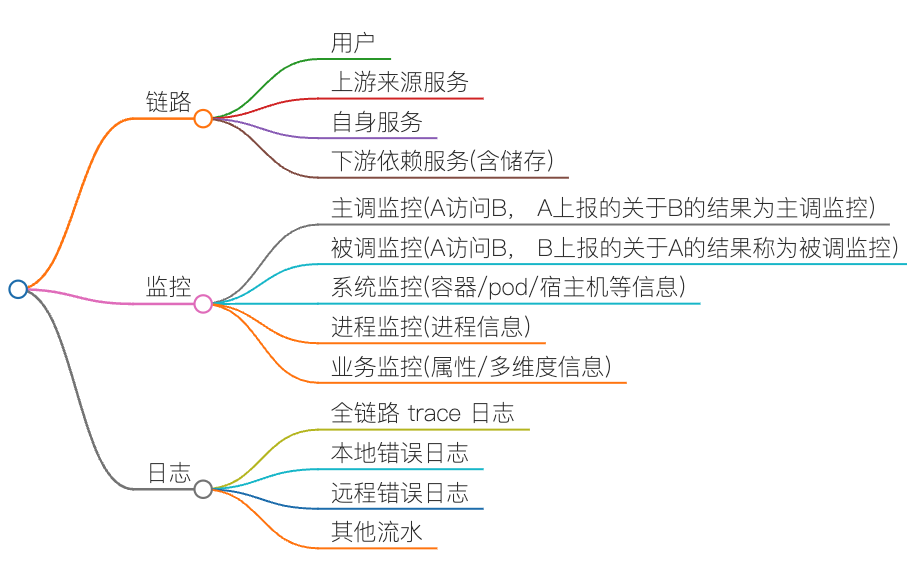
链路分为上游、自身、下游,但除了链路外,还有两个很重要的信息:监控与日志。
监控有主调监控、被调监控、系统监控、进程监控、业务监控等。
日志则有全链路trace、本地日志、远程错误日志、其他流水日志等。
使用思维导图看来,如下三大模块。
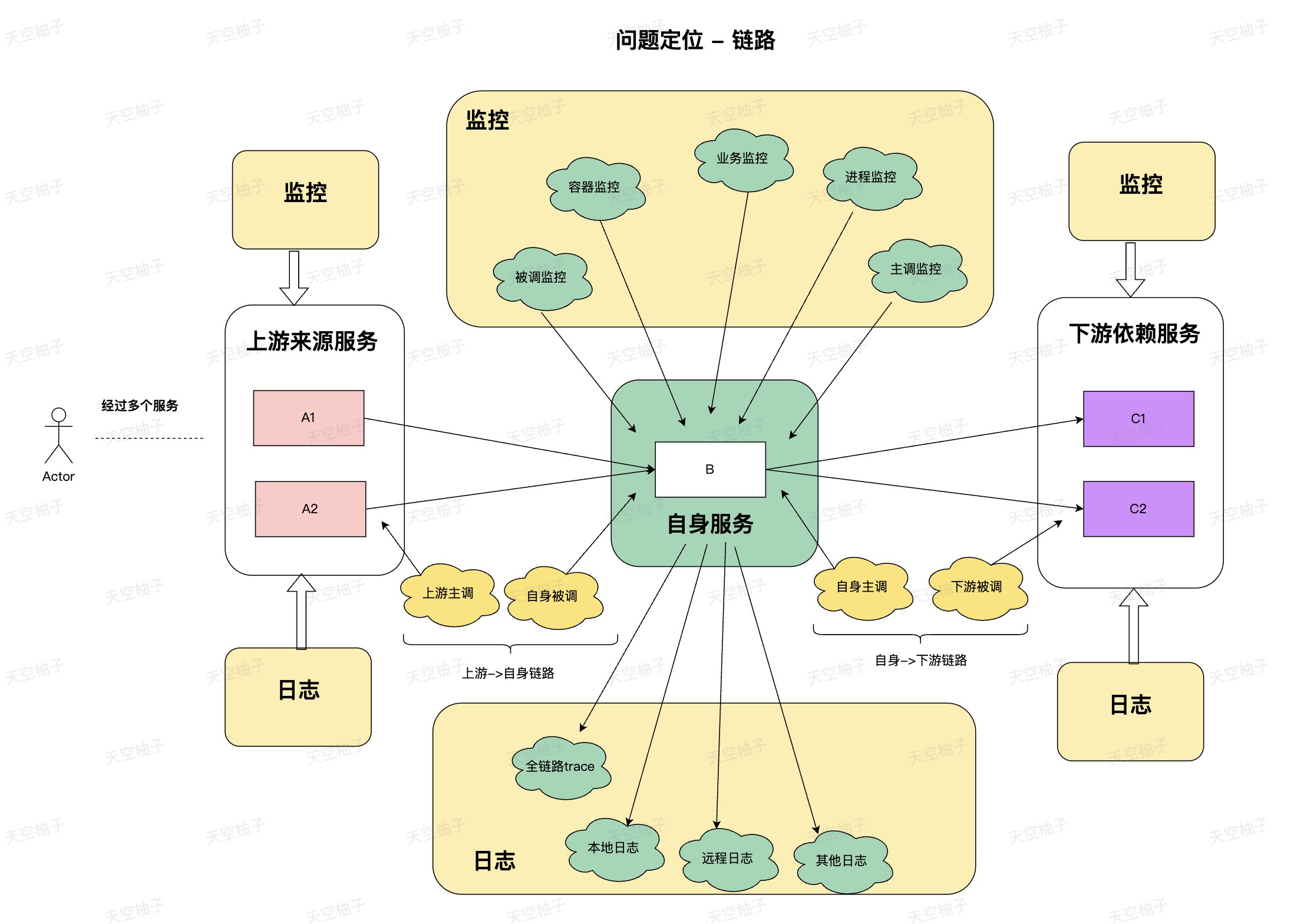
每个服务都有自己的链路、监控、日志,使用架构图的方式来看,如下
二、信息收集
收到一个问题反馈,信息收集是问题定位的第一步,我们需要收集相关信息,才能快速定位问题。
这里我列出了一些常见的信息,这些信息是我在实际工作中遇到过的,也可以根据自己的实际情况进行调整。
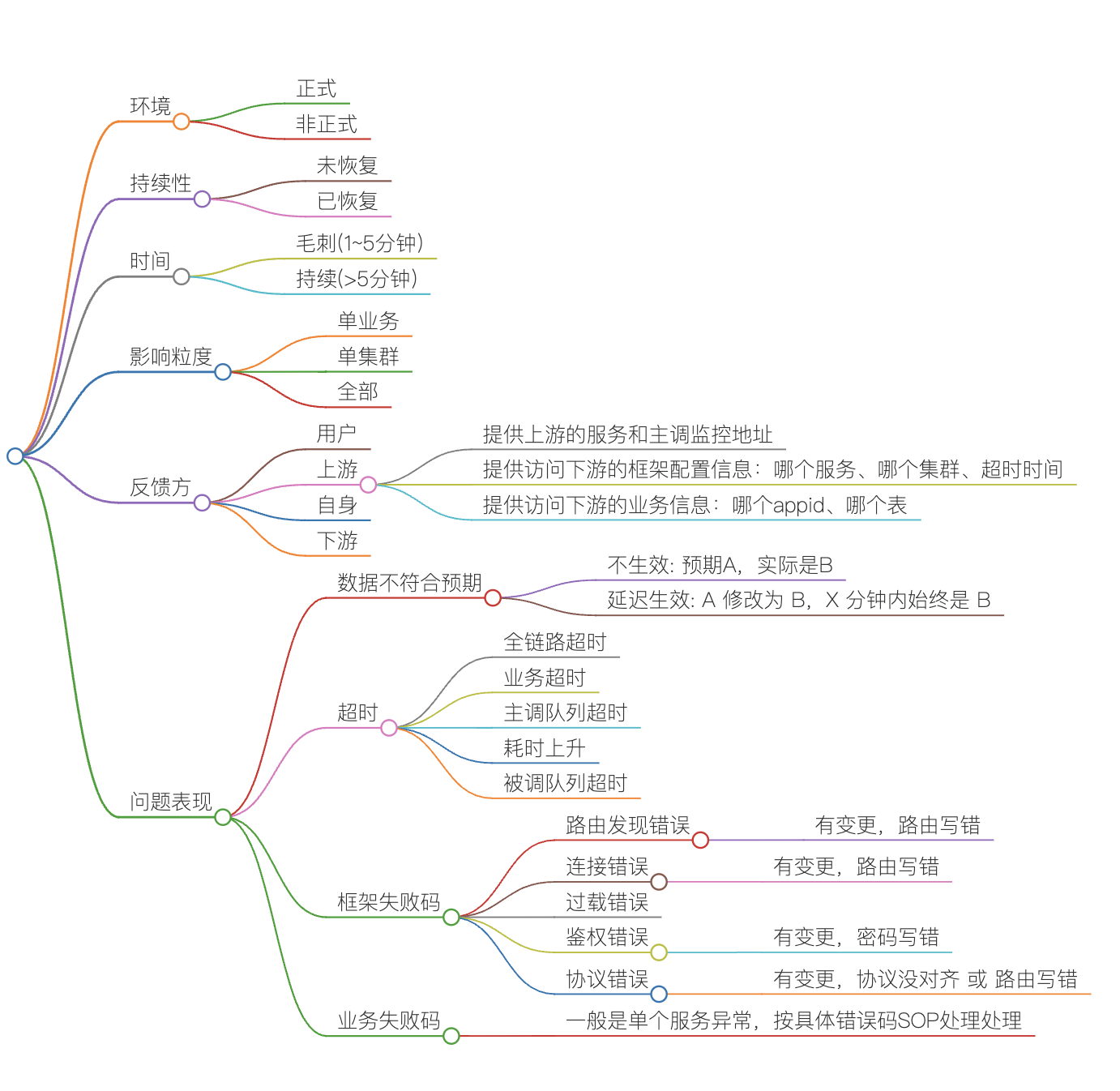
1、问题所在环境
这个非常重要,决定了问题的影响范围。
