CSP-J-山东 2022 第二轮比赛题解
作者: | 更新日期:
DFS、状压、AC自动机
本文首发于公众号:天空的代码世界,微信号:tiankonguse
零、背景
目前我已经做了历年 CSP-J/S 的所有常规算法题目,并分享了题型总结、备考策略、常见算法等。
CSP-J 题解:2025、2024、2023、2022、2021、2020、2019。
CSP-S 题解:2025、2024、2023、2022、2021、2020。
CSP-J 详细题解:2025
CSP-S 详细题解:2025
题型总结:CSP-J 题型分析、CSP-S 题型分析
备考策略:得分技巧、环境准备。
常见算法:二分、线段树、状态最短路、动态规划、数学、常见算法和数据结构。
难题多解:CSP-S 2025 C Trie 解法、CSP-S 2025 C 后缀数组解法
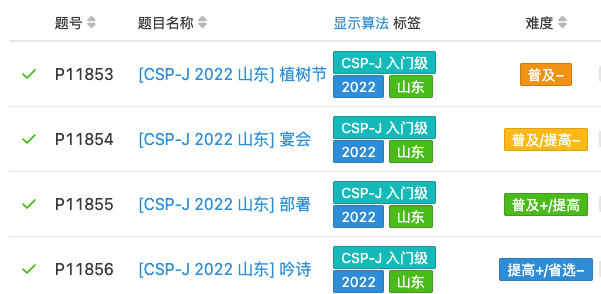
最近我在汇总历年 CSP-J/S 一等奖分数线时,发现部分省份在疫情那几年没有分数线。
搜索了一下,发现是因为疫情原因部分省份没有参与比赛。
不过,山东省后来补办了 2022 年的入门补赛,下面把题解整理分享给大家。
PS: 源码已上传到网盘,有需要的可以关注公众号,回复 CSP-2022 获取。
第一题,难度为普及 −,差分。
第二题,难度为普及/提高 −,枚举、贪心、二分、三分。
第三题,难度为普及+/提高,DFS。
第四题,难度为提高+/省选 −,状态压缩 或 AC 自动机。
一、植树节
题意:给一些区间,问区间内点被覆盖的最多次数。

算法 1:暴力区间加一。
复杂度:O(N*(B-A))。
得分:80 分。
算法 2:差分。
维护一个差分数组 diff[],对于每个区间 [l, r],执行 diff[l] += 1,diff[r + 1] -= 1。
最后对差分数组前缀和,得到每个点被覆盖的次数,取最大值即可。
时间复杂度 O(N + B)。
得分:100 分。
算法 3:线段树/树状数组。
如果不会差分,也可以树状数组、线段树等数据结构来进行区间操作。
时间复杂度 O(N log B)。
得分:100 分。
注:入门级第一题,这里不贴线段树的代码了。
二、宴会
题意:一个直线上有 n 个人居住,位置分别是整数 xi。
大家约定在一个点见面(允许小数),每个人出发前需要花费 ti 的时间来打扮。
问在哪个位置见面可以使得所有人到达的时间最早。
算法 1:枚举。
n 个人将坐标值划分为 n + 1 段区间 [L,R]。
区间确定后,区间左边的人都需要向右走,目标位置是 L,右边的人都需要向左走,目标位置是 R。
左边的人到达时间为 max(ti + (L - xi)),右边的人到达时间为 max(ti + (xi - R))。
公式里 L 和 R 是常数,可以提取出来,转化为 max(ti - xi) + L 和 max(ti + xi) - R。
每个位置的 max(ti - xi) 和 max(ti + xi) 可以提前线性的预处理出前缀最大值和后缀最大值。
从而在枚举时,可以 O(1) 计算出左右两边的最大值。
ti - xi 的物理含义是什么呢?