正式环境的问题,可能会影响到用户,而非正式环境的问题,可能只是影响到开发人员的联调体验。
2、问题持续性
如果已经恢复,那只需要后续排期投入人力分析原因即可。
比如当时大家不在电脑前,可以稍后再看原因。
如果持续存在,且问题验证的话,就需要立即去处理。
比如当时在吃饭,那就需要赶紧停止吃饭去处理问题。
如果当时在开会或者在外面,就需要找其他在电脑前面的同事帮忙协助处理。
3、问题持续时间
问题的持续时间,决定了问题的严重性。
如果只是几分钟内就恢复了,那影响范围就会比较小。
如果持续时间比较长,那影响的用户就会比较多,需要提高优先级来处理这个问题,还需要考虑是否需要发公告,以及准备简单的材料知会给老板。
4、问题影响粒度
这个与持续时间一样,是另一个决定问题严重性的因素,业界一半也称为问题的爆炸半径。
一般分为:单用户、单业务、单集群、全部集群。
5、问题反馈方
问题的反馈方,一般决定了问题涉及的链路。
如果是用户反馈问题,那涉及的链路可能会非常广,问题具体出在哪里需要具体问题具体分析。
如果反馈方是上游服务,那只需要关注上游服务,确认是上游的问题,还是自己服务的问题。
如果是自身服务的告警,则可能是我们自己的问题或者下游的问题。
这里重点需要关注的是上游反馈问题时,让上游第一时间提供尽量丰富的信息,比如上游的服务和监控地址、框架配置信息、业务信息等。
通过上游的服务监控信息以及我们的服务监控信息,可以让我们快速确认问题是上游的问题,还是我们的问题。
通过框架配置信息,可以确认上游的下游是不是我们,是不是找错人了。
而对于框架的集群信息以及业务信息,能辅助我们确认问题影响范围以及快速定位问题。
例如上游服务在我们的被调监控上看问题一致,但是其他服务没这个问题,那就是只影响着一个服务。
只影响一个服务时,一般就不是系统的问题,而是局部问题,比如这个业务请求特殊、配置特殊、读取特殊数据、依赖特殊下游等等。
6、问题表现
问题的表现,决定了问题的类型。
如果是数据错误或者更新延迟,那就是数据问题,需要确认数据是否有变更、数据是否有写入、数据是否有同步、数据是否有异常。
我们团队写了一个数据不一致的 SOP 文档,可以一步步来确认问题出在哪一个环节。
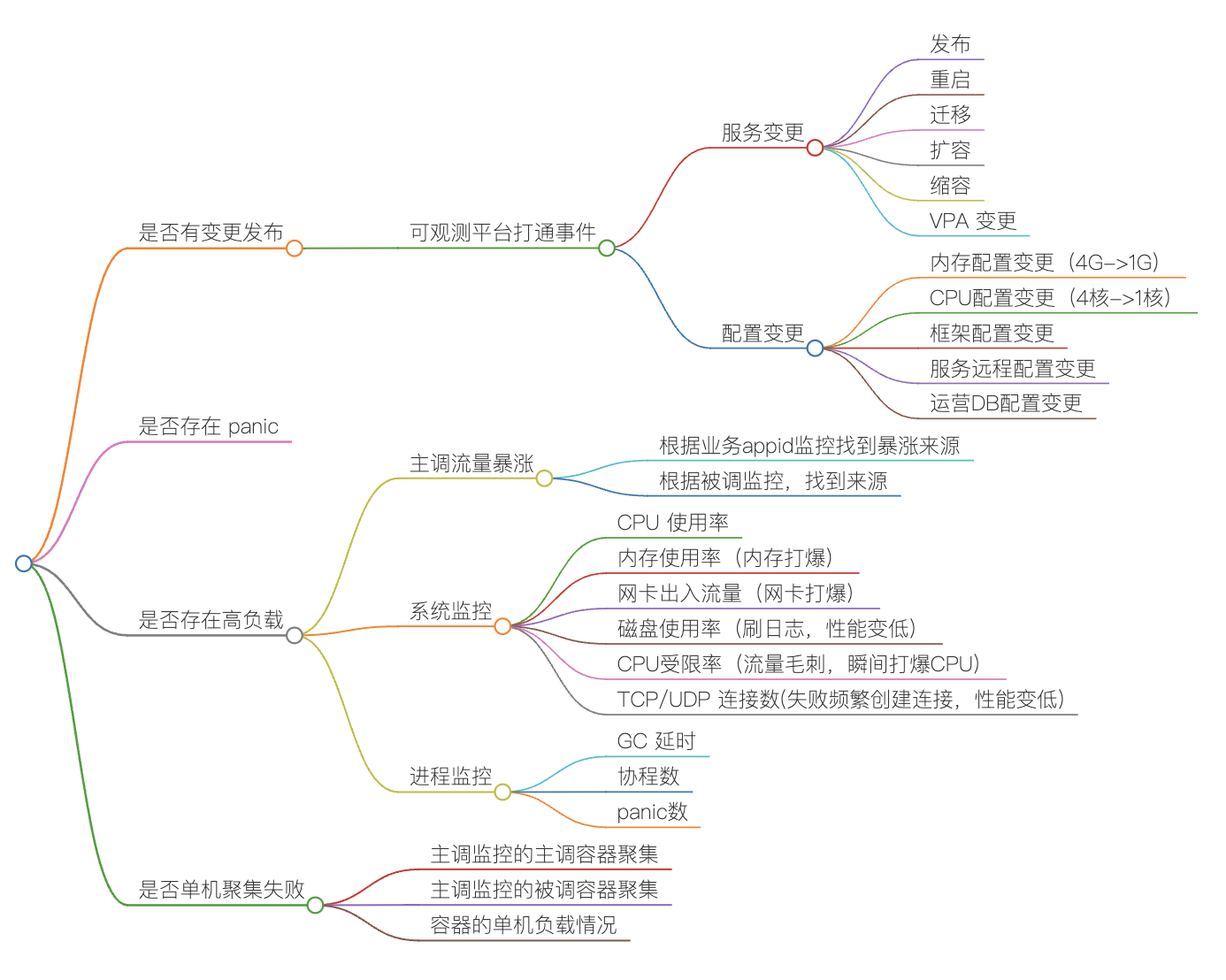
如果是超时或者失败,那就是框架问题,需要确认是否有变更、是否有 panic、是否有高负载、是否有其他问题。
总结来说,第一件事是看是否有变更发布。如果有变更,变更时间与问题发生时间是否一致或者接近。
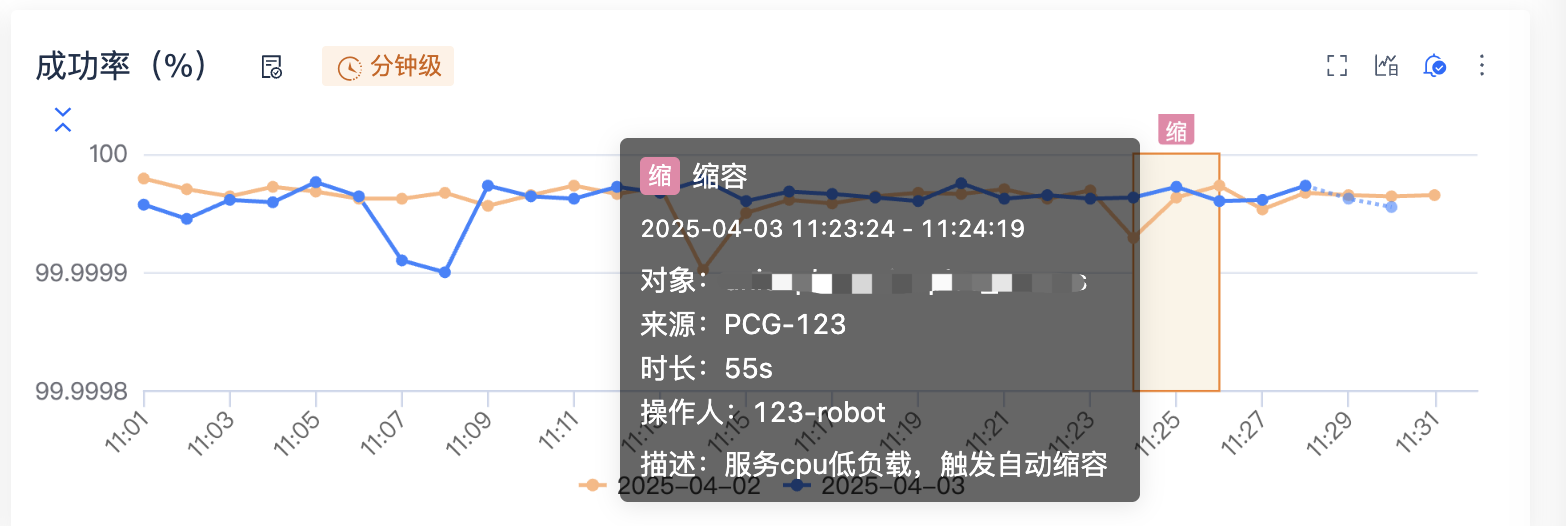
我们内部的监控系统已经把常见的事件都关联起来了。
目前至少包含下面的事件,我们也在不断的分析还有哪些事件可以加入进来。
容器事件:发布、扩容、缩容、迁移、删除、重建
进程事件:进程探活失败、重启、停止