可以理解为把左边的人 xi 都向左移动 ti 个单位。
那么 max(ti - xi) 就是左边所有人移动后,最左边的位置。
ti + xi 的含义类似。
左右最远的位置都确定了,两个人速度一样都往中间走,那么相遇时间就是两个人距离的一半。
见面地点必须在 [L, R] 之间。
如果相遇时间在 L 前面,显然右边的人到达 L之后就不能再走了,需要等左边的人过来,消耗时间就是左边的max(ti - xi) + L。
如果相遇时间在 R 后面,类似,消耗时间就是右边的max(ti + xi) - R。
如果相遇时间在 [L, R] 之间,那么消耗时间就是两个人距离的一半。
// 目标点设置在 (i, i+1] 区间内
for (int i = 1; i < n; i++) {
double lv = nums[i].first, rv = nums[i + 1].first;
double leftMin = preMin[i], rightMax = sufMax[i + 1];
double mid = (rightMax + leftMin) / 2;
if (mid <= lv) { // 选择 left 最优
double tmpPos = lv;
double tmpTime = max(lv - leftMin, rightMax - lv);
UpdateAns(tmpPos, tmpTime);
} else if (mid >= rv) {
double tmpPos = rv;
double tmpTime = max(rv - leftMin, rightMax - rv);
UpdateAns(tmpPos, tmpTime);
} else {
double tmpPos = mid;
double tmpTime = max(mid - leftMin, rightMax - mid);
UpdateAns(tmpPos, tmpTime);
}
}
算法 2:二分
求最大的最小,经典的二分问题。
首先需要拆分最大最小的物理含义。
最大的含义指的是所有人到达某个目标地点的最大时间,这个时间来当做约会开始时间。
最小指的是在所有目标地点里,选择约会开始时间最小的那个位置。
所以这里需要二分开始约会的时间 T,来判断是否所有人都能到达。
对于每个人 i,他需要打扮时间 ti,所以他必须在 X = T - ti 时间内到达目标地点。
假设目标地点为 X,那么他能到达的范围是 [xi - X, xi + X]。
把所有人的可达范围求交集,如果交集不为空,那么说明存在一个目标地点 X,使得所有人都能在 T 时间内到达。
如果交集为空,那么说明不存在这样的目标地点 X。
最后,由于答案是求坐标位置,所以在交集不为空时,记录下交集的左端点即可。
auto Check = [&](ll mid) -> pair<bool, ll> {
ll leftMost = -1e10;
ll rightMost = 1e10;
for (auto [x, t] : nums) {
if (mid < t) return {false, 0};
ll leftBound = x - (mid - t);
ll rightBound = x + (mid - t);
leftMost = max(leftMost, leftBound);
rightMost = min(rightMost, rightBound);
if (leftMost > rightMost) {
return {false, 0};
}
}
return {true, leftMost};
};
算法 3:三分
约会开始的时间 T,满足单调性,一半都满足,一半都不满足,可以进行二分。
对于坐标位置 X,会发现不满足单调性。
两边无限远的坐标位置,消耗时间都很大。
中间某个位置消耗时间最小。
所以可以进行三分。
三分的核心是找到两个中间位置,通过比较这两个位置的消耗时间,把明显不是最优解的区间排除掉。
auto CalCost = [&](ll pos) {
ll res = 0;
for (int i = 1; i <= n; i++) {
res = max(res, abs(nums[i].first - pos) + nums[i].second);
}
return res;
};
ll l = 0, r = nums.back().first; // [l, r]
while (l < r) {
ll mid1 = l + (r - l) / 3;
ll mid2 = r - (r - l) / 3;
if (CalCost(mid1) <= CalCost(mid2)) {
r = mid2 - 1;
} else {
l = mid1 + 1;
}
}
算法 4:数学公式
目标是求 max(|xi - X| + ti) 的最小值。
|xi - X| 去掉绝对值,等价于 max(X - xi, xi - X)。
目标公式从而可以进行一系列的转换。
max(|xi - X| + ti)
= max(max(X - xi, xi - X) + ti)
= max(max(X - xi + ti, xi - X + ti))
= max((ti - xi) + X, (ti + xi) - X)
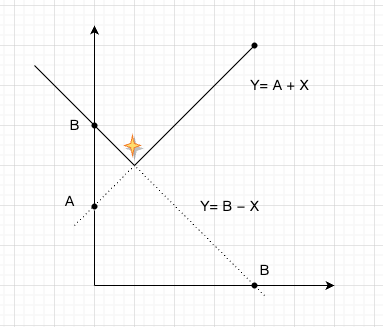