配置事件:框架配置变更、服务配置变更(远程配置)、业务配置变更(DB配置)
限流时间:创建限流规则、更新限流规则
这是服务监控上的事件信息,看监控时就可以知道是否有变更发布。
另外每个服务也有一个总的事件中心,可以看一个服务的所有事件。
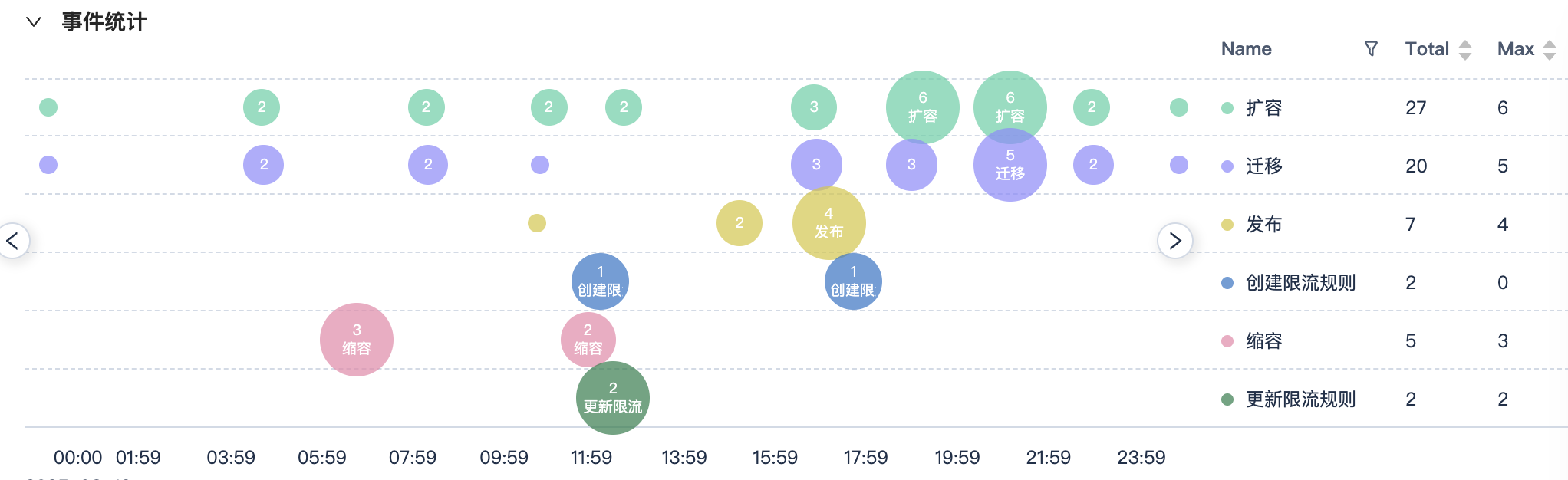
最后还有一个团队的总的时间中心,可以看到团队数所有服务的事件。
用于不知道谁变更时,通过这个团队看板,快速看到哪个服务变更了。
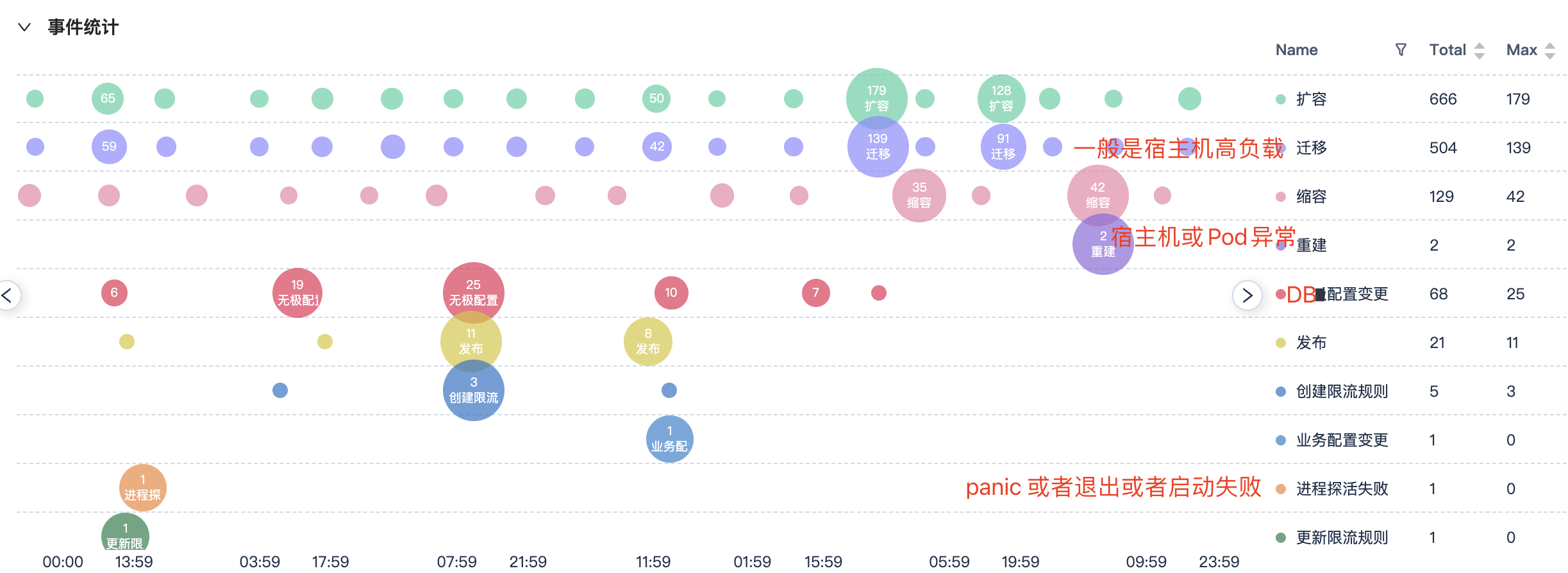
如果没有变更,就需要分析主被调监控、系统监控、进程监控、业务监控等,下面是具体的思维导图。
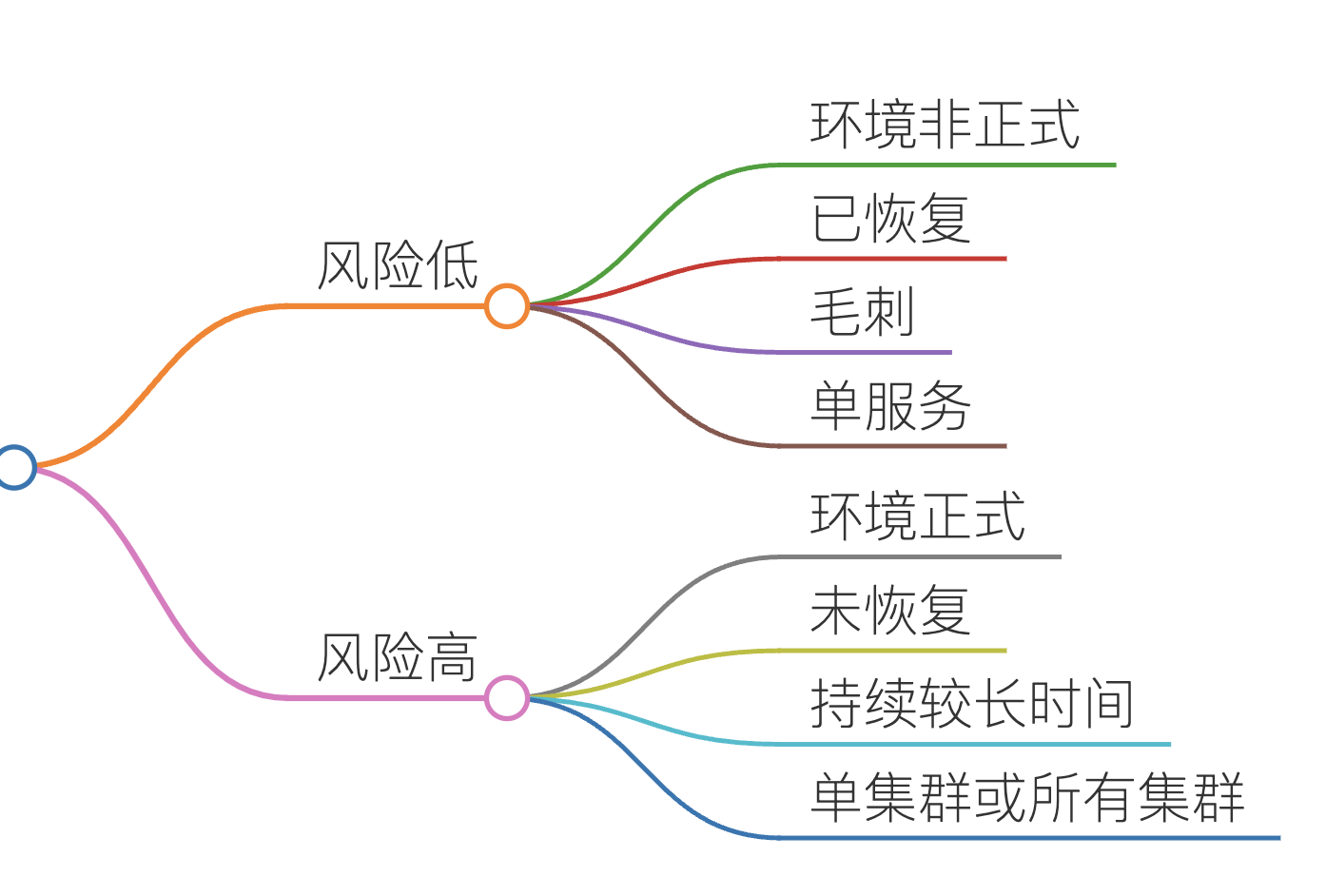
三、确定风险
是的,上面只是收集信息,并不需要去分析问题。
这样,使用最快的速度收集到想相关信息,就可以评估问题的风险了。