= max(A + X, B - X), 其中 A = max(ti - xi), B = max(ti + xi)
Y1 = A + X 是一个关于 X 的增函数,Y2 = B - X 是一个关于 X 的减函数。
如下图,Y1 函数是递增的,Y2 函数是递减的,目标是求两个函数的最小值,答案就是它们的交点。
解方程 A + X = B - X,得到 X = (B - A) / 2。
其中 A = max(ti - xi),B = max(ti + xi)。
ll A = LLONG_MIN;
ll B = LLONG_MIN;
for (int i = 0; i < n; i++) {
A = max(A, nums[i].second - nums[i].first);
B = max(B, nums[i].second + nums[i].first);
}
ll ans = (B - A) / 2;
0.5 的处理:
第一种方法是把所有坐标和时间都乘以 2,最后答案再除以 2。
第二种是需要除以 2 的时候,判断奇偶,奇数的话输出 .5,偶数的话输出整数。
ll BA = B - A;
if (BA % 2 == 1) {
printf("%lld.5\n", BA / 2);
} else {
printf("%lld\n", BA / 2);
}
第三种是直接使用浮点数,然后判断奇偶性。
double ansPos = Solver();
ll ans = ansPos * 2;
if (ans % 2 == 1) {
printf("%lld.5\n", ans / 2);
} else {
printf("%lld\n", ans / 2);
}
三、部署
题意:给一颗有根树,根节点为 1。
默认所有节点有一个初始值,代表节点的兵力。
只有两类操作:
第一类:给某个节点及其子树增加兵力值。
第二类:给某个节点及其相邻节点增加兵力值。
最后输出所有节点的兵力值。
算法 1:DFS
第一类操作,类似于线段树,先把值标记在子树的根节点上,当做懒标记。
最后所有批量操作完成后,进行一次 DFS,把懒标记下传到子节点上。
void Dfs(int u, int pre, ll addFlag) {
addFlag += subTreeFlag[u]; // 累加父路径上的懒标记
nums[u] += addFlag;
for (int v : g[u]) {
if (v == pre) continue;
Dfs(v, u, addFlag);
}
}
第二类操作也可以通过懒标记实现:先把值记录在对应节点上,最后再将这些标记累加到相邻节点上。
// 节点 u 及其相邻节点加 value
for (int u = 1; u <= n; u++) {
nums[u] += childFlag[u]; // 自身
for (int v : g[u]) { // 相邻节点
nums[v] += childFlag[u];
}
childFlag[u] = 0;
}
算法2:DFS 序,差分
之前我在《CSP-S 2025 第三题字典树 Trie 解法》文章中介绍了 DFS 序和差分的结合使用。
通过 DFS 序,可以把树上的子树操作转化为数组上的区间操作。
通过差分,可以把区间操作转化为点操作,最后求差分前缀和即可。
vector<ll> L, R, clockNo;
int dfsClock = 0;
vector<ll> diffArray;
void DfsOrder(int u = 1, int pre = -1) {
L[u] = ++dfsClock;
clockNo[dfsClock] = u;
for (int v : g[u]) {
if (v == pre) continue;
DfsOrder(v, u);
}
R[u] = dfsClock;
}
四、吟诗
题目:给一个长度为 N 的序列,值是 1~10,问有多少个序列满足存在一个三段的连续子序列,第一段和为 X,第二段和为 Y,第三段和为 Z。

前置分析:
很容易想到,使用动态规划来做。
状态定义:f(i, S) 表示前 i 个数尚未满足要求,后缀序列为 S 的方案数。
S 是前 i 个数的一个有效后缀序列。
有效后缀序列 S 分四种情况:
1)空
2)所有数之和小于 X
3)第一段和等于 X,第二段和小于 Y
4)第一段和等于 X,第二段和等于 Y,第三段和小于 Z
这样,对于每个状态 S0 ,枚举下一个数 c = a[i + 1]。
如果 S0 已经满足答案,那么后续位置可以任意填充,共 f(i, S0) * 10^(n-i-1) 种情况,应当计入答案。
否则,判断 S0 是否满足有效后缀序列。
满足了,得到新的状态 S1 = S0 + c。
不满足了,需要不断的尝试删除最左侧的数字,直到满足有效后缀序列为止,这个当做新的状态。
算法1:AC 自动机
前置分析中存在三种字符串匹配需求:
1)S0 + c 是否满足答案。
2)S0 + c 是否是有效后缀序列。
3)如果不合法,删除最左侧的数字,找到下个最长的有效后缀序列。
首先可以发现,有效后缀序列是答案的一个前缀。
所以可以把所有答案前缀构建成一个 Trie 树,叶子节点就是答案,非叶子节点是有效后缀序列。
对于操作3,求最长的有效后缀序列,就是求一个最长后缀,是答案的一个前缀。
这不就是 AC 自动机的失配指针吗?