根据问题的风险等级,以及当前我们的实际情况,来决定是否需要处理这个问题。
四、问题分析
实际上,收集了上面的信息后,对于 99% 的问题,基本上就可以定位到问题了。
对于数据问题,一般分为符合预期或者不符合预期两种情况。
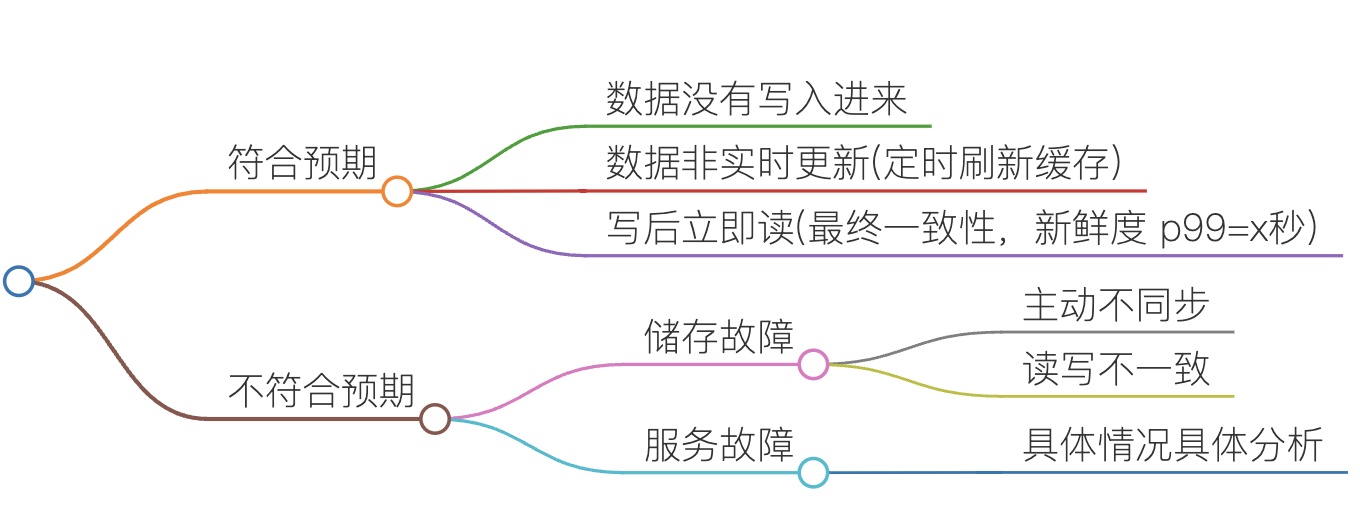
对于超时或失败场景,从用户侧开始,找到失败的最上游服务与最下游服务。
例如对于一个链路, A->B->C,可以监控可以分为下面四种情况。
1)A->B 的主调有失败
2)A->B 的被调有失败
3)B->C 的主调无失败
4)B->C 的被调无失败
A监控异常、B监控异常、C监控正常,大概率 B 服务出问题,小概率 A 或 C 服务出问题。
找到最下游异常服务后,就需要分析这个服务的监控信息,去确认异常原因了。
失败原因很多,常见的原因如下
五、问题解决
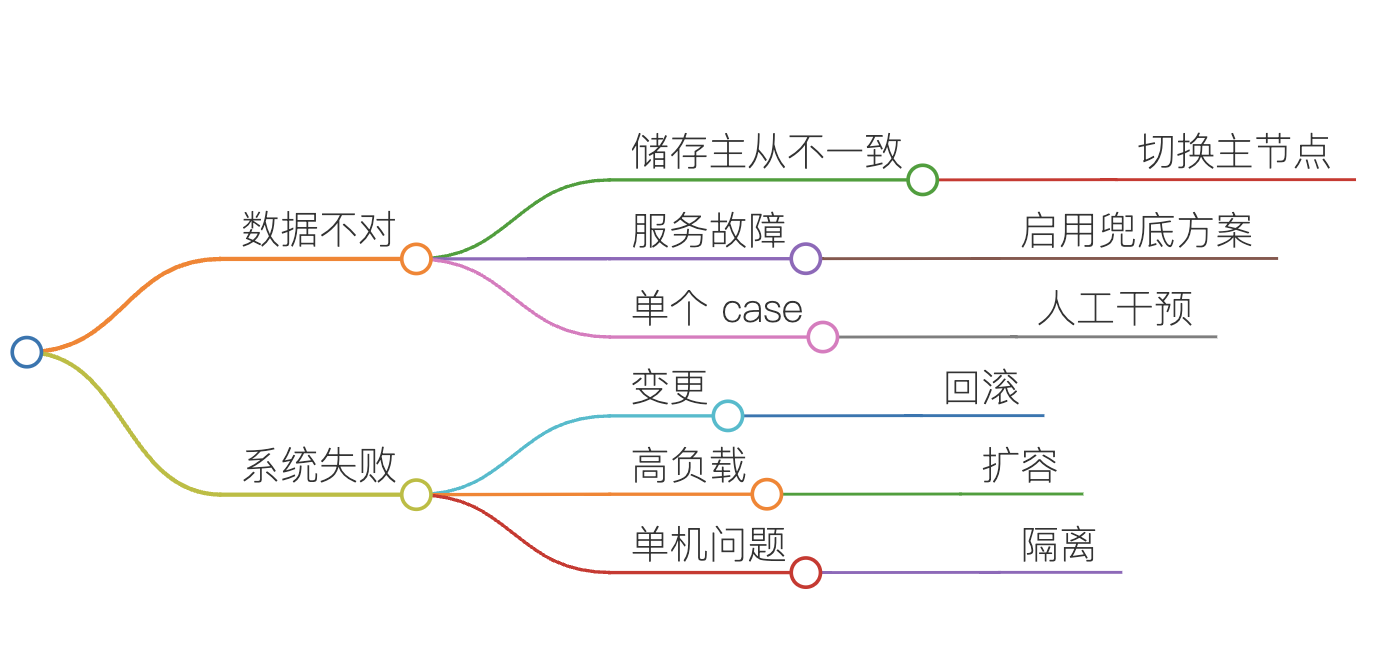
问题原因确定后,解决方案一般也就确定了。
储存主从不一致了,那就是切换主节点。
服务故障了,那就是启用兜底方案。
单个 case 了,那就是人工干预。
系统变更导致失败了,那就是马上进行回滚。
系统负载过高了,那就是扩容。
单机问题了,那就是隔离。
六、问题复盘
一般来说,问题解决后,还需要进行复盘,总结经验,缺陷改进,避免下次再出现同样的问题。
如果是变更导致的,就需要考虑加强变更的审核与测试验证。
不管是团队内,还是公司内,还是业界内,99% 的故障都是变更导致的,所以我会持续再在发布变更上加强管理,这块把控住了,也就可以避免 99% 的问题。
比如我们团队,我分为下面几点。
1)核心服务变更,我会去 code review 代码;旁路服务,我根据变更人的能力,评估是否亲自 review 代码。
2)核心服务变更较为复杂时,我会要求 Owner 写项目设计文档,评审后再启动。
3)所有服务发布,需要遵循团队 发布 checklist 文档,确保发布流程的一致性,避免某个环节遗漏,导致发布故障。
4)容器平台的发布相关权限收回,要求全部走公司发布系统进行灰度发布。
5)其他,如核心服务发布后接口测试,核心指标对比等,这里就不再展开了。
如果是系统缺陷,或者依赖方问题,那我会在问题解决后,思考如何优化系统,提高健壮性,避免下次再出现同样的问题。
七、最后
问题定位其实是一个很大的话题,这里只是简单的总结下相关经验,希望对大家有所帮助。
如果大家有更好的经验,欢迎留言分享。
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号: tiankonguse
公众号ID: tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