所以,我们可以把所有答案前缀构建成一个 AC 自动机。
此时, S 就是 AC 自动机的一个状态节点。
unordered_map<ll, ll> q1, q2; // 双 Buffer
q1[trie.root] = 1;
ll ans = 0;
for (int i = 0; i < N; i++) {
q2.clear();
for (auto [u, cnt] : q1) {
for (int j = 1; j <= 10; j++) {
const char c = '0' + j;
ll v = trie.Query(u, c);
if (v == -1) { // 前缀全部无效
q2[trie.root] += cnt; // 不匹配,加入空集
} else if (v == 0) { // 匹配成功
ans += (cnt * pow10[N - 1 - i]) % MOD;
} else {
q2[v] += cnt; // 失败指针跳到下个状态
}
}
}
q2.swap(q1);
}
printf("%lld\n", ans);
算法2:状态压缩 DP
上一个算法中,状态 有效后缀序列 是一个字符串,我们压缩到 trie 中,从而使用整数来表示了。
还有一个比较 trick 的做法,是直接使用状态压缩 DP。
由于有效后缀序列存在重复的数字,没办法直接使用 bit 来表示每个数字。
但是,我们可以使用后缀和来表示这个序列,从而使得每个数字都变得唯一。
例如题目第一个样例,数字是 2 3 3,后缀和就是 8 6 3。
然后就可以把这个后缀和序列进行状态压缩了,如 S = 1<<(8-1) | 1<<(6-1) | 1<<(3-1)。
如果后面新来一个数字,例如 c=2,那么新的后缀和就是 10 8 5 2。
此时,只需要把 S 左移 c 位,就可以做到后缀和整体增加 c。
最后再加上 1<<(c-1) 即可。
怎么判断是否满足答案呢?
当满足答案时,后缀和序列中会存在 Z, Y+Z, X+Y+Z 三个数。
所以我们只需要判断 S 中是否包含这三个数对应的位即可。
ll MZ = 1 << (Z - 1);
ll MYZ = 1 << (Y + Z - 1);
ll MXYZ = 1 << (X + Y + Z - 1);
if ((v & MZ) && (v & MYZ) && (v & MXYZ)) {
ans += (cnt * pow10[N - 1 - i]) % MOD;
}
怎么找到下一个有效后缀序列呢?
实际上不需要显式寻找下一个后缀:只要在状态更新后用掩码限制位数(最多保留 X+Y+Z 位),就能把多余的前缀截掉,保持状态一致性。
ll MASK = (1 << (X + Y + Z)) - 1;
for (ll j = 1; j <= 10; j++) {
ll v = ((u << j) | (1 << (j - 1))) & MASK; // 集合加入数字 j
if ((v & MZ) && (v & MYZ) && (v & MXYZ)) {
ans += (cnt * pow10[N - 1 - i]) % MOD;
} else {
q2[v] = (q2[v] + cnt) % MOD;
}
}
这个方法很巧妙,把字符串匹配的问题转化为状态压缩 DP。
五、总结
本文分享了 CSP-J-山东 2022 第二轮比赛的全部题解。
可以看到,第四题还是比较难的,AC 自动机超纲了,但是状态压缩 DP 是一个比较巧妙的解法。
希望对大家有所帮助。
《完》
-EOF-
本文公众号:天空的代码世界
个人微信号:tiankonguse
公众号 ID:tiankonguse-code
本文首发于公众号:天空的代码世界,微信号:tiankonguse
如果你想留言,可以在微信里面关注公众号进行留言。
